我们知道Druid能够同时提供对大数据集的实时摄入和高效复杂查询的性能,主要原因就是它独到的架构设计和基于Datasource与Segment的数据存储结构。接下来我们会分别从数据存储和系统节点架构两方面来深入了解一下Druid的架构。
数据存储
Druid将数据组织成Read-Optimized的结构,而这也是Druid能够支持交互式查询的关键。Druid中的数据存储在被称为datasource中,类似RDMS中的table。每个datasource按照时间划分,如果你有需求也可以进一步按其它属性划分。每个时间范围称为一个chunk(比如你按天分区,则一个chunk为一天)。在chunk中数据由被分为一个或多个segment(segment是数据实际存储结构,Datasource、Chunk只是一个逻辑概念),每个segment都是一个单独的文件,通常包含几百万行数据,这些segment是按照时间组织成的chunk,所以在按照时间查询数据时,效率非常高。

数据分区
任何分布式存储/计算系统,都需要对数据进行合理的分区,从而实现存储和计算的均衡,以及数据并行化。而Druid本身处理的是事件数据,每条数据都会带有一个时间戳,所以很自然的就可以使用时间进行分区。比如上图,我们指定了分区粒度为为天,那么每天的数据都会被单独存储和查询(一个分区下有多个Segment的原因往下看)。
使用时间分区我们很容易会想到一个问题,就是很可能每个时间段的数据量是不均衡的(想一想我们的业务场景),而Duid为了解决这种问题,提供了“二级分区”,每一个二级分区称为一个Shard(这才是物理分区)。通过设置每个Shard的所能存储的目标值和Shard策略,来完成shard的分区。Druid目前支持两种Shard策略:Hash(基于维值的Hash)和Range(基于某个维度的取值范围)。上图中,2000-01-01和2000-01-03的每个分区都是一个Shard,由于2000-01-02的数据量比较多,所以有两个Shard。
Segment
Shard经过持久化之后就称为了Segment,Segment是数据存储、复制、均衡(Historical的负载均衡)和计算的基本单元了。Segment具有不可变性,一个Segment一旦创建完成后(MiddleManager节点发布后)就无法被修改,只能通过生成一个新的Segment来代替旧版本的Segment。
Segment内部存储结构
接下来我们可以看下Segment文件的内部存储结构。因为Druid采用列式存储,所以每列数据都是在独立的结构中存储(并不是独立的文件,是独立的数据结构,因为所有列都会存储在一个文件中)。Segment中的数据类型主要分为三种:时间戳、维度列和指标列。
对于时间戳列和指标列,实际存储是一个数组,Druid采用LZ4压缩每列的整数或浮点数。当收到查询请求后,会拉出所需的行数据(对于不需要的列不会拉出来),并且对其进行解压缩。解压缩完之后,在应用具体的聚合函数。
对于维度列不会像指标列和时间戳这么简单,因为它需要支持filter和group by,所以Druid使用了字典编码(Dictionary Encoding)和位图索引(Bitmap Index)来存储每个维度列。每个维度列需要三个数据结构:
- 需要一个字典数据结构,将维值(维度列值都会被认为是字符串类型)映射成一个整数ID。
- 使用上面的字典编码,将该列所有维值放在一个列表中。
- 对于列中不同的值,使用bitmap数据结构标识哪些行包含这些值。
Druid针对维度列之所以使用这三个数据结构,是因为:
- 使用字典将字符串映射成整数ID,可以紧凑的表示结构2和结构3中的值。
- 使用Bitmap位图索引可以执行快速过滤操作(找到符合条件的行号,以减少读取的数据量),因为Bitmap可以快速执行AND和OR操作。
- 对于group by和TopN操作需要使用结构2中的列值列表。
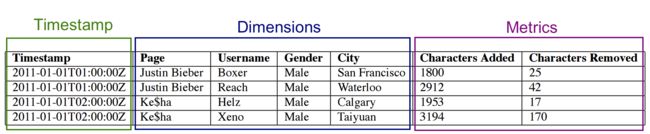
我们以上面"Page"维度列为例,可以具体看下Druid是如何使用这三种数据结构存储维度列:
1. 使用字典将列值映射为整数
{
"Justin Bieher":0,
"ke$ha":1
}
2. 使用1中的编码,将列值放到一个列表中
[0,0,1,1]
3. 使用bitmap来标识不同列值
value = 0: [1,1,0,0] //1代表该行含有该值,0标识不含有
value = 1: [0,0,1,1]
