引言
在使用Python的时候,最令人崩溃,同时也是最常见的错误信息之一,就是处理字符串时出现的UnicodeError,包括两个子异常类型UnicodeEncodeError和UnicodeDecodeError。遇到这一类问题时,包括我在内的大多数人的第一解决方案大概就是Google一下错误信息,然后逐个试一试Stackoverflow中给出的各个方法。往往是这里加了一些encode和decode方法,那里加一些encode和decode方法,看看能不能处理掉这个错误。这样往往无法完全解决这一类错误。造成的结果就是关于unicode,唯一确定的事实是:我们讨厌unicode!
要想优雅地解决这一类问题,我们首先要知道,python中的unicode和str究竟是些什么东西。
究竟什么是unicode?
我们知道,计算机事实上处理的是一系列由0和1构成的二进制信息流。那么当我们想要处理字符或者蚊子的时候怎么办呢?
1968年,美国标准信息交换码(The American Standard Code for Information Interchange),也就是我们熟知的ASCII式作为一种标准码点格式诞生了。ASCII事实上就是把一系列常用的字符与一系列数字码点(code point)(从0到127)对应了起来。比如小写的'a'就表示为97,也就是二进制0110001。由于ASCII由美国人制定,只考虑到了英语字符,所以无法表示其他语言中的字符,比如法语中的ç。
到了19世纪80年代,大多数的个人电脑已经是8-bit的了,所以又有一些新的码点格式尝试使用0-255之间的数字来表示更多的字符。比如ISO Latin 1,或说ISO8859-1,就是由ASCII码点外加96个新字符构成的。
255个字符显然还是无法满足所有语言的需求,比如中文中就有远远多于这个数目的汉字。在这一时期,出于试图解决这一问题的努力,unicode标准开始被逐步建立。
Unicode开始尝试使用16-bit,也就是2 bytes来表示字符,也就是共计可表示2^16=65536个字符,比如GB2312,Shift-JIS等码点格式。但这还是无法满足所有语言的要求。现代的unicode大大扩展了范围,使用0到1,113,111(0x10ffff)来表示字符。需要指出的一点是,为了保持向后兼容性,现代的编码格式前127位的编码仍然与ASCII相同。
一个unicode码点由一个U+前缀加上4,5,或6个16进制数字构成。并且每一个unicode字符都有一个独一无二的大写ASCII字符全名。例如U+00F8表示LATIN SMALL LETTER O WITH STROPE:ø。
文件/网络IO时使用的byte流
虽然有了码点(code point),但对计算机而言,其处理的数据还是一系列byte流,不论是读取写入文件,还是进行网络信息传输都是如此。编码(encode)和解码(decode)的问题这时就开始出现了。因为一系列byte流本身是无意义的,也无法被人类看懂。我们只有使用给定的编码标准解码(decode)了这一系列byte流之后才能得到有意义的码点,也就是信息。比如对于byte 97,其本身是没有任何意义的。只有根据ASCII,我们才知道这是a对应的编码的码点。所以对于任何byte流,只有事先知道其对应的编码格式,我们才能根据其得出有意义的信息。然而编码格式并不能被byte流所记录,所以只有通过事先规定我们才能正确解码一系列byte流。
而处理unicode码点与bytes之间的映射关系的标准就是我们现在熟知的UTF-8,UTF-16,UTF-32等格式。因为计算机只能处理bytes,所以在进行文件IO,网络IO的时候,我们还是需要使用bytes。
Unicode标准定义了一系列编码标准用来将unicode编码为bytes用以计算机的存储和传输。
其中UTF-8是最常用的一个。对于每一个码点,UTF-8在编码时用长度不同的一系列bytes来表示它们。码点本身的值越大,编码时所需的bytes数目就越多。ASCII字符用一个byte表示,与ASCII本身编码相同。因此我们可以说ASCII是UTF-8的一个子集。
Python2
讨论怎么处理Python2中的bytes与unicode之前,我们首先应该明确Python2中文字相关的两种类型。
- (str)[http://docs.python.org/library/functions.html#str]是Python2中表示由bytes序列的字符串。也就是我们上文说的bytes流。
- unicode是用来表示unicode码点序列的字符串。
如果使用最常见的双引号定义字符串直接量,我们将会得到一个str对象,其中存储的是bytes。如果我们在双引号前加"u"前缀定义字符串直接量,则会得到一个unicode对象。在这个unicode字符串直接量中,我们可以插入任意\u开头的unicode码点。如下面的例子所示。
>>> str_seq = 'Hello World!'
