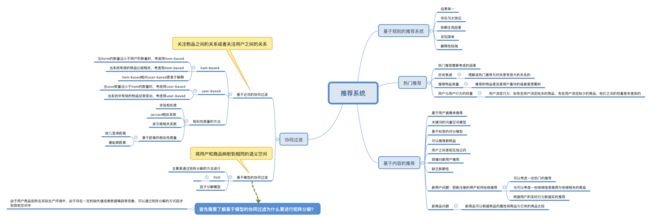
1.基于规则的推荐系统
1.1优点:
1.1.1简单直观;解释性强
1.1.2开发以及维护简单
1.2缺点:
1.2.1结果单一。
1.2.2马太效应:马太效应是出自《圣经 马太福音》的一个典故,社会学中的一种强者越强弱者越弱的现象,也就是说推荐系统是否会使被关注的事物更加被关注,被忽视的事物更加被忽视。常用的协同过滤就有马太效应。比较简单的测试指标就是信息熵。
1.2.3较为依赖主观经验
2.热门推荐
2.1优点(同上)
2.2缺点:
2.2.1结果单一
2.2.2马太效应
2.3热门推荐需要考虑的因素:
2.3.1时效性:推荐的时效性很好理解。
2.3.2 推荐物品的质量:推荐物品的质量表示推荐给用户需要考虑用户对该物品是否感兴趣。
2.3.3用户与用户行为的权重:用户和用户行为的权重表示某个用户多次访问与某个用户很少访问两者是有很大的区别的
3.基于内容的推荐系统
利用用户的已知属性或者兴趣偏好,与物品内容的属性进行匹配,以此为用户推荐新的感兴趣的物品。
基于用户画像的推荐
基于关键词向量的推荐
3.1优点:
用户之间是相互独立的
可解释型较强
可以推荐新的物品
3.2缺点:
3.2.1缺乏新颖度
3.2.2很难对新用户进行推荐(冷启动较弱)。这里可以考虑给热门推荐;或者根据用户的地域信息给出相应的推荐;或者根据用户实时行为数据进行实时推荐
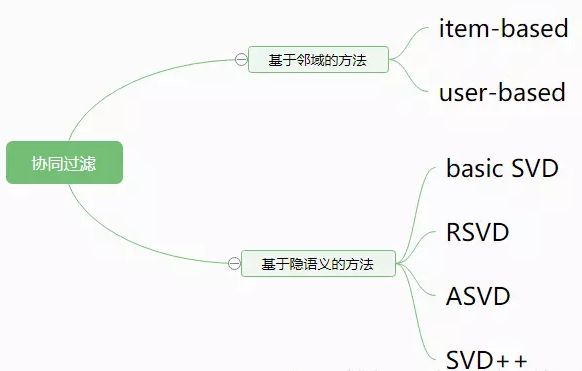
4.协同过滤
4.1基于近邻的协同过滤:他关注的是用户之间的相似度或者是物品之间的相似度。
4.1.1 Item-based
定义:基于Item-based推荐表示的是根据物品的相似性,某个用户买了某个物品后,通过物品的相似性得到一些与该物品相类似的商品推荐给该用户。对于物品 A,根据所有用户的历史偏好,喜欢物品 A 的用户都喜欢物品 C,得出物品 A 和物品 C 比较相似,而用户 C 喜欢物品 A,那么可以推断出用户 C 可能也喜欢物品 C。
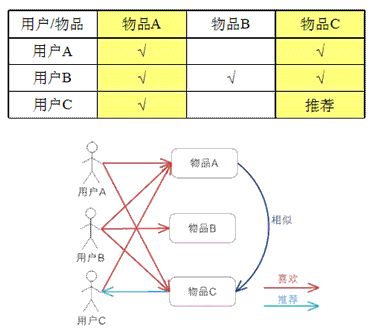
应用场景:
当Item的数量远小于User的数量时,考虑用Item-based
当Item的比较稳定时,考虑用户Item-based
4.1.2 User-based
定义:基于user-based推荐表示的是根据用户的相似度,某个用户购买了相关的商品时,与该用户相似的用户也购买了那些物品推荐给他。 对于用户 A,根据用户的历史偏好,这里只计算得到一个邻居 - 用户 C,然后将用户 C 喜欢的物品 D 推荐给用户 A。
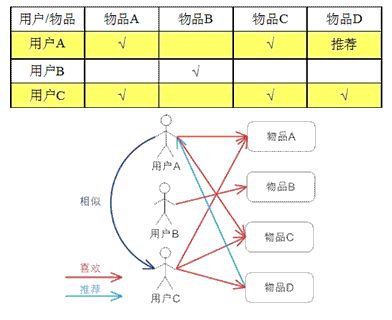
应用场景:
当user的数量远小于Item的数量时,考虑用User-based
当Item不是特别稳定时,考虑用User-based
4.1.3 相似度的计算方法
余弦相似度
皮尔森相关系数
jaccard相似系数
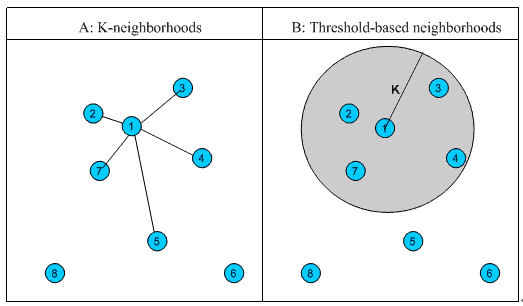
不论邻居的“远近”,只取最近相似的 K 个,作为其邻居。如图 中的 A,假设要计算点 1 的 5- 邻居,那么根据点之间的距离,我们取最近的 5 个点,分别是点 2,点 3,点 4,点 7 和点 5。但很明显我们可以看出,这种方法对于孤立点的计算效果不好,因为要取固定个数的邻居,当它附近没有足够多比较相似的点,就被迫取一些不太相似的点作为邻居,这样就影响了邻居相似的程度,比如图 1 中,点 1 和点 5 其实并不是很相似。