下图是以advertiser列为例,描述了advertiser列的实际存储结构:

前两种存储结构在最坏情况下会根据数据量增长而成线性增长(列数据中的每行都不相同),而第三种由于使用Bitmap存储(本身是一个稀疏矩阵),所以对它进行压缩,可以得到非常客观的压缩比。Druid而且运用了Roaring Bitmap(http://roaringbitmap.org/)能够对压缩后的位图直接进行布尔运算,可以大大提高查询效率和存储效率(不需要解压缩)。
Segment命名
高效的数据查询,不仅仅体现在文件内容的存储结构上,还有一点很重要,就是文件的命名上。试想一下,如果一个Datasource下有几百万个Segment文件,我们又如何快速找出我们所需要的文件呢?答案就是通过文件名称快速索引查找。
Segment的命名包含四部分:数据源(Datasource)、时间间隔(包含开始时间和结束时间两部分)、版本号和分区(Segment有分片的情况下才会有)。
test-datasource_2018-05-21T16:00:00.000Z_2018-05-21T17:00:00.000Z_2018-05-21T16:00:00.000Z_1
数据源名称_开始时间_结束时间_版本号_分区
分片号是从0开始,如果分区号为0,则可以省略:test-datasource_2018-05-21T16:00:00.000Z_2018-05-21T17:00:00.000Z_2018-05-21T16:00:00.000Z
还需要注意如果一个时间间隔segment由多个分片组成,则在查询该segment的时候,需要等到所有分片都被加载完成后,才能够查询(除非使用线性分片规范(linear shard spec),允许在未加载完成时查询)。
| 字段 | 是否必须 | 描述 |
|---|---|---|
| datasource | 是 | segment所在的Datasource |
| 开始时间 | 是 | 该Segment所存储最早的数据,时间格式是ISO 8601。开始时间和结束时间是通过segmentGranularity设置的时间间隔 |
| 结束时间 | 是 | 该segment所存储最晚的数据,时间格式是ISO 8601 |
| 版本号 | 是 | 因为Druid支持批量覆盖操作,当批量摄入与之前相同数据源、相同时间间隔数据时,数据就会被覆盖,这时候版本号就会被更新。Druid系统的其它部分感知到这个信号后,就会把就旧数据删除,使用新版本的数据(这个切换很快)。版本号也是是用的ISO 8601时间戳,但是这个时间戳代表首次启动的时间 |
| 分区号 | 否 | segment如果采用分区,才会有该标识 |
Segment物理存储实例
下面我们以一个实例来看下Segment到底以什么形式存储的,我们以本地导入方式将下面数据导入到Druid中。
{"time": "2018-11-01T00:47:29.913Z","city": "beijing","sex": "man","gmv": 20000}
{"time": "2018-11-01T00:47:33.004Z","city": "beijing","sex": "woman","gmv": 50000}
{"time": "2018-11-01T00:50:33.004Z","city": "shanghai","sex": "man","gmv": 10000}
我们以单机形式运行Druid,这样Druid生成的Segment文件都在${DRUID_HOME}/var/druid/segments 目录下。

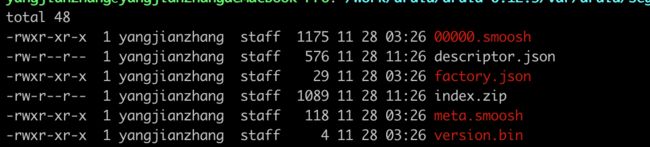
segment通过datasource_beginTime_endTime_version_shard用于唯一标识,在实际存储中是以目录的形式表现的。
可以看到Segment中包含了Segment描述文件(descriptor.json)和压缩后的索引数据文件(index.zip),我们主要看的也是index.zip这个文件,对其进行解压缩。
首先看下factory.json这个文件,这个文件并不是segment具体存储段数据的文件。因为Druid通过使用MMap(一种内存映射文件的方式)的方式访问Segment文件,通过查看这个文件内容来看,貌似是用于MMap读取文件所使用的(不太了解MMap)?
