这里可以参考CSDN上的文章-BERT原理和实践:https://blog.csdn.net/jiaowoshouzi/article/category/9060488
1.引入
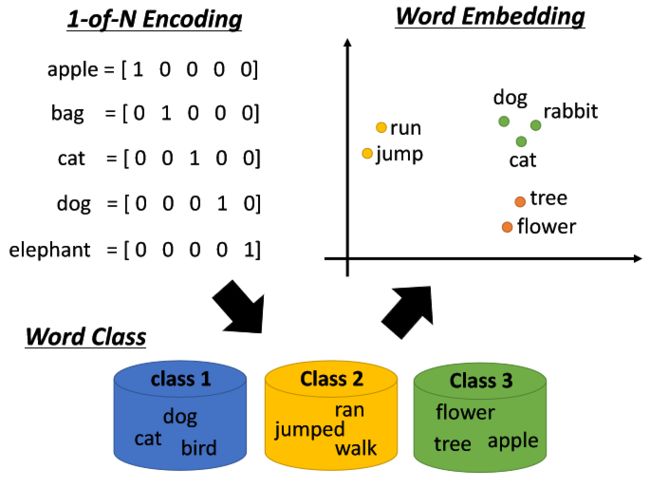
在解释BERT,ELMO这些预训练模型之前,我们先看一下很久之前的计算机是如何读懂文字的?
每个字都有自己的独特的编码。但是这样是有弊端的,字和字之间的关联关系是无法得知的,比如计算机无法知道dog和cat都是动物,它反而会觉得bag和dog是比较相近的。
所以后来就有了Word Class,将一系列的词进行分类然后让一类词语和一类词语之间更有关联,但是这样的方法太过于粗糙,比如dog,cat,bird是一类,看不出哺乳动物鸟类的区别。
在这个基础之上,我们有了Word Embedding,Word Embedding我们可以想象成是一种soft的word class,每个词都用向量来表示,它的向量维度可能表示这个词汇的某种意思,如图中dog,cat,rabbit的距离相比其他更近。那么word embendding是如何训练出来的,是根据每个词汇的上下文所训练的。
2.简单word embedding存在的弊端

每个句子都有bank的词汇,四个bank是不同的token,但是同样的type。(注:token-词例, type-词型, class-词类 or token是出现的总次数(还有种理解是token是具有一定的句法语义且独立的最小文本成分。 ),type是出现的不同事物的个数。)
对于典型的Word Embedding认为,每个词type有一个embedding,所以就算是不同的token只要是一样的type那么word embedding就是一样的,语义也就是一样的。
而事实上并非如此,1,2句bank指的是银行,3,4为水库。所以我们希望让机器给不同意思的token而且type还一致,给予不同的embedding。在这个问题上,之前的做法是从字典中去查找这个词包含几种意思,但是这样的做法显然跟不上现实中词语的一些隐含的含义。比如bank有银行的意思,与money一起是银行的意思,而与blood一起却是血库的意思。
3.上下文Contextual word Embedding
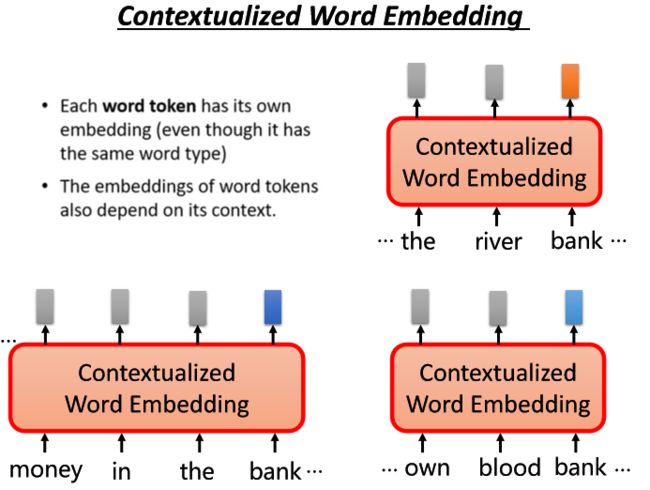
