Clustering
聚类K-means
聚类是机器学习和数据挖掘领域的主要研究方向之一,它是一种无监督学习算法,小编研究生时期的主要研究方向是“数据流自适应聚类算法”,所以对聚类算法有比较深刻的理解,于是决定开一个专题来写聚类算法,希望可以为入门及研究聚类相关算法的读者带来帮助。聚类可以作为一个单独的任务,用于寻找数据内在分布结构,也经常作为其他学习任务的前驱过程,应用十分广泛。今天,小编就带你探索聚类算法的奥秘,并介绍第一个聚类算法Kmeans。
Q:什么是聚类?
A:聚类是按照某一种特定的标准(相似性度量,如欧式距离等),把一个数据集分割成不同的类,使得同一个类中的数据对象的相似性尽可能大,不同类之间的差异性也尽可能大,如下图是一个聚类结果的可视化:
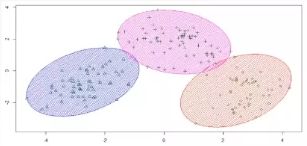
聚类有非常广泛的应用,比如根据消费记录发现不同的客户群,对基因表达进行聚类可以研究不同种群中的基因特征,对文本进行聚类可以快速找出相关主题的文章等。
Q:如何度量相似性?
A:常用的相似性度量方式主要有以下几种:
-
欧式距离:
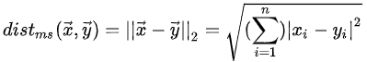
-
Minkowoski距离:
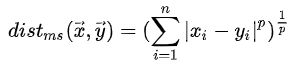
-
曼哈顿距离:
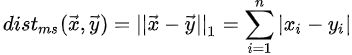
-
余弦距离:
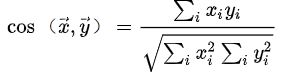
-
Jaccard相似系数:
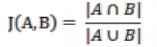
-
相关系数:
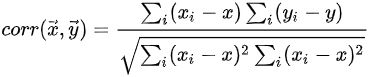
Q:常用的聚类算法有哪些?
A:
-
基于划分的聚类:k-means,mean shift
-
层次聚类:BIRCH
-
密度聚类:DBSCAN
-
基于模型的聚类:GMM
-
Affinity propagation
-
谱聚类
上面的这些算法只是简单的引入聚类的概念,在接下来的专题中,我们将具体探讨经典的聚类算法,研究它们的原理,分析优缺点,应用场景等。今天,我们就来学习最经典的一个聚类算法Kmeans
K-means
Kmeans聚类原理
Kmeans算法的思想很简单,根据给定样本集中样本间距离的大小将样本集划分为k个簇(类),使得每个点都属于距离它最近的那个聚类中心(即均值means)对应的类。之所以叫kmenas是因为它可以发现k(用户指定)个簇且簇中心用属于该簇的数据的均值来表示。
Kmeans聚类算法
数据集合X={x1,...xn}中每个样本都是d维无标签数据,kmeans聚类的目标是将这n个点分到k个簇使得簇内点到簇中心点(均值)的距离平方和最小,即求下列目标函数的最优解
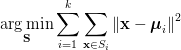
其中μi就是簇Si中点的均值。
然而解上式并不是一个简单的问题,因为它是一个NP难问题,所以kmeans算法采用一种启发式的迭代求解方法:
首先随机选择k个对象作为初始的聚类中心,然后计算每个样本到各个聚类中心的距离,并分配给距离它最近的聚类中心。一旦对象全都被分配了,重新计算每个簇的中心(均值)作为下一次迭代的新的中心点。这一过程将重复进行直到满足下列任一条件:
-
没有对象被重新分配给新的类;
-
聚类中心不再发生变化;
-
误差平方和局部最小。
Tips:
-
k值的选择:一般来说我们可以根据数据的先验选择一个合适的k,如果不行,则可以通过交叉验证选择合适的k;
-
初始化k个中心点:可以随机选择,也可以每次选择距离其他中心点尽可能远的点作为中心;
Kmeans++算法
前面我们也提到了K个初始化中心的选择对聚类算法的运行结果和时间有很大影响,Kmeans++算法提出了对随机化初始化聚类中心的优化:
-
从输入的数据点集合中随机选择一个点作为第一个聚类中心μ1;
-
对于数据集中的每一个点xi,计算它与已选择的聚类中心最近的一个的距离D(xi);
-
选择D(xi)较大的点作为新的聚类中心;
-
重复b,c直到找出k个聚类中心;
Kmeans算法小结
优点:
-
原理简单,实现简单,收敛速度快;
-
聚类效果比较好;
-
可解释性强,直观;
-
只有一个参数k;
缺点:
-
k的选择对聚类效果影响较大;
-
对于不是凸的数据集比较难收敛;
-
类别不均衡数据集聚类效果不好;
-
结果局部最优;
-
对噪声点敏感;
-
聚类结果是球形。
小结:
今天是聚类算法学习的第一部分,内容虽然简单但是很重要,kmeans算法常常作为其他算法的基础,如之前的半监督学习以及之后会讲的谱聚类算法都会用到。相信今天的学习你一定也有了收获,聚类专题的下一篇内容是谱聚类,敬请期待!

扫码关注
获取有趣的算法知识