#factory.json文件内容
{"type":"mMapSegmentFactory"}
Druid实际存储Segment数据文件是:version.bin、meta.smoosh和xxxxx.smoosh这三个文件,下面分别看下这三个文件的内容。
version.bin是一个存储了4个字节的二进制文件,它是Segment内部版本号(随着Druid发展,Segment的格式也在发展),目前是V9,以Sublime打开该文件可以看到:
0000 0009
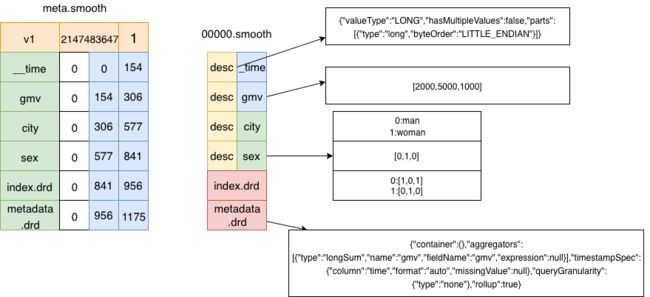
meta.smoosh里面存储了关于其它smoosh文件(xxxxx.smoosh)的元数据,里面记录了每一列对应文件和在文件的偏移量。除了列信息外,smoosh文件还包含了index.drd和metadata.drd,这部分是关于Segment的一些额外元数据信息。
#版本号,该文件所能存储的最大值(2G),smooth文件数
v1,2147483647,1
# 列名,文件名,起始偏移量,结束偏移量
__time,0,0,154
city,0,306,577
gmv,0,154,306
index.drd,0,841,956
metadata.drd,0,956,1175
sex,0,577,841
再看00000.smoosh文件前,我们先想一下为什么这个文件被命名为这种样式?因为Druid为了最小化减少打开文件的句柄数,它会将一个Segment的所有列数据都存储在一个smoosh文件中,也就是xxxxx.smoosh这个文件。但是由于Druid使用MMap来读取Segment文件,而MMap需要保证每个文件大小不能超过2G(Java中的MMapByteBuffer限制),所以当一个smoosh文件大于2G时,Druid会将新数据写入到下一个smoosh文件中。这也就是为什么这些文件命名是这样的,这里也对应上了meta文件中为什么还要标识列所在的文件名。
通过meta.smoosh的偏移量也能看出,00000.smoosh文件中数据是按列进行存储的,从上到下分别存储的是时间列、指标列、维度列。对于每列主要包会含两部分信息:ColumnDescriptor和binary数据。columnDescriptor是一个使用Jackson序列化的对象,它包含了该列的一些元数据信息,比如数据类型、是否是多值等。而binary则是根据不同数据类型进行压缩存储的二进制数据。
^@^@^@d{"valueType":"LONG","hasMultipleValues":false,"parts":[{"type":"long","byteOrder":"LITTLE_ENDIAN"}]}^B^@^@^@^C^@^@ ^@^A^A^@^@^@^@"^@^@^@^A^@^@^@^Z^@^@^@^@¢yL½Ìf^A^@^@<8c>X^H^@<80>¬^WÀÌf^A^@^@^@^@^@d{"valueType":"LONG","hasMultipleValues":false,"parts":[{"type":"long","byteOrder":"LITTLE_ENDIAN"}]}^B^@^@^@^C^@^@ ^@^A^A^@^@^@^@ ^@^@^@^A^@^@^@^X^@^@^@^@1 N^@^A^@"PÃ^H^@<80>^P'^@^@^@^@^@^@^@^@^@<9a>{"valueType":"STRING","hasMultipleValues":false,"parts":[{"type":"stringDictionary","bitmapSerdeFactory":{"type":"concise"},"byteOrder":"LITTLE_ENDIAN"}]}^B^@^@^@^@^A^A^@^@^@#^@^@^@^B^@^@^@^K^@^@^@^W^@^@^@^@beijing^@^@^@^@shanghai^B^A^@^@^@^C^@^A^@^@^A^A^@^@^@^@^P^@^@^@^A^@^@^@^H^@^@^@^@0^@^@^A^A^@^@^@^@^\^@^@^@^B^@^@^@^H^@^@^@^P^@^@^@^@<80>^@^@^C^@^@^@^@<80>^@^@^D^@^@^@<9a>{"valueType":"STRING","hasMultipleValues":false,"parts":[{"type":"stringDictionary","bitmapSerdeFactory":{"type":"concise"},"byteOrder":"LITTLE_ENDIAN"}]}^B^@^@^@^@^A^A^@^@^@^\^@^@^@^B^@^@^@^G^@^@^@^P^@^@^@^@man^@^@^@^@woman^B^A^@^@^@^C^@^A^@^@^A^A^@^@^@^@^P^@^@^@^A^@^@^@^H^@^@^@^@0^@^A^@^A^@^@^@^@^\^@^@^@^B^@^@^@^H^@^@^@^P^@^@^@^@<80>^@^@^E^@^@^@^@<80>^@^@^B^A^@^@^@^@&^@^@^