所以我们想让机器今天进一步做到每一个word token都可以有自己的embedding(之前是每个type有一个embedding或者有固定的一个或多个embedding),那么怎么知道一个word应该有怎样的embedding呢?我们可以取决于该词的上下文,上下文越相近的token它们就会越相近的embedding。比如之前提到的bank,下面两个句子它们的word token的embedding可能是相近的,而和上面的word token的embedding是相远的。
所以我们想使用一种能够基于上下文的Contextual word Embedding来解决一词多义的问题。
4.Embeddings from Language Model (ELMO)(https://arxiv.org/abs/1802.05365)
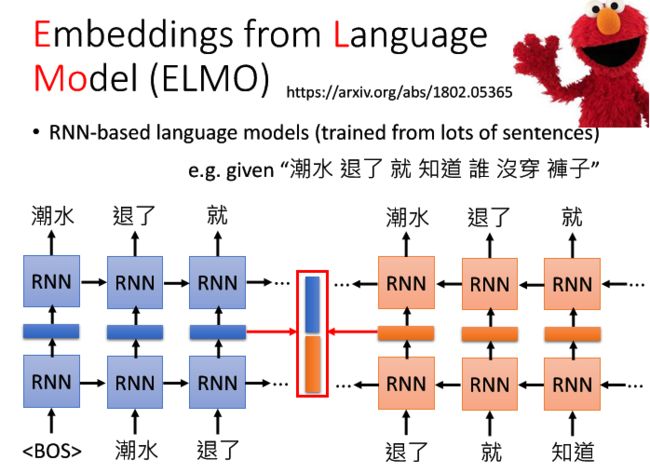
这里使用ELMO可以做到这件事情,即每个word token拥有不同的word embedding。(右上角动物是芝麻街(美国公共广播协会(PBS)制作播出的儿童教育电视节目)里的角色)。
它是基于RNN的预训练模型,它只需要搜集大量语料(句子)且不需要做任何标注,就可以训练这个基于RNN的语言模型,预测下一个token是什么,学习完了之后就得到了上下文的embedding。因为我们可以将RNN的隐藏层中的某一节点拿出来(图中橙蓝色节点),它就是输入当前结点的词汇的word embedding。
从当计算识别到
4.1ELMo的策略
假设当前要得到”退了”这个词的上下文embedding,首先,因为前边的RNN只考虑到了前文而没有考虑到后文,所以这里就使用了同前文一样的反向的RNN。然后,它从句尾开始进行,比如给它喂”知道”,它就要预测”就”,给它喂”就”,它就要预测”退了”。这时候就不仅考虑每个词汇的前文,还会考虑每个词的后文。最后将正向和逆向得到的两个不同的上下文embedding(因为方向不同训练结果也不一样)拼接起来。
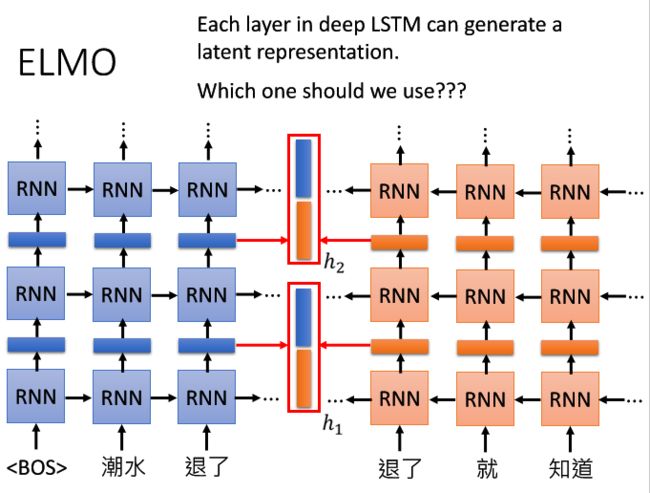
现在我们训练的程度都会越来越深度,当层数增加,这样就会产生Deep的RNN,因为很多层,而且每一层都会产生上下文Embedding,那么我们到底应该使用哪一层?每一层这种深度LSTM中的每个层都可以生成潜在表示(方框处)。同一个词在不同的层上会产生不同的Embedding,那么我们应该使用哪一层呢?ELMo的策略是每一层得到的上下文embedding都要。