>>> type(str_seq)
>>> unicode_seq = u'Hello World! \u00f8'
>>> type(unicode_seq)
>>> print(unicode_seq)
Hello World! ø
注意我们此处使用的字符串这个词语。这里的字符串和Java中的字符串代表非常不同的含义。此处的字符串代表对应于str类的byte字符串或者对应于unicode类的unicode码点字符串。
.encode()方法和.decode()方法
处理UnicodeEncodeError和UnicodeDecodeError的重中之重是理解.encode()和decode()方法。这两个方法各自的含义及调用的主体如下所示:
unicode.encode() -> bytes:只有对于unicode对象我们才应该使用
.encode()方法。这一方法用来将一系列unicode编码为bytes流。
bytes.decode() -> unicode: 只有对于bytes,或说Python2中的str对象,我们才应该调用.decode()方法。这一方法将一系列bytes流解码为原本的unicode码点。
encode和decode方法均可接收encoding与errors两个参数,分别用来指定编码/解码格式以及出现编码/解码错误的时候该方法如何反应。
需要注意的是,编码/解码前后字符串的长度(len()方法的返回值)有可能是不同的,因为二者长度的意义不同。对于unicode来说,长度为其中字符(码点)的数目,而str的长度则为其中bytes的数目(因为对str来说并没有字符的概念)。所以一旦某个unicode字符被编码为超过一个byte的长度,二者的长度就会不同。
如下面例子所示。
>>> unicode_seq = u'Hello World! \u00f8'
>>> len(unicode_seq)
14
>>> utf8_encoded_bytes = unicode_seq.encode('utf-8')
>>> type(utf8_encoded_bytes)
>>> len(utf8_encoded_bytes)
15
>>> unicode_seq
u'Hello World! \xf8'
#此处的\xf8即为\u00f8,二者为同一个码点,只是省略了开头的0
>>> utf8_encoded_bytes
'Hello World! \xc3\xb8'
>>> utf8_encoded_bytes.decode('utf-8')
u'Hello World! \xf8'
从这个例子中我们看出\u00f8这个unicode码点被编码为了两个bytes\xc3\xb8,从而导致了bytes字符串和unicode字符串的长度差异。encode()的过程将我们的unicode字符串“翻译”成了一系列bytes,在Python2中表现为str类型的对象。而decode()过程则相反,将bytes字符串“翻译”为我们原有的unicode字符串。
Encoding Errors!
那么接下来我们就要处理臭名昭著的编码错误了。虽然从上文来看,.encode()和.decode()方法如果使用正确,能够优雅地将我们的文字信息正常转换,但由于真实的数据往往是迥异的,且bytes流并不保留编码格式的信息,所以除非我们事先知道一段bytes的编码格式,或者“恰好”在正确的时间和地点使用了相应的encode和decode方法,程序往往会在意想不到的地方抛出Encoding异常。
比如使用错误的编码格式对一个unicode对象调用了encode方法。这往往是由于指定的编码格式不足以编码指定unicode字符串中的某些字符导致的。例如如果我们尝试使用ASCII编码上述含有ø的字符串,由于ascii并不能表示这个字符,所以导致UnicodeEncodeError。错误信息中包含所试图使用的编码:ascii;无法编码的字符:u'\xf8',以及这个字符的位置。错误信息中的codec是coder/decoder的简称。
>>> unicode_seq.encode('ascii')
Traceback (most recent call last):
File "", line 1, in
UnicodeEncodeError: 'ascii' codec can't encode character u'\xf8' in position 13: ordinal not in range(128)
Decoding Errors!