@^C^@^@^@^G^@^@^@^O^@^@^@^V^@^@^@^@gmv^@^@^@^@city^@^@^@^@sex^A^A^@^@^@^[^@^@^@^B^@^@^@^H^@^@^@^O^@^@^@^@city^@^@^@^@sex^@^@^AfÌ<91>Ð^@^@^@^AfѸ,^@^@^@^@^R{"type":"concise"}{"container":{},"aggregators":[{"type":"longSum","name":"gmv","fieldName":"gmv","expression":null}],"timestampSpec":{"column":"time","format":"auto","missingValue":null},"queryGranularity":{"type":"none"},"rollup":true}
smooth文件中的binary数据经过LZ4或Bitmap压缩,所以无法看到数据原始内容。
在smooth文件最后还包含了两部分数据,分别是index.drd和metadata.drd。其中index.drd中包含了Segment中包含哪些度量、维度、时间范围、以及使用哪种bitmap。metadata.drd中存储了指标聚合函数、查询粒度、时间戳配置等(上面内容的最后部分)。
下图是物理存储结构图,存储未压缩和编码的数据就是最右边的内容。
Segment创建
Segment都是在MiddleManager节点中创建的,并且处在MiddleManager中的Segment在状态上都是可变的并且未提交的(提交到DeepStorage之后,数据就不可改变)。
Segment从在MiddleManager中创建到传播到Historical中,会经历以下几个步骤:
- MiddleManager中创建Segment文件,并将其发布到Deep Storage。
- Segment相关的元数据信息被存储到MetaStore中。
- Coordinator进程根据MetaStore中得知Segment相关的元数据信息后,根据规则的设置分配给复合条件的Historical节点。
- Historical节点得到Coordinator指令后,自动从DeepStorage中拉取Segment数据文件,并通过Zookeeper向集群声明负责提供该Segment数据相关的查询服务。
- MiddleManager在得知Historical负责该Segment后,会丢弃该Segment文件,并向集群声明不在负责该Segment相关的查询。
如何配置分区
可以通过granularitySpec中的segmentGranularity设置segment的时间间隔(http://druid.io/docs/latest/ingestion/ingestion-spec.html#granularityspec)。为了保证Druid的查询效率,每个Segment文件的大小建议在300MB~700MB之间。如果超过这个范围,可以修改时间间隔或者使用分区来进行优化(配置partitioningSpec中的targetPartitionSize,官方建议设置500万行以上;http://druid.io/docs/latest/ingestion/hadoop.html#partitioning-specification)。
系统架构详解
我们知道Druid节点类型有五种:Overload、MiddleManager、Coordinator、Historical和Broker。

Overload和MiddleManager主要负责数据摄入(对于没有发布的Segment,MiddleManager也提供查询服务);Coordinator和Historical主要负责历史数据的查询;Broker节点主要负责接收Client查询请求,拆分子查询给MiddleManager和Historical节点,然后合并查询结果返回给Client。其中Overload是MiddleManager的master节点,Coordinator是Historical的master节点。
索引服务
Druid提供一组支持索引服务(Indexing Service)的组件,也就是Overload和MiddleManager节点。索引服务是一种高可用的分布式服务,用于运行跟索引相关的任务,索引服务是数据摄入创建和销毁Segment的主要方式(还有一种是采用实时节点的方式,但是现在已经废弃了)。索引服务支持以pull或push的方式摄入外部数据。
索引服务采用的是主从架构,Overload为主节点,MiddleManager是从节点。索引服务架构图如下图所示:

索引服务由三部分组件组成:用于执行任务的Peon(劳工)组件、用于管理Peon的MiddleManager组件和分配任务给MiddleManager的Overload组件。MiddleManager和Overload组件可以部署在相同节点也可以跨节点部署,但是Peon和MiddleManager是部署在同一个节点上的。
索引服务架构和Yarn的架构很像:
- Overlaod节点相当于Yarn的ResourceManager,负责集群资源管理和任务分配。