4.2ELMo存在的问题
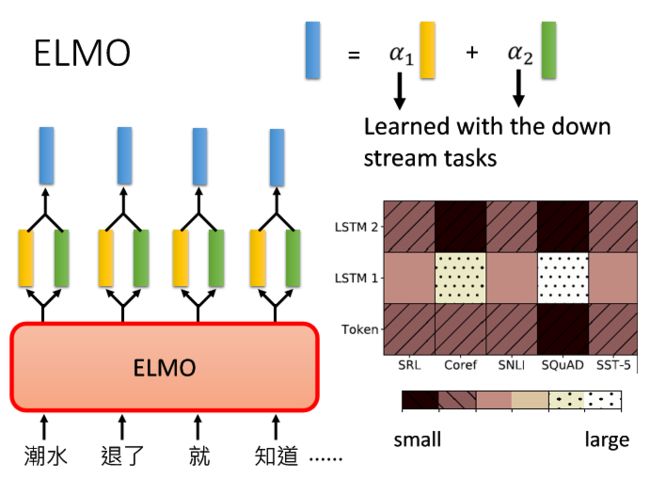
在上下文embedding的训练模型中,每个词输入进去都会有一个embedding输出来。但是在ELMo中,每个词汇输入进去,都会得到不止一个embedding,因为每层的RNN都会给到一个embedding,ELMo将它们统统加起来一起使用。
以图中为例,这里假设ELMo有两层RNN,这里是将α1(黄色,第一层得到的embedding)和α2(绿色,第二层得到embedding)加起来得到蓝色的embedding,并做为接下来要进行不同任务的输入。
但是这里存在一些问题,α1和α2是学习得到的,而且它是根据当前要进行的任务(如QA,POS of tagging ),然后根据接下来要进行的这些任务一起被学习出来。所以就导致不同任务导向下的α1和α2也不一样。
ELMo的论文中提到,在不同任务下(SRL,Coref,SNLI,SQuAD,SST-5)。蓝色的上下文embedding在经过token(这里为没有经过上下文的embedding),LSTM1,LSTM2后,它在不同阶段需要的weight也不一样。
5.Bidirectional Encoder Representations from Transformers (BERT)
5.1介绍BERT

BERT相当于是Transformer的Encoder部分,它只需要搜集大量的语料去从中学习而不经过标注(不需要label),就可以将Encoder训练完成。如果之前要训练Encoder,我们需要通过一些任务来驱动学习(如机器翻译)。
BERT就是句子给进去,每个句子给一个embedding。
这里可以回忆下,Transformer的Enoder中有self-attention layer,就是给进去一个sequence,输出也得到一个sequence。
注:
虽然图中使用是用词作为单元进行输入,但是在使用BERT进行中文的训练时,字会是一个更好的选择。比如,我们在给BERT进行输入时,用one-hot给词进行编码,但是词在中文中数量庞大,会导致维度过高。但是,字的话相对会少很多,特别是中文(大约几千个,可以穷举)。这样以字为单位进行输入会占很大优势。
5.2如何对BERT进行训练?