类似于EncodingError,如果我们使用了与编码格式不同的格式去解码一个bytes字符串,则会得到UnicodeDecodeError。
比如我们试图使用ASCII解码使用UTF-8编码的bytes字符串,则会得到Decode Error。这个解码异常与上文的编码异常类似,都是因为某些字符超出了ASCII可表示的范围。
>>> utf8_encoded_bytes.decode('ascii')
Traceback (most recent call last):
File "", line 1, in
UnicodeDecodeError: 'ascii' codec can't decode byte 0xc3 in position 13: ordinal not in range(128)
又或者我们使用UTF-8解码并不符合UTF-8编码规范的错误bytes字符串,也会出现错误。事实上UTF-8的有点质疑在于其能够识别不符合编码规范的随机bytes流,所以出现错误的数据并不能够成功解码。
>>> wrong_seq.decode('utf-8')
Traceback (most recent call last):
File "", line 1, in
File "/usr/local/Cellar/python/2.7.13/Frameworks/Python.framework/Versions/2.7/lib/python2.7/encodings/utf_8.py", line 16, in decode
return codecs.utf_8_decode(input, errors, True)
UnicodeDecodeError: 'utf8' codec can't decode byte 0x89 in position 1: invalid start byte
最为诡异的解码错误出现在如下这种情况中。如果我们对于一个bytes字符串再次调用encode()方法,事实上程序会抛出一个UnicodeDecodeError。
>>> utf8_encoded_bytes.encode('utf-8')
Traceback (most recent call last):
File "", line 1, in
UnicodeDecodeError: 'ascii' codec can't decode byte 0xc3 in position 13: ordinal not in range(128)
这个情况可能会使很多人崩溃并开始怀疑人生。事实上这是由于Python2所谓的implicit conversion导致的。也就是说,Python2会尝试自动解码一些字符串以方便编程。这一过程如果在数据中仅有ASCII字符时非常有用。但一旦出现非ASCII字符,就会带来无尽的痛苦。上述代码中的utf8_encoded_bytes.encode('utf-8')事实上等同于utf8_encoded_bytes.decode(sys.getdefaultencoding()).encode('utf-8')。当系统默认编码不同于byte字符串被编码的格式时,就会出错。
Implicit Conversion
上文中提到的implicit Conversion会在很多我们习以为常的代码中出现。但如果不了解之而已机制的话,就会导致debug相应错误时极大的痛苦。我们在这里讨论更多发生implicit conversion的情形。
当我们试图连接unicode和bytes时,python会以默认编码格式解码bytes字符串来产生一个unicode字符串。如下面例子所示。当我们想要将unicode字符串u'Hello'与bytes字符串' World!'组合起来时,Python2会首先尝试使用默认编码格式解码bytes字符串。
默认编码格式往往是ASCII。因为ASCII被广泛的使用,且ASCII是大部分编码格式的子集,因此在大部分情况下是安全的。
>>> u'Hello' + ' World!'
u'Hello World!'
# 上述过程等同于下面的代码
>>> u'Hello' + (' World!'.decode(sys.getdefaultencoding()))
u'Hello World!'
>>> sys.getdefaultencoding()
'ascii'
# 如果byte字符串不能被ascii解码,则会报错
>>> utf8_encoded_bytes
'Hello World! \xc3\xb8'
>>> u'Hello' + utf8_encoded_bytes
Traceback (most recent call last):
File "", line 1, in
UnicodeDecodeError: 'ascii' codec can't decode byte 0xc3 in position 13: ordinal not in range(128)
>>> u'Hello' + utf8_encoded_bytes.decode(sys.getdefaultencoding())
Traceback (most recent call last):
File "", line 1, in
UnicodeDecodeError: 'ascii' codec can't decode byte 0xc3 in position 13: ordinal not in range(128)
由上面的例子看出,如果我们试图组合的byte字符串可以被ASCII解码,则这一过程是安全的。否则就会导致UnicodeDecodeError。所以如果我们的代码中不小心混用了unicode字符串和byte字符串,当所有数据都是ASCII字符的情况下,一切可以相安无事。否则就会报错。
错误处理
上面提到encode()和decode()方法接受两个参数,分别是encoding与errors。后者用来指定编码/解码出错时程序如何反应。errors参数可以是['strict', 'replace', 'ignore', 'xmlcharrefreplace']其中之一。
默认为'strict'。这一情况下对于解码和编码错误方法会抛出异常。
当指定为'replace'时,标准替代字符将会替代无法编码的字符。
当指定为'ignore'时,所有无法解码的字符会被直接忽略。
当指定为'xmlcharrefreplace'时,所有原有的码字会被使用XML转义符保存,因此当输出信息会被XML或者HTML时仍能被转码。
如下面的例子中所示。
>>> print(utf8_encoded_bytes.decode('ascii', 'replace'))
Hello World! ��
>>> utf8_encoded_bytes.decode('ascii', 'ignore')
u'Hello World! '
>>> print(utf8_encoded_bytes.decode('ascii', 'ignore'))
Hello World!
Python3
Python2和Python3最主要的区别是它们如何处理unicode。上面我们已经说过Python2中的str类型中存储的数据事实上是bytes。Python3中仍有两种字符串类型str和bytes。但在Python3中,str中存储的是一系列unicode码字。如果仍要处理一系列bytes字符串,则需要在字符串直接量前面加 b 前缀。这种情况下你将会得到一个bytes类型的对象。
如下面所示。
>>> py3_str = 'Hello World! \u00f8'
>>> type(py3_str)
>>> u_str = u'Hello World!'
