用Python实现一个面向主题的网络爬虫程序,并完成以下内容:
(注:每人一题,主题内容自选,所有设计内容与源代码需提交到博客园平台)
一、主题式网络爬虫设计方案(15分)
1.主题式网络爬虫名称
新浪网汽车类新闻爬虫词云分析 (结巴分词)
2.主题式网络爬虫爬取的内容与数据特征分析
新浪网新闻汽车类栏目爬虫+文本分析(结巴+词云)
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
本次设计方案主要依靠BeautifulSoup库对新浪网访问并采集,最后以txt格式将数据保存在本地。
技术难点主要包括对页面的分析、对数据的采集和对数据的持久化操作。
实现思路:
(1)利用requests请求网页并爬取目标页面
(2)利用BeautifulSoup解析网页同时获取文件名及目标url链接
二、主题页面的结构特征分析(15分)
1.主题页面的结构特征
打开新浪网页,通过右击鼠-标查看网页源代码,找到对应要爬取的信息
https://auto.sina.com.cn/包含了汽车的车型、报价、新车、导购等信息。




2.Htmls页面解析
使用BeautifulSoup进行网页页面解析,通过观察发现我想要获取的内容是在“div”标签下的“a”标签中。
 车辆报价
车辆报价
 车型名和图片链接
车型名和图片链接 车型信息所在
车型信息所在


3.节点(标签)查找方法与遍历方法
(必要时画出节点树结构)
查找方法:findAll
遍历方法:for循环
三、网络爬虫程序设计(60分)
爬虫程序主体要包括以下各部分,要附源代码及较详细注释,并在每部分程序后面提供输出结果的截图
车型
1.数据爬取与采集,爬取网页源码,收集于主题车型有关的所有源码,这是分了57次获取的。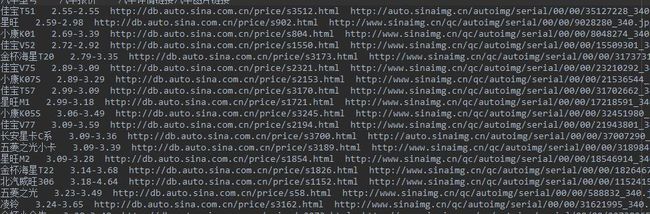

2.对数据进行清洗和处理,运行beautifulsoup进行数据筛选,将筛选结果进行汇总方便绘图

车型,
3.文本分析(可选):jieba分词、wordcloud可视化
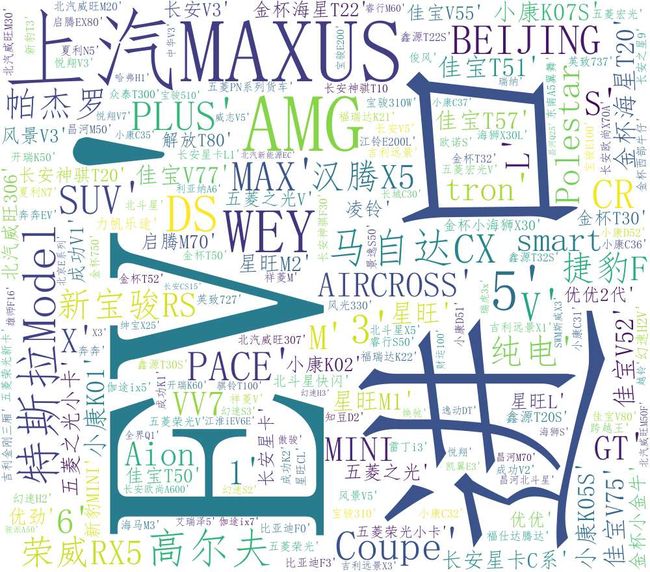


4.数据分析与可视化
(例如:数据柱形图、直方图、散点图、盒图、分布图、数据回归分析等)