共有两种方法,一种是Mask LM遮盖语言模型,另一种是Next Sentence Prediction下一句预测。
5.2.1方法一:Mask LM遮盖语言模型
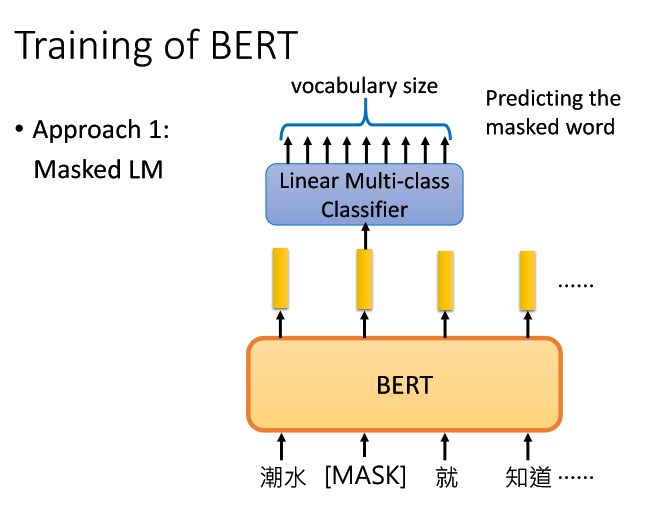
下面用上图的例子来理解BERT是怎么样来进行填空的:
1)这里假设在所有句子中的词汇的第2个位置上设置一个
2)接下来把所有的词汇输入BERT,然后每个输入的token都会得到一个embedding;
3)接下来将设置为
但是这个Linear Multi-class Classifier它仅仅是一个线性分类器,所以它的能力十分弱,这也就需要在之前的BERT模型中需要将它的层数等参数设计的相当好,然后得到非常出色的representation,便于线性分类器去训练。
那么我们怎么知道最后得到的embedding是什么样的呢?如果两个
5.2.2Next Sentence Prediction下一句预测

如图中,给定两个句子1)醒醒吧 和 2)你没有妹妹。其中特殊符号[SEP]是告诉BERT两个句子的分隔点在哪里。
特殊符号[CLS]一般放在句子的开头,它用来告诉BERT从这开始分类任务,[CLS]输入BERT后得到embedding然后通过Linear Binary Classifier得出结果说明:经过BERT预测后现在我们要预测的两个句子是接在一起 or 不应该被接在一起。
这里可能会有疑问,为什么不将[CLS]放在句尾,等BERT训练完两个句子再输出结果?
- 如果BERT的内部是正向的RNN那么再好不过,但是我们应该想到BERT的内部结构其实是一个人Transformer的Enocer,Encoder的内部是self-attention。对于self-attention来说,如果不考虑位置编码position encoding所造成的影响的话,一个token放在句中还是句尾是没有差别的。同理,其实[CLS]这个token对于BERT来说放在哪里也是影响不大的。
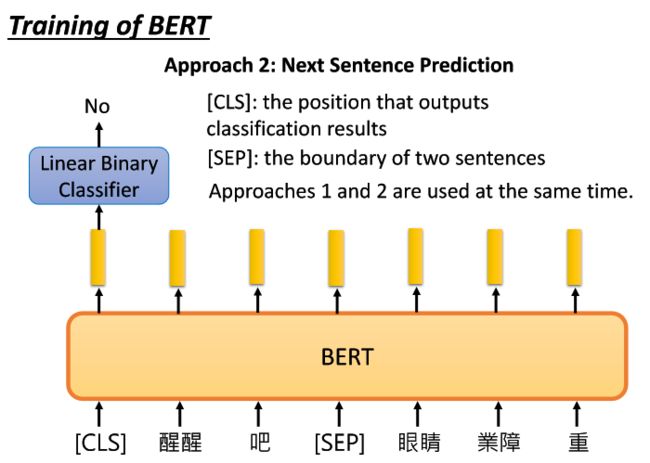
对于上图中的任务,BERT现在要做的事情就是给定两个句子,让BERT输出结果这两个句子是不是应该接在一起?
所以在语料库的大量句子中,我们是知道哪些句子是可以接在一起的,所以也需要我们告诉BERT哪些句子是接在一起的。
Linear Binary Classifier和BERT是一起被训练的,通过预测下一句这个任务,我们就可以把将BERT部分的最优参数训练出来。
现在我们知道了任务一和任务二,在原论文中两种任务是要同时进行的,这样才能将BERT的性能发挥到最佳。
5.3如何使用BERT?使用BERT的场景?