4.2基于(隐语义)模型的协同过滤
4.2.1将物品和用户映射到相同的语义空间进行计算相似度。主要用到的方法就是矩阵分解。
4.2.2因子分解
4.2.3 SVD,SVD++
ALS矩阵分解(Spark MLlib)
应用矩阵分解的原因是由于用户和物品构成的矩阵在实际的应用场景中,往往都是稀疏的或者存在缺失值的情况。这个时候很难补充或者很难准确的给出相应的物品推荐,并且复杂度较高。通过矩阵分解可以解决这类问题。在FM算法当中也有用到类似的原理。
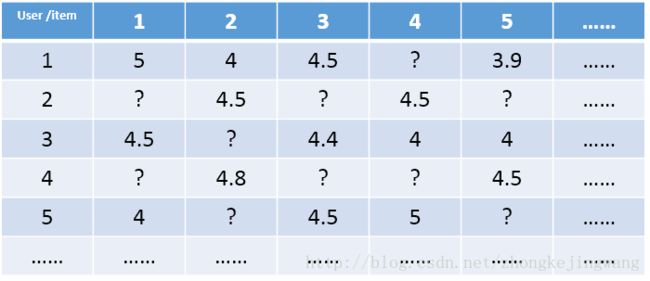
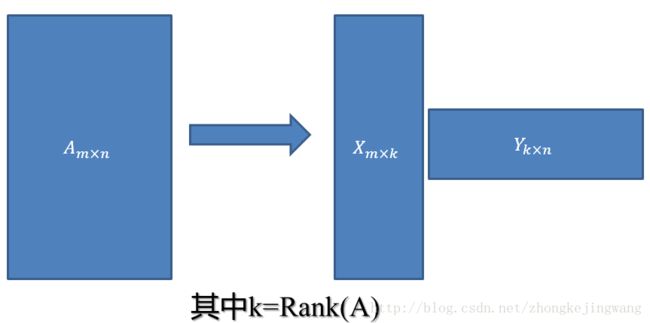
把这个评分矩阵记为R,其中的元素表示user对item的打分,“?”表示未知的,也就是要去预测的,现在问题:如何去预测未知的评分值呢?对任意一个矩阵A,都有它的满秩分解:
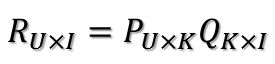
SVD++:户对商品的打分不仅取决于用户和商品间的某种关系,还取决于用户和商品独有的性质,我们希望将这些性质用基线评分(baseline estimates)来表示。例如,我们希望得到小明对电影《泰坦尼克号》的评分,首先我们得到所有电影的评分均值$\mu$为3.7分。然后,我们得知该电影非常好看,评分可能比平均分高0.5.另外,小明是一个非常苛刻的观众,评分可能比平均分低0.3.我们得到小明对电影《泰坦尼克号》的基线评分3.7+0.5-0.3=3.9分。SVD++将损失函数第一项为总的平均分,bu为用户u的属性值,bi为商品i的属性值,再加入惩罚项目。
4.3 深度学习与矩阵分解
很多推荐系统大会有两派意见:
不鼓励使用深度学习(神经网络)在推荐系统中,因为可解释性较差;
另外鼓励的原因是高效,准确,大厂都在用。
RecSys 2019最佳论文认为现有深度学习加推荐算法带来的基本上都是伪提升?《Are We Really Making Much Progress? A Worrying Analysis of Recent Neural Recommendation Approaches》阐述了两者冲突。
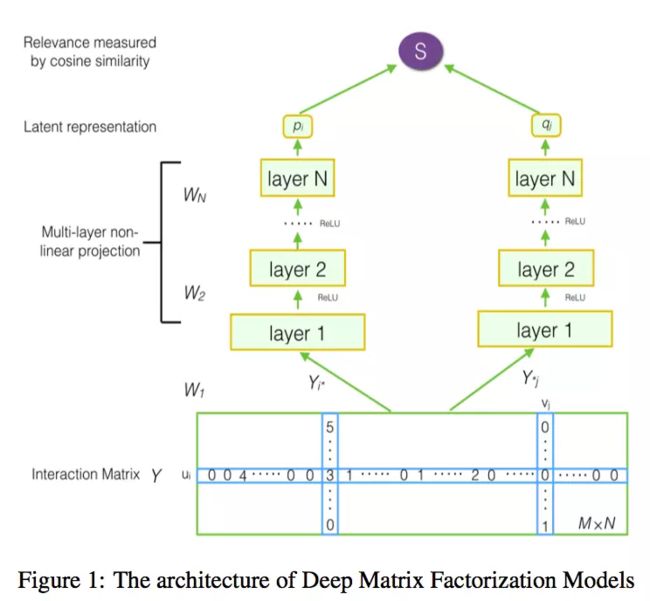
5.推荐系统的一般步骤
5.1召回
根据用户长期稳定的兴趣和即时的目标,得到可以推荐给用户的物品候选集
结合具体的业务逻辑进一步得到候选集
5.2排序
得到候选集后,需要对候选集中的物品进行排序。
传统的排序方式:相关系数,重要性
point-wise,pair-wise,list-wise(迟点另开章节单独评测)三者排序中,关于ndcg,pk和rmse的评测参考。
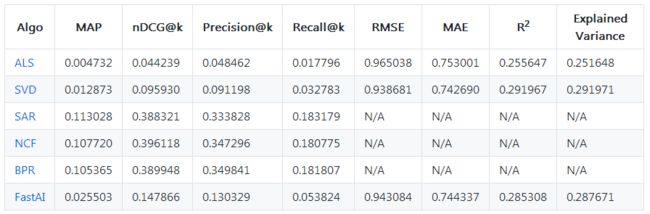
这里排序的模型可以考虑使用的特征类型:用户特征、物 品特征、用户-物品交互 特征、场景特征等
5.3过滤/规则匹配
过滤一些bad case
根据用户的历史行为过滤一些用户已经购买过的物品
5.4推荐系统的评价指标
正确率,召回率,F1值,ROC曲线,AUC值
转化率相关的指标
销售额
排序相关的指标
用户体验相关的指标
覆盖率:用户的覆盖率和物品的覆盖率
参考:
svd和als损失函数的分析:https://www.jianshu.com/p/fc7391471d39
推荐系统源码(数据,benchmark,cpu等占用)分析:https://github.com/microsoft/recommenders
优化的ALS和正则svd:https://blog.csdn.net/Hemk340200600/article/details/88633646#2RSVD_48
带正则表达的svd源代码:https://github.com/alabid/PySVD
推荐系统中矩阵分解的总结:https://blog.csdn.net/qq_19446965/article/details/82079367
ALS和SVD源代码分析(spark):http://spark.apache.org/docs/1.5.2/mllib-collaborative-filtering.html#collaborative-filtering
推荐系统粗分类:https://blog.csdn.net/lipengcn/article/details/80373744
推荐系统细分类https://blog.csdn.net/evillist/article/details/76269733
point-wise,pair-wise,list-wise:https://blog.csdn.net/weixin_34005042/article/details/86264976
point-wise,pair-wise,list-wise:https://www.cnblogs.com/ljy2013/p/6889881.html
SVD++,ASVD:https://blog.csdn.net/evillist/article/details/76269733
ALS和SVD具体协同操作:https://blog.csdn.net/Hemk340200600/article/details/88633646#2RSVD_48
常见的SVD优化:https://blog.csdn.net/qq_19446965/article/details/82079367
深度矩阵分解模型理论及实践:https://www.jianshu.com/p/63beb773f100
RecSys 2019最佳论文:https://www.zhihu.com/question/336304380/answer/759069150
2019年快速ALS的代码作者: appearance or functional complementarity: Which aspect affects your decision making?:https://www.sciencedirect.com/science/article/pii/S0020025518308077
基于属性的相似度度量来捕获项目之间的隐式关系:https://link.springer.com/chapter/10.1007/978-3-319-11749-2_1
何向南的关于推荐系统的文章:http://staff.ustc.edu.cn/~hexn/
RecSys 2019 - DeepLearning RS Evaluation:https://github.com/MaurizioFD/RecSys2019_DeepLearning_Evaluation