R&S | 爱奇艺搜索启发
最近看了很多大公司在搜索系统中的有关技术和开发,本次选择爱奇艺,谈谈自己的一些启发和看法。
内容来自:AI先行者大会《爱奇艺搜索排序模型迭代之路》,报告人是陈英傑前辈,PPT来源于datafuntalk,本次的报告主要针对的是文本类搜索(区分与现在比较时髦但是尚不成熟的语音搜索吧),里面有大量NLP方面的工作,另外还有很多和搜索推荐排序有关的工作。
目标约束
对于一个完善的搜索系统,包括但不限于下面的几个约束条件:
- 精确匹配,根据用户搜索,进行精确匹配,并对结果进行排序
- 内容生态,搜索系统本身是一个内容分发的渠道,需要囊括多种资源,而对爱奇艺本身而言则是对视频资源的囊括和整理
- 智能分发,权衡用户和版权方利益,并对原创进行鼓励,扶持优质资源,方式劣币驱逐亮币
- 冷启动,给新用户、新资源鼓励
- 搜索多样性,与推荐的多样性类似。
基本架构
直接上图吧。
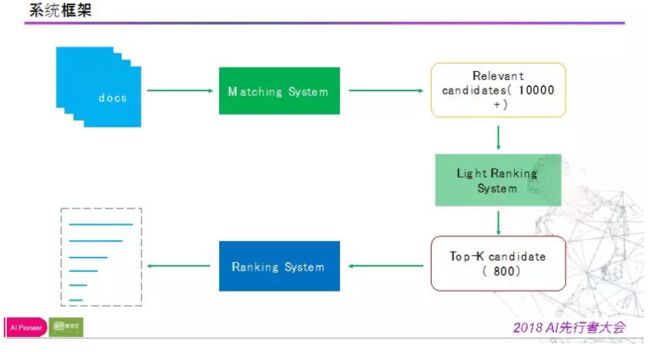
相比很多当前使用的推荐系统,乍看之下十分类似,但在细节处还是会有所不同的,有一个特点就是进行了两次排序吧。废话不多说继续看。
与一般推荐系统类似的是都是采用“召回+排序”两个阶段,这个策略已经得到了业内的普遍认可。
召回
召回阶段,搜索与推荐的核心不同就再此体现,搜索的召回是需要基于用户自己输入的信息的,因此召回只能通过改写、纠错等方式进行召回,在爱奇艺里,分为了改写纠错、基础召回、知识图谱和语义匹配等多方面内容。
基础相关性
基础相关性是搜索系统本身非常需要考虑的点,用户所搜即所得,需要的就是把相同或相似的内容给于用户。
在进行基础相关性时,首先需要考虑的就是精确匹配,匹配时要考虑下面几个方面:
- 切词粒度,怎么切,专有名词等的处理。
- 词权重,不同词汇的重要性不懂,计算相似度就会有所不同,影响最终的相似度得分。
- 命中域,即倒排索引下的归并处理
- 命中位置,不同位置可能有不同的关键词
演讲过程中重点提到,此模块需要很大的工作量,是一个不停解决bad case的过程。
而对于基础相关性解决不了的问题,总结有如下形式:
- 词汇的同义多义问题(多意图)
- 语言表达差异(K记和肯德基...)
- 输入错误兼容(水浒转)
- 泛语义召回(今天吃什么)
语义相关性
语义相关性在基础相关性出现问题时用于解决,爱奇艺对此块的总结如下所示。
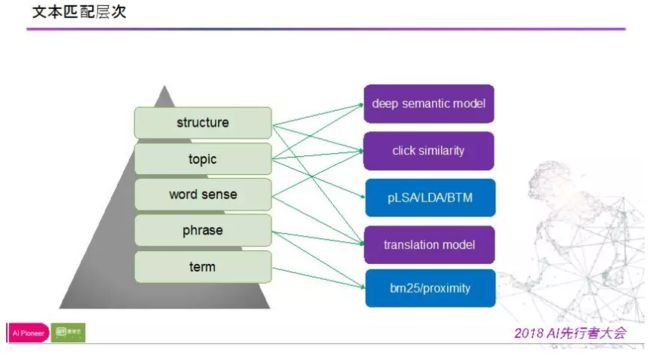
语法分析可以分为词、词组、词义、主题、结构几个方面,并有对应的方式解决,甚至形成比较完整的系统。下面慢慢展开里面的内容讨论。
机器翻译
机器翻译是目前在NLP领域比较流行的课题,在深度学习、文本生成等研究出现后逐渐出现大量解决方案,成为姐姐语义相关性的重要手段,举个例子:
吃鸡游戏 -> 绝地求生
通过类似的方式可以生成召回内容,在开发上减少同义词表的工作量,在用户角度不用“精心设计”自己的搜索语句也能有较好的结果。
而具体的方案可以如下所示。
通过用户query和点击doc构建机器翻译平行语料,然后做词对齐和短语对齐(报告强调此处不要求准确性,而是要求可解释性,因此DNN不一定要用),构建映射形式,对发现的噪音,在进行标注。
翻译过程需要给出翻译概率,同时要通过语言模型判断句子通顺,再结合其他特征甄别有效性。
点击相关性
具体是否相关,可以考虑将这个判断权还给用户,通过用户的点击行为判断我们给出的搜索结果是否和用户检索内容相关,具体计算方式就是将两者尽可能的映射到一个空间下。
通过搜索日志构建“搜索-点击”二部图,通过分析共同映射的搜索语句来分析两个语句的相似性。
深度学习