现在我们知道了BERT要做什么事情,那么我们要如何去使用它?共有四种方法。论文中是将【BERT模型和接下来你要进行的任务】结合在一起做训练。
5.3.1Case 1
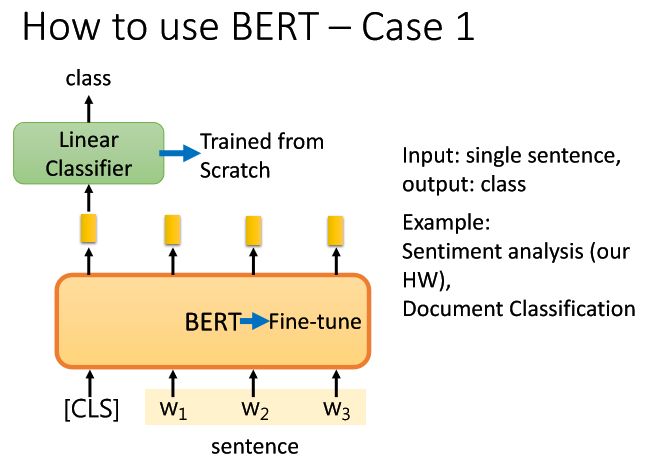
第一种,假设当前任务是Input一个sentence,out一个class,举例来说输入一句话来判断分类。
训练流程:1)将做要分类的句子丢给BERT;
2)需要在句子开始加上分类的特殊符号,这个特殊符号经过BERT输出的embedding经过线性分类器,输出结果为当前的句子属于的类别是真还是假。BERT和Linear Classifier的参数一起进行学习;
3)这里的Linear Classifier是Trained from Scratch是白手起家从头开始,即它的参数随机初始化设置,然后开始训练;
4)而BERT则是加上Fine-tune微调策略(一种迁移学习方式*),例如Generative Pre-trained Transformer(OpenAI GPT生成型预训练变换器)(Radford等,2018),引入了最小的任务特定参数,并通过简单地微调预训练参数在下游任务中进行训练。
*这里不得不提一下迁移学习中的Fine-tune,这里可以参考csdn的一篇文章:https://blog.csdn.net/u013841196/article/details/80919857
5.3.2Case 2
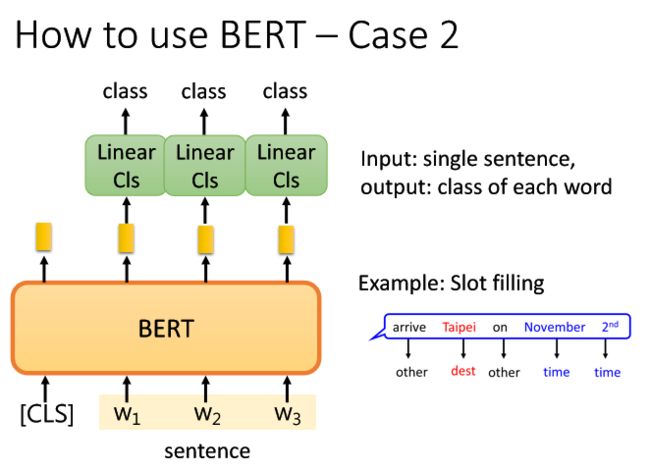
(https://arxiv.org/abs/1805.12471)
第二种,假设当前任务是input一个sentence,输出这个句子中的每个词汇属于正例还是负例。举例现在的任务是slot filling填槽任务(填槽指的是为了让用户意图转化为用户明确的指令而补全信息的过程)(另一种解释是从大规模的语料库中抽取给定实体(query)的被明确定义的属性(slot types)的值(slot fillers))(槽可以理解为实体已明确定义的属性),输入的句子是 arrive Taipei on November 2nd输出的槽是other dest on time time
训练流程:
1)将句子输入BERT,句子中的每个词汇都会映射出一个embedding;
2)每个词汇的embedding输入Linear Classifier,输出结果;
