贝叶斯网络的概念
把某个研究系统中涉及的随机变量,根据是否条件独立绘制在一个有向图中,就形成了贝叶斯网络。
贝叶斯网络(Bayesian network),又称信念网络(Belief Network),或有向无环图模型。是一种概率图模型,根据概率图的拓扑结构,考察一组随机变量X1,X2…XnX1,X2…Xn及其n组条件概率分布的性质。也就是说它用网络结构代表领域的基本因果知识。
贝叶斯网络的形式化定义
- BN(G,Θ)BN(G,Θ): 贝叶斯网络(Bayesian Network)
-
G:有向无环图 (Directed Acyclic Graphical model, DAG)
-
G的结点:随机变量X1,X2…XnX1,X2…Xn
-
G的边:结点间的有向依赖
-
Θ:所有条件概率分布的参数集合
-
结点X的条件概率: P(X|parent(X))P(X|parent(X))
P(S,C,B,X,D)=P(S)P(C∣S)P(B∣S)P(X∣C,S)P(D∣C,B)P(S,C,B,X,D)=P(S)P(C∣S)P(B∣S)P(X∣C,S)P(D∣C,B)
-
每个结点所需参数的个数:
若结点的parentparent数目是MM,结点和parentparent的可取值数目都是K:KM∗(K−1)K:KM∗(K−1)
一个简单的贝叶斯网络
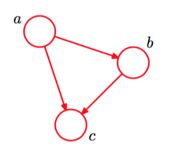
P(a,b,c)=P(c∣a,b)P(a,b)=P(c∣a,b)P(b∣a)P(a)P(a,b,c)=P(c∣a,b)P(a,b)=P(c∣a,b)P(b∣a)P(a)
全连接贝叶斯网络
每一对结点之间都有边连接
p(x1,…xn)=p(xK∣x1,…,xK−1)…p(x2∣x1)p(x1)p(x1,…xn)=p(xK∣x1,…,xK−1)…p(x2∣x1)p(x1)
P(X1=x1,…,Xn=xn)=∏ni=1P(Xi=xi∣Xi+1,…,Xn=xn)P(X1=x1,…,Xn=xn)=∏i=1nP(Xi=xi∣Xi+1,…,Xn=xn)
一个”正常“的贝叶斯网络
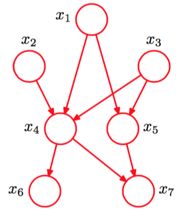
从图中我们可以看出:
-
有些边是缺失的
-
直观上来看:x1,x2x1,x2是相互独立的
-
直观上来看:x6,x7x6,x7在x4x4给定的条件下独立
-
x1,x2,…x7x1,x2,…x7的联合分布:
P(x1)P(x2)P(x3)P(x4∣x1,x2,x3)P(x5∣x1,x3)P(x6∣x4)P(x7∣x4,x5)P(x1)P(x2)P(x3)P(x4∣x1,x2,x3)P(x5∣x1,x3)P(x6∣x4)P(x7∣x4,x5)
贝叶斯网络的条件独立判定
我们来看一下贝叶斯网络的条件是如何判定的:
-
条件独立:tail-to-tail
根据图模型,得:P(a,b,c)=P(c)P(a∣c)P(b∣c)P(a,b,c)=P(c)P(a∣c)P(b∣c)
从而:P(a,b,c)/P(c)=P(a∣c)P(b∣c)P(a,b,c)/P(c)=P(a∣c)P(b∣c)
因为P(a,b∣c)=P(a,b,c)/P(c)P(a,b∣c)=P(a,b,c)/P(c)
得:P(a,b∣c)=P(a∣c)P(b∣c)P(a,b∣c)=P(a∣c)P(b∣c)
解释:在
c给定的条件下,因为a,b被阻断(blocked),因此是独立的:P(a,b∣c)=P(a∣c)P(b∣c)P(a,b∣c)=P(a∣c)P(b∣c) -
条件独立:head-to-tail
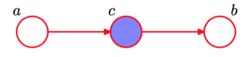