深度学习一直以来都是大家最快能想到的手段,但从实际看来承担的内容比较有限,然而却可能是一些最难的任务。
深度语义匹配一般有两种方式,一种是基于表达,另一种是基于交互。
- 基于表达:词向量或句向量求相似性
- 基于交互:query和doc每个词计算相似性得到相似性矩阵然后进行映射计算
根据报告者,爱奇艺更倾向于前者,通过抽取正负样本,多粒度切词,用emb做加权平均得到文本串的向量模式(可以理解为句向量吧),再通过全连接计算相似性,具体网络形式如下,感觉还是非常明白的:

里面有几个关键点吧:
- 分别和正类负类计算相似性,构建损失,因此此处的正负类样本很重要
- BOW+IDF形式可以考虑实行
小结
汇总起来,语义相关性主要是对基础相关性的拓展,用于解决一些比较复杂且有一定规律的badcase,里面既有学术界给出的方案,也有通过A/B test(这个玩意看来有必要单独写篇文章谈谈啊)得到的结果,其整体结构如下:

排序
召回后就要进行排序,这是我们谈过很多次的问题,根据报告者,其演进过程主要是策略排序,学习排序,深度学习模型。依稀感觉这个演进过程和高不高端没关系,而是和具体问题场景,用户资源增加有关。
策略排序
策略排序主要考虑的是相关性、质量度、时效性、点击行为等几个特性,构建的基于策略规则的打分排序系统,实质上该版本已经能够解决大部分业务问题了。
学习排序
有较多用户行为可供标注,ID类特征可加入,资源丰富,信息丰富等,为学习排序提供了可能。
对于学习排序的结构在这里,此处不赘述了。
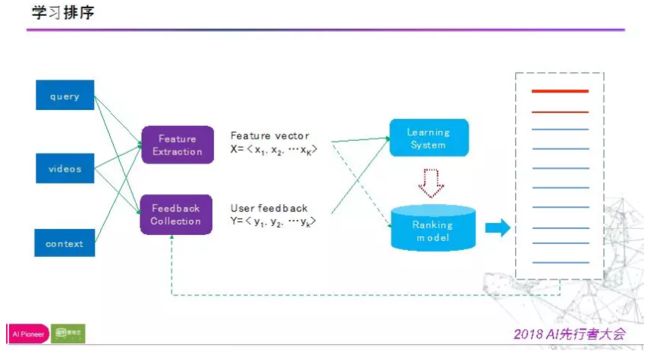
此时会面临一些比较困难的问题,目标上、样本上、特征上与模型上。
目标上,最初使用的是list wise,目标是优化NDCG。
样本上,正样本通过观看时长、观看时间占比、观看时长分布三个因素分三级标注,负样本用skip above+相关性负采样+后排位负采样构建。
特征上分为query维度(意图识别,时效性偏好,频道偏好,类型偏好),doc维度(质量特征,类别特征,新鲜度,来源),相关性特征维度(命中特征,bm25,translate sim等),后验统计特征维度(点击率,观看时长,点击质量)和稀疏特征维度(ID类)。
在稀疏类特征加入前,使用的是lambda-mart模型,而对于稀疏特征有较好性能的LR、FM系的模型又对特征组合不敏感,因此后续进行了模型融合,在经历一系列尝试后效果提升不明显甚至负向,因此后续引入了DL。
深度学习
先上图。
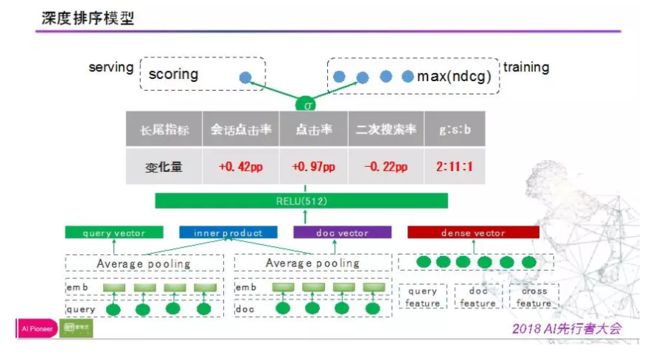
query和doc进行句向量化表达做点积得到inner product,稠密特征用gbdt处理,然后组合进行全连接,最大化NDCG做损失进行训练,线上测试结果正向明显。
总结
在总结中,报告者指出,一般地搜索系统,主要沿着两条路迭代,一个是召回,让召回尽可能多而全,另一个是排序,尽可能准,让用户更快找到自己所需的内容。
我的总结
搜索系统相比推荐系统有很多差别,核心在于搜索系统有非常明显的用户意图,而这个意图都凝练在一句简单的query上,于是有了不一样的挑战和问题。
- query的挖掘,改写和召回,围绕query有更多复杂的问题
- 对规则的依赖会比推荐系统本身更多,因为用于意图相比推荐系统更为明确
- NLP方面的工作由于query的出现而增加
- 在冷启动上,运用策略和方法将更加高效
参考文献
[1] 陈英傑,AI先行者大会《爱奇艺搜索排序模型迭代之路》
[2] datafuntalk,「回顾」爱奇艺搜索排序模型迭代之路。(这是一篇公众号,为会议的记录,图片基本来源于此)