3)Linear Classifier 白手起家和Bert微调的方式一起去做学习。
5.3.3Case3
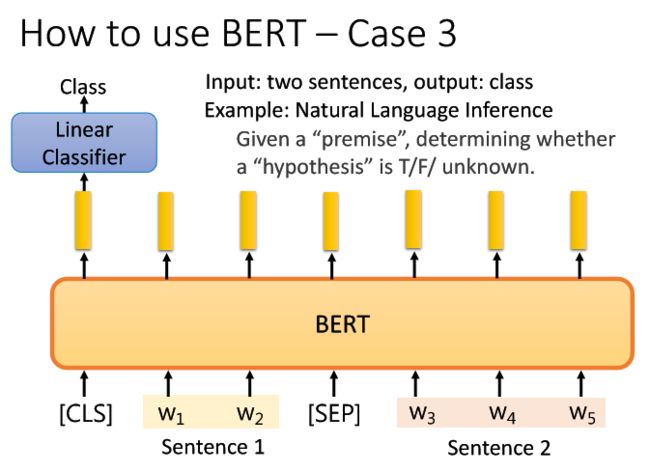
第三种,假设当前任务是input输入两个句子,输出class。举例现在要进行自然语言预测,让机器根据premise前提,预测这个hypothesis假设是True还是False还是unknown不知道。实际上,我们可以把这个任务当成三分类问题。
训练过程:
1)在一个sentence前设置特殊符号[CLS],然后在要输入的两个sentence中间设置[SEP]分隔符号;
2)将两个sentence连同特殊符号一起输入到BERT中;
3)将[CLS]输入BERT后得到的embedding,再把它输入linear Classifier中,得到class。
5.3.4Case4

第四种,假设当前任务是Extraction-based Question Answering (QA) (E.g. SQuAD),即基于抽取的问答。给定模型一篇文章,现在问它一些问题,希望能够得到正确答案。不过我们这里的问题设置为特殊情况,即一定能够在文章中找到答案。
1)将文章和问题分解为一个个token组成的sequence,如D={},Q={}
2)现有QA的Model,将1)的sequences输入到这个模型中,输出得到两个整数s,e
3)通过2),我们将现在从文章中寻找问题的答案A,缩小范围将它们限制为到。
如图所示,假设gravity的token序号是17,即,我们现在有一个问题通过QA Model后得到的s=17,e=17,那么答案就是为gravity;
同理,假设within a cloud的序号顺序是77到79,即到,我们现在有一个问题通过QA Model后得到的s=77,e=79,那么答案就是为within a cloud。
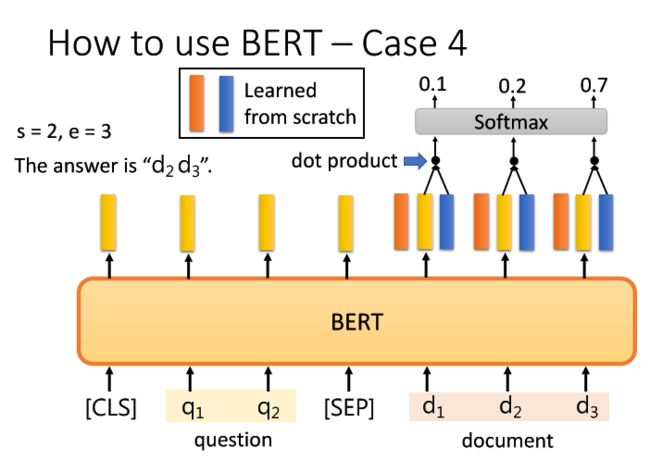
5)同理,将蓝色的vector(如图,用于决定)分别和document训练后的embedding去做dot product;
6)经过dot product计算后都会得到各自的scalar,将它们继续通过Softmax层得到各自的分数,然后比较它们之间的分数,选出最大值。假设这里的的分数最高为0.7,那么e=3;
7)那么得到的答案就是到.