5.数据持久化

6.附完整程序代码
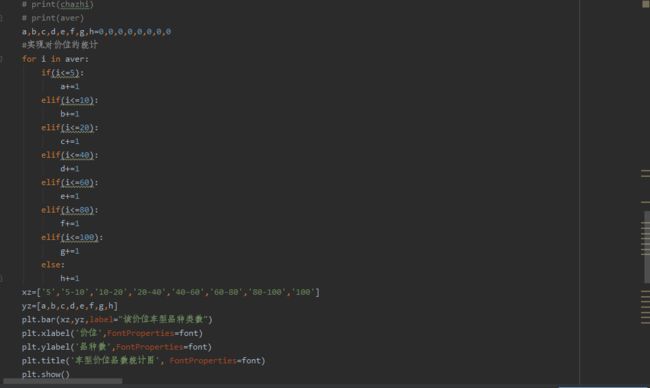
#coding=utf-8 import requests from bs4 import BeautifulSoup from wordcloud import WordCloud from matplotlib.font_manager import FontProperties import jieba import matplotlib.pyplot as plt import numpy as np #爬虫伪装, headers={ 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36', 'Cookie': 'SUB=_2AkMqgoi-f8NxqwJRmfwWy27gboVwzArEieKc3nllJRMyHRl-yD83qmkLtRB6AQKmUbe3EvXvkPvhB8j4NNOkiuqAkrbh; SUBP=0033WrSXqPxfM72-Ws9jqgMF55529P9D9W59zVChNmzhgQHdIdFjzeuw; SINAGLOBAL=222.88.152.96_1574941865.648177; UOR=,auto.sina.com.cn,; lxlrttp=1572512346; UM_distinctid=16ecf2fdd1d845-04981aa5b39583-2393f61-100200-16ecf2fdd1ea0b; __gads=Test; U_TRS1=00000064.41862768.5de73754.a2dfddc3; Hm_lvt_6d8bdbc8773f4a06e96778d7de5526c7=1575434070; historyNum=%2C3512; Apache=61.163.218.33_1575448969.442194; Hm_lvt_f31b3bde5ef6233a36928514fb59f9cd=1575434218,1575434419,1575448971; ULV=1575449008662:3:3:3:61.163.218.33_1575448969.442194:1575448970325; Hm_lpvt_f31b3bde5ef6233a36928514fb59f9cd=1575449009' } def get_html(n): url='http://db.auto.sina.com.cn/list-0-0-0-0-0-0-0-0-9-0-{}.html'.format(n) txt=requests.get(url).text.replace("\xa9",'').replace('\xa0','') bs=BeautifulSoup(txt,'html.parser') print('成功获取新浪汽车车型第{}页源码'.format(n)) return bs #创建四个列表实现对爬取数据的存储,同时为数据的可视化服务 img_list=[] car_name_list=[] car_url_list=[] car_price_list=[] #对获取的网页源码进行信息提取 def get_data(): #依次获得57个页面 for i in range(1,58): bs=get_html(i) #提取该页面中汽车图片url for img in bs.find_all('img')[0:24]: img_list.append(img['src']) #提取该页面中车型,报价,和url for ui in bs.find_all('p',attrs={'class':'price'}): car_name=ui.find_all('a')[0]['title'].replace('报价','') #获取汽车名 car_url=ui.find_all('a')[0]['href'] #获取汽车详细信息网页 car_price=ui.find_all('em',text=True)[0].text #获取车辆得报价 car_url='http:'+car_url car_url_list.append(car_url) #汽车详细数据链接 car_name_list.append(car_name) #汽车型号 car_price_list.append(car_price) #汽车报价范围 #制作词云 def get_cloud(): wordcloud=WordCloud(font_path="C:/Windows/Fonts/simfang.ttf",background_color="white",width=1000,height=880).generate(str(car_name_list)) #生成字符串 image_produce = wordcloud.to_image() image_produce.show() #展示生成的云图, wordcloud.to_file('汽车型号词云.png') #保存词云 print('词云生成完毕') #将爬取的汽车信息写进文件 def get_file(): with open("新浪汽车型号类信息",'a+',encoding='utf-8') as f: #制作文件表头 f1='汽车型号'+' '+'汽车报价'+' '+'汽车详情链接'+'汽车图片链接'+'\n' f.write(f1) for i in range(len(car_name_list)): #按行写入汽车信息 car_info=car_name_list[i]+' '+car_price_list[i]+' '+car_url_list[i]+' '+img_list[i]+'\n' f.write(car_info) f.close() print('数据写入完成') def get_figure(): '''1.绘制直方图统计各个价位段的车型数目 2.绘制散点图,每个点取最高价位与最低价位的平均数 3.绘制差值散点图''' #对价格数据进行处理 chazhi=[] aver=[] font = FontProperties(fname=r"C:\Windows\Fonts\simhei.ttf", size=14) for num in car_price_list: num=num.split('-') try: chazhi.append(float(num[1])-float(num[0])) #价位差 aver.append((float(num[0])+float(num[1]))/2) #品均价位 except: pass #按照价位绘制直方图 # print(chazhi) # print(aver) a,b,c,d,e,f,g,h=0,0,0,0,0,0,0,0 #实现对价位的统计 for i in aver: if(i<=5): a+=1 elif(i<=10): b+=1 elif(i<=20): c+=1 elif(i<=40): d+=1 elif(i<=60): e+=1 elif(i<=80): f+=1 elif(i<=100): g+=1 else: h+=1 xz=['5','5-10','10-20','20-40','40-60','60-80','80-100','100'] yz=[a,b,c,d,e,f,g,h] plt.bar(xz,yz,label="该价位车型品种类数") plt.xlabel('价位',FontProperties=font) plt.ylabel('品种数',FontProperties=font) plt.title('车型价位品数统计图', FontProperties=font) plt.show() a,b,c,d,e,f,g,h=0,0,0,0,0,0,0,0 for i in chazhi: if(i<1): a+=1 elif(i<2): b+=1 elif(i<4): c+=1 elif(i<6): d+=1 elif(i<8): e+=1 elif(i<10): f+=1 elif(i<12): g+=1 else: h+=1 x=['0.7','1','1.5','2','2.5','3','3.5','10'] y=[a,b,c,d,e,f,g,h] plt.bar(x,y,label="该价位车型品种类数") plt.xlabel('价格差',FontProperties=font) plt.ylabel('品种数',FontProperties=font) plt.title('车型价位品数统计图', FontProperties=font) plt.show() if __name__=='__main__': get_data() get_cloud() get_file() get_figure()
四、结论(10分)
1.经过对主题数据的分析与可视化,可以得到哪些结论?
通过对主体数据的提取分析,可以清楚地知道车型以及价位,
价位偏适中的,车型品种数量越多,价位过高或过低的,车型品种数量相对减少
价格差适中的,车型品种数量越多,价格差过高或者过低的,车型品种数量相对减少
2.对本次程序设计任务完成的情况做一个简单的小结。
经过这次的学习与作业实践,学到了很多爬虫的知识,不过还是远远不够的。
发现数据可视化和数据清洗真的很重要,对python的兴趣更加浓厚了。
通过这次任务,基本实现使用python把想要的数据爬取下来并且保存在本地,要自己慢慢分析页面结构,一步步的自己操作和平时上课不一样。