>>> type(u_str)
>>> py3_bytes = b'Hello World!'
>>> type(py3_bytes)
总结起来,就是Python2中的str在Python3中为bytes,Python 2中的unicode是Python 3中的str。这一设计事实上更为合理,因为在程序中当你使用一个变量存储一些文字信息时,你想要处理的是unicode。而bytes仅仅应当在需要的时候使用,例如进行文件IO或者网络IO时。其余时候代码并不应该关心文字本身是被如何编码为bytes的。
与此同时,Python3在Unicode支持方面所做的最大的一项改变是其不再对byte字符串进行自动解码。如果我们想要在Python3中直接对bytes字符串和Unicode字符串相加,则程序会报错,如下面的例子所示。
>>> py3_str = 'Hello World! \xf8'
>>> py3_bytes = b'Hello World!'
>>> py3_str + py3_bytes
Traceback (most recent call last):
File "", line 1, in
TypeError: Can't convert 'bytes' object to str implicitly
从上述例子中我们可以看出,Python3并不再支持自动bytes字符串自动解码,这与上面Python2的处理方式是截然不同的。这事实上也使得程序的逻辑更为清晰,可读性和健壮性更强了。当然,是在使得语法更加繁琐的代价下。
Python2与Python3在unicode处理方面另一个非常大的不同在于如何衡量字符串是否相等这一方面。在Python2中,如果一个unicode字符串和一个byte字符串均仅包含ASCII对应的byte编码时,则它们被认为是相等的两个字符串,==操作将会返回True。而在Python3则不存在这一情况。这一区别会导致Python2与Python3程序极大的不兼容性。例如如果在Python2中使用一个byte字符串作为字典的键(key),使用相应的unicode字符串仍可以取出这一键对应的值(value)。在Python3中则无法找到。如下面的例子中所示。
# Python2
>>> py2_str = u'Hello World!'
>>> py2_bytes = 'Hello World!'
>>> py2_str == py2_bytes
True
# Python3
>>> py3_str = 'Hello World!'
>>> py3_bytes = b'Hello World!'
>>> py3_str == py3_bytes
False
因此,在Python3中,如果需要混合bytes和unicode,我们需要显式进行类型转换。
也就是说,在Python2中,只要我们所处理的字符串中只有ASCII字符,无论他们是unicode字符串还是byte字符串,任何操作都与操作两个同样的unicode字符串等价。然而在Python3中,无论何时我们都需要首先将两个字符串转换成同一种类型,unicode/str或者byte。
因此在Python2中,程序的错误是推迟出现的。如果我们一开始只使用了ASCII字符,程序完全正确运行。之后却可能因为遇到了非ASCII字符而出错。
而在Python3中,如果程序无法正确处理unicode和byte以及二者之间的相互转换,即使仅仅处理ASCII字符,程序也会立刻报错。相比Python2,Python3中对于unicode和byte之间的界限划分变得更为严格和明确了。其迫使我们明确程序处理的是何种字符串,否则就会报错。因此在某种意义上使得在Python2中模糊不清的unicode错误变得更为明确和容易debug了,虽然代价是我们需要写更多的代码来处理二者之间的关系。
Python3中的文件IO
因为上述Python3中对于unicode和byte的处理方式,Python3中文件的读取过程也做了相应的改变,也就是说,Python3的open()方法与Python2是不同的。Python2的open方法签名为:open(name[, mode[, buffering]])。Python3的open方法签名为:open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)。
Python文件读取有两种模式:二进制(binary)和文本(text)。
在Python2中,二者的不同仅仅在于对于行结尾的处理方式上,基本上没有任何本质的不同。
在Python3中,二者将会产生完全不同的结果。如果使用文本(text)模式读取文件,例如使用'r'或'w',从文中读取的数据将被解码成为unicode/str对象。如果在read方法中不指定encoding=参数,则默认编码格式将被使用,程序通过locale.getpreferredencoding()方法获得编码格式。否则程序使用encoding参数指定的编码方式解码。而如果使用二进制(binary)模式读取文件,例如'rb'或者'wb',读取的数据将不会被做任何处理,产生byte对象。因此在Python3中正确地读取一个文件需要我们指定正确的编码格式。