5.4What does BERT learn?
https://arxiv.org/abs/1905.05950
https://openreview.net/pdf?id=SJzSgnRcKX
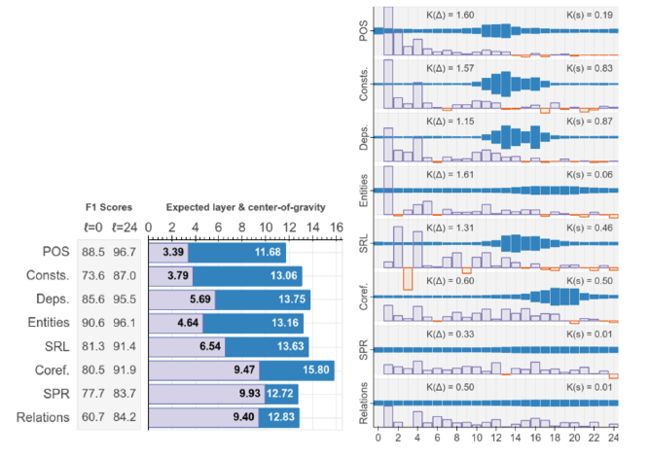
这张图显示了BERT从0-24层的层数在针对不同的NLP任务上的表现。
5.5BERT在多语言上的表现
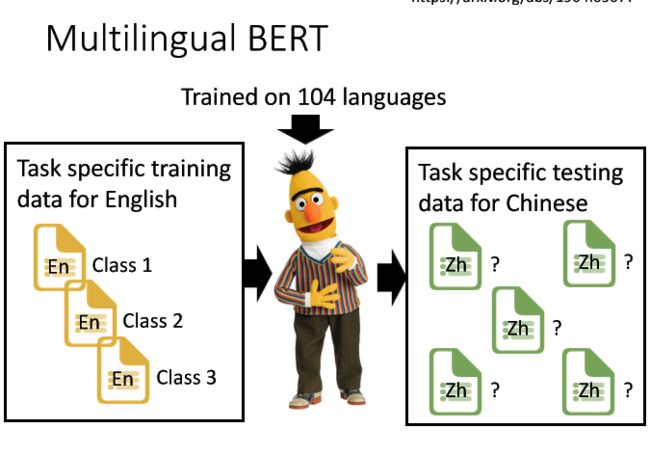
https://arxiv.org/abs/1904.09077
它在对104种语言的维基百科进行训练后,它学到了不同语言间的对应关系。在学习了英文文章的分类后,它自动的学会了中文文章的分类。
6.Generative Pre-Training (GPT)
https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf

从这张图中我们可以GPT-2和其他预训练模型在参数上的对比:
- ELMO:93.6M参数
- BERT:340M参数
- GPT-2:1542M参数
而所谓的GPT,它其实就是Transformer的Decoder。
6.1GPT的训练过程
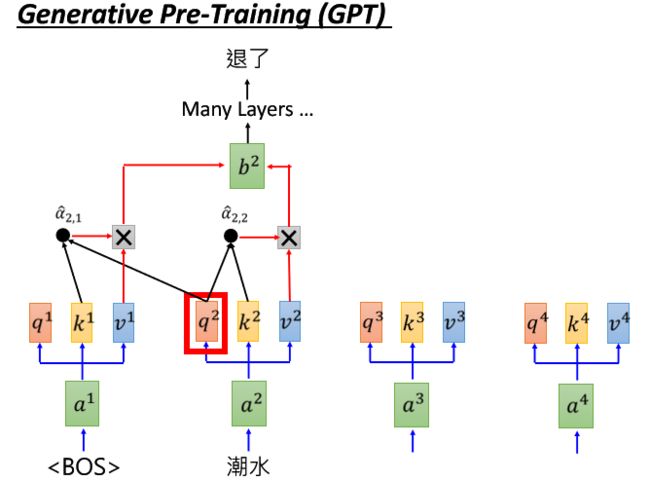
我们简单的描述下GPT的训练过程:这里我们input
1)首先输入[BOS](begin of sentence)和潮水,通过Word Embedding再乘上matrix W变成a1到a4,然后把它们丢进self-attention 层中,这时候每一个input都分别乘上3个不同的matrix产生3个不同的vector,分别把它们命名为q,k,v。
q代表的是query (to match others用来去匹配其它的向量)
k代表的是key (to be matched用来去被query匹配的向量)
v代表的是value(information to be extracted用来被抽取的信息的向量)
2)现在要做的工作就是用每个query q 去对每个 key k做attention(吃2个向量,输出就是告诉你这2个向量有多么匹配或者可以说输入两个向量输出一个分数\alpha(而怎么去吃2个向量output一个分数,有很多不同的做法))。这里要预测潮水的下一个词,所以乘,乘上,乘上再经过soft-max分别得到到 。
3)我们用和每一个v相乘,和相乘加上和相乘。以此类推并相加,最终得到。
4)然后经过很多层的self-attention,预测得到”退了”这个词汇。
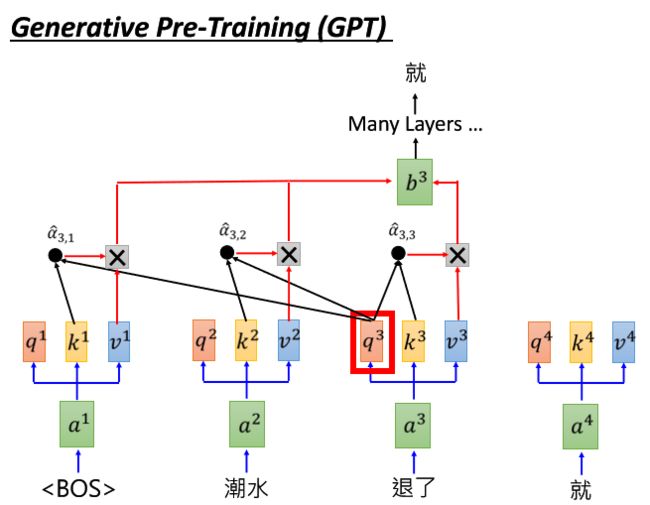
同理,现在要预测”退了”的下一个词汇,按照前面的流程可以得到,然后经过很多层的self-attention层,得到”就”这个词汇。
6.2GPT的神奇之处
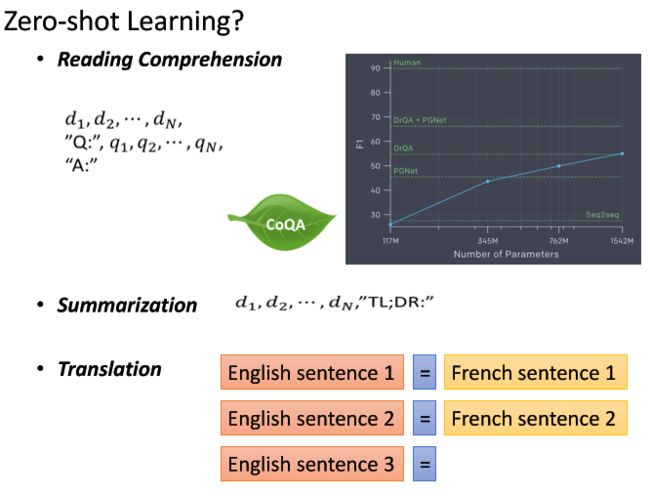
GPT的神奇之处在于它可以在完全没有训练数据的情况下,就可以做到阅读理解,摘要,翻译。折线图中显示了它在参数量上升的情况下,F1的值的效果。
下面就对各种模型做一个简单的总结:

1.Transformer的问题:
word Embedding 无上下文
监督数据太少
解决方法:
Contextual Word Embedding
- 无监督
- 考虑上下文的Embedding
- 每个word token(标记词)拥有自己的Embedding,word toekn的embedding也取决于它的上下文
2.ELMo(Embeddings from Languages Model)
- 多层双向的LSTM的NNLM
- RNN-based language models(trained from lots of sentences)
ELMo的问题:
Contextual Word Embedding作为特征
不适合特定任务
3.OpenAI GPT的改进
根据任务Fine-Tuning
使用Transformer替代RNN/LSTM
OpenAI GPT的问题:
单向信息流的问题
Pretraining(1)和Fine-Tuning(2)不匹配
解决办法:
Masked LM
NSP Multi-task Learning
Encoder again
Tips:
- 使用中文模型
- max_seq_length可以小一点,提高效率
- 内存不够,需要调整train_batch_size
- 有足够多的领域数据,可以尝试Pretraining