根据图模型,得:P(a,b,c)=P(a)P(c∣a)P(b∣c)P(a,b,c)=P(a)P(c∣a)P(b∣c)
P(a,b∣c)=P(a,b,c)/P(c)=P(a)P(c∣a)P(b∣c)/P(c)=P(a,c)P(b∣c)/P(c)=P(a∣c)P(b∣c)P(a,b∣c)=P(a,b,c)/P(c)=P(a)P(c∣a)P(b∣c)/P(c)=P(a,c)P(b∣c)/P(c)=P(a∣c)P(b∣c)
解释:在
c给定的条件下,因为a,b被阻断(blocked),因此是独立的:P(a,b∣c)=P(a∣c)P(b∣c)P(a,b∣c)=P(a∣c)P(b∣c) -
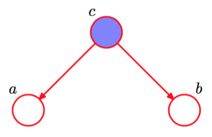
条件独立:head-to-head
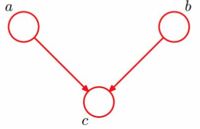
根据图模型,得:P(a,b,c)=P(a)P(b)P(c∣a,b)P(a,b,c)=P(a)P(b)P(c∣a,b)
由:∑cP(a,b,c)=∑nP(a)P(b)P(c∣a,b)∑cP(a,b,c)=∑nP(a)P(b)P(c∣a,b)
得:P(a,b)=P(a)P(b)P(a,b)=P(a)P(b)
解释:在
c给定的条件下,因为a,b被阻断(blocked),因此是独立的:P(a,b)=P(a)P(b)P(a,b)=P(a)P(b)
有向分离
对于任意的结点集, 有向分离(D-separation): 对于任意的结点集A,B,C,考察所有通过A中任意结点到B中任意结点的路径,若要求A,B条件独立,则需要所有的路径都被阻断(blocked),即满足下列两个前提之一:
- A和B的
head-to-tail型和tail-to-tail型路径都通过C; - A和B的
head-to-head型路径不通过C以及C的子孙结点;
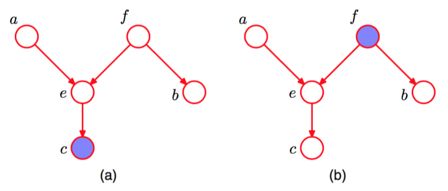
图(a), 在tail-to-tail中, f没有阻断; 在head-to-head中, e阻断, 然而它的子结点c没有阻断, 即e所在的结点集没有阻断; 因此, 结点a, b关于c不独立.
图(b), 在tail-to-tail中, f阻断; 因此, 结点a,b关于f 独立. 在head-to-head中, e和它的子孙结点c都阻断; 因此, 结点a,b关于e独立.
特殊的贝叶斯网络
-
马尔科夫模型

结点形成一条链式网络,这种按顺次演变的随机过程模型就称作马尔科夫模型
Ai+1Ai+1只与AiAi有关,与A1,…,Ai−1A1,…,Ai−1无关。
-
隐马尔科夫模型
Hidden Markov Model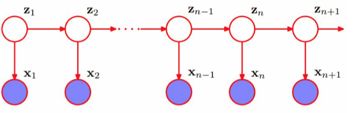
- 隐马尔科夫模型(HMM)可用标注问题,在语音识别、NLP、生物信息、模式识别等领域别实践证明的有效算法。
- HMM是关于时序的概率模型,描述由一个隐藏的马尔可夫链随机生成不可观测的状态随机序列,再由各个状态生成一个观测而产生观测随机序列的过程。
- HMM随机生成的状态的序列,成为
状态序列,每个状态生成一个观测,由此产生的观测随机序列,称为观测序列- 序列的每一个位置可看做是一个时刻。
- 空间序列也可以使用该模型.
-
马尔科夫毯
一个结点的**
Markov Blanket**是一个集合,在这个集合中的结点都给定条件下,该结点条件独立于其他结点。**
Markov Blanket**: 一个结点的Markov Blanket是它的parents,children以及spouses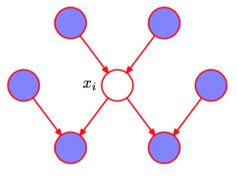
深色的结点集合,就是“马尔科夫毯”(**
Markov Blanket**)