Unicode处理指南
根据Ned Batchelder在PyCon2012上的讲座,我们可以通过下面两个方法来一次性解决Python2与Python3中的unicode问题。
方法一:Unicode三明治
这一方法既在程序中我们总是仅仅处理unicode字符串,而在程序外仅存储和保留byte字符串。也就是程序内unicode,程序外byte。这要求我们在程序进行IO的入口处解码读取到的数据,在程序进行IO的出口处编码输出的数据。也就是,在程序中我们应当尽可能早地解码数据从而得到unicode对象,同时应当尽可能晚地编码数据从而输出byte对象。这样我们就创造了一个所谓的unicode三明治。
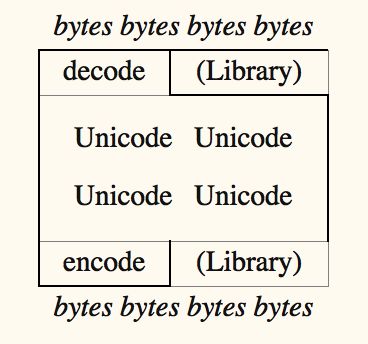
同时我们也要注意有一些库本身会进行这些解码/编码过程,例如接收unicode作为输入,或者使用unicode作为输出,且会进行unicode和bytes之间的转化。例如Django和json库。
方法二:清楚了解被处理的数据
为了保证程序的正常运行,我们需要清楚我们正在处理的数据的类型,及其编码格式。在程序中,当处理一个字符串时,我们必须清楚其类型,是一个byte还是一个unicode对象?其编码格式是怎样的?我们无法通过数据本身去推测数据的编码类型,所以这必须是提前决定和设计好的流程。
有时我们无法通过仅仅print一个字符串来debug代码,而是必须通过type()方法和repr()方法来读取这个数据的类型和码字到底是什么。如下面例子所示。
>>> u_str = u'Hello World! \u00f8'
>>> print(repr(u_str))
u'Hello World! \xf8'
>>> print(type(u_str))
由于我们无法通过数据本身推断其编码格式,所以数据的编码格式必须被通过某种方法显式地指定。一些通信协议例如HTTP,HTML或者XML会在数据头部指定编码格式。或者我们可以通过一些文档确定我们收到的数据的编码格式。但无论如何,我们都必须依赖额外信息来确定数据本身的编码格式。否则,我们就只能 猜测 数据的编码格式,这一行为会导致无意义字符串的产生。如下面的例子所示。同一列byte流以不同方式都有可能成功解码,并产生一系列完全不同的字符串。这种情况下,程序完全不会报错,而只有试图读取产生的数据的人会知道程序在某个地方出错了。
>>> byte_str = '\x48\x69\xe2\x84\x99\xc6\xb4\xe2\x98\x82\xe2\x84\x8c\xc3\xb8\xe1\xbc\xa4'
>>> byte_str.decode('utf-8')
u'Hi\u2119\u01b4\u2602\u210c\xf8\u1f24'
>>> print(byte_str.decode('utf-8'))
Hiℙƴ☂ℌøἤ
>>> print(byte_str.decode('iso8859-1'))
Hi�ƴ��øἤ
>>> print(byte_str.decode('utf-16-le'))
楈蓢욙芘蓢쎌꒼
>>> print(byte_str.decode('utf-16-be'))
䡩駆듢颂賃룡벤
>>> print(byte_str.decode('shift-jis'))
Hi邃卮エ笘やъテク眈、
另一个令人难过的事实时,有些时候即使我们通过额外信息得知了一系列数据的编码格式,这些信息也有可能是错的。例如有时候,在HTTP回复的包头我们得知回复是以utf-16编码的,但结果数据却是以utf-8编码的。有时候我们会成功以错误的编码格式解码数据,同时得到一系列无意义字符串,就像上面例子中给出的一样。其他一些更幸运的时候,数据会解码失败,我们会得到UnicodeError从而可以进一步debug代码。
方法三:使用Unicode输入测试我们的代码
正因为真实世界中编码格式的复杂性,为了保证程序在各种情况下都正确运行,我们需要充分测试我们的程序。例如通过除ASCII字符之外的unicode输入测试程序,例如从QQ空间复制一些火星文签名甯可高慠白勺發黣,伓呿卑薇白勺攣噯(雾)。
总结
根据Ned Batchelder在PyCon2012上的讲座,我们将Python处理unicode的五个事实以及三条解决建议总结如下:
五个事实
- IO操作应当总是处理bytes。
- 现实世界需要远多于256个字符编码。
- 程序既需要面对bytes,也需要面对unicodes。
- 数据编码格式无法通过数据内容本身推测出来。
- 即使是事先声明的数据编码格式也有可能出错。
三条建议
- 使用unicode三明治的模式处理文本数据。
- 明确程序正在使用和处理的数据的类型及编码格式。
- 使用非ASCII字符串测试程序。