- MiddleManager节点相当于Yarn的NodeManager,负责接受任务和管理本节点的资源。
- Peon节点相当于Yarn的Container,执行节点上具体的任务。
Overload节点
Overload作为索引服务的主节点,对外负责接受索引任务,对内负责将任务分解并下发给MiddleManager。Overload有两种运行模式:
- 本地模式(Local Mode):默认模式。本地模式下的Overload不仅负责任务协调工作,还会负责启动一些peon来完成具体的任务。
- 远程模式(Remote Mode):该模式下,Overload和MiddleManager运行在不同的节点上,它仅负责任务的协调工作,不负责完成具体的任务。
Overload提供了一个UI客户端,可以用于查看任务、运行任务和终止任务等。
http://:/console.html
Overload提供了RESETful的访问形式,所以客户端可以通过HTTP POST形式向请求节点提交任务。
http://:/druid/indexer/v1/task //提交任务
http://:/druid/indexer/v1/task/{task_id}/shutdown //杀死任务
MiddleManager节点
MiddleManager是执行任务的工作节点,MiddleManager会将任务单独发给每个单独JVM运行的Peon(因为要把资源和日志进行隔离),每个Peon一次只能运行一个任务。
Peon节点
Peon在单个JVM中运行单个任务,MiddleManager负责为任务创建Peon。
Coordinator节点
Coordinator是Historical的mater节点,它主要负责管理和分发Segment。具体工作就是:告知Historical加载或删除Segment、管理Segment副本以及负载Segment在Historical上的均衡。
Coordinator是定期运行的,并且运行间隔可以通过配置参数配置。每次Coordinator运行都会通过Zookeeper获取当前集群状态,通过评估集群状态来采取适当的操作(比如均衡负载Segment)。Coordinator会连接数据库(MetaStore),数据库中存储了Segment信息和规则(Rule)。Segment表中列出了需要加载到集群中的所有Segment,Coordinator每次运行都会从Segment表来拉取Segment列表并与当前集群的Segment对比,如果发现数据库中不存在的Segment,但是在集群中还有,就会把它从集群删掉;规则表定义了如何处理Segment,规则的作用就是我们可以通过配置一组规则,来操作集群加载Segment或删除Segment。关于如何配置规则,可以查看:http://druid.io/docs/latest/operations/rule-configuration.html。
Historical节点加载Segment前,会进行容量排序,哪个Historical节点的Segment最少,则它就具有最高的加载权。Coordinator不会直接Historical节点通信,而是将Segment信息放到一个队列中,Historical节点去队列取Segment描述信息,并且加载该Segment到本节点。
Coordinator提供了一UI界面,用于显示集群信息和规则配置:
http://:
Historical节点
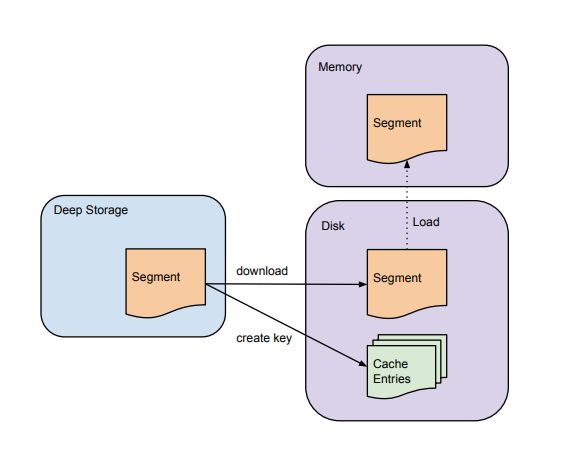
Historical节点负责管理历史Segment,Historical节点通过Zookeeper监听指定的路径来发现是否有新的Segment需要加载(Coordinator通过分配算法指定具体的Historical)。
上面通过Coordinator知道,当有新的Segment需要加载的时候,Coordinator会将其放到一个队列中。当Historical节点收到有新的Segment时候,就会检测本地cache和磁盘,查看是否有该Segment信息。如果没有Historical节点会从Zookeeper中拉取该Segment相关的信息,然后进行下载。
Broker
Broker节点是负责转发Client查询请求的,Broker通过zookeeper能够知道哪个Segment在哪些节点上,Broker会将查询转发给相应节点。所有节点返回数据后,Broker会将所有节点的数据进行合并,然后返回给Client。
Broker会有一个LRU(高速缓存失效策略),来缓存每Segment的结果。这个缓存可以是本地缓存,也可以借助外部缓存系统(比如memcached),第三方缓存可以在所有broker中共享Segment结果。当Borker接收到查询请求后,会首先查看本地是否有对应的查询数据,对于不存在的Segment数据,会将请求转发给Historical节点。

Broker不会缓存实时数据,因为实时数据处于不可靠状态。
关注我
欢迎关注我的公众号,会定期推送优质技术文章,让我们一起进步、一起成长!
公众号搜索:data_tc
或直接扫码:
