Log
- 【170409】完成了 Python 版代码的书写(01),未写笔记
- 【170410】完成了 01 版笔记,完成了 02 版代码的书写和笔记
- 【170415】完成 03 版优化
- 【170416】看完最优解,写下思路。2 种 Java 解法里有一种暂时没明白
- 【170808】用一个新思路重新编写了 Python 版代码(04)
题目
Longest Common Prefix
【题目类型备注】
字符串
提交
01
【语言】
Python
【时间】
170409
【思路】
〖复杂度?〗O(mn),其中 m 是字符串的长度,n 是字符串数组 strs 的长度
〖大致流程?〗
- 要求最长公共前缀,因此应该有一部分代码用于字符串之间的比较、求公共前缀(即两个字符串从头进行比较,直到对应位置的字符不同为止,之前的部分为公共前缀),这部分可能可以抽象为一个模块(函数)
- 考虑到「最长公共前缀」的意思是:所有字符串共有、最长的、从开头开始的子字符串,因此
- 首先求字符串
strs[0]与strs[1]的公共前缀,记为substr_old(作为第一轮的「截止上一轮的最长公共前缀」) - 然后从
strs[1]开始,遍历到strs[-1](即倒数第二个字符串),每次求遍历到的当前字符串,与下一个字符串之间的公共前缀,记为substr_new(「本轮的公共前缀」) - 假设
substr_old是最长公共前缀,那么substr_new的长度一定不小于substr_old的长度;否则,意味着「最长公共前缀」中有某些字符,不在当前字符串与下一个字符串之间的公共前缀内,这样的话,substr_old就应该被substr_new替换
- 〖什么时候停?〗
- 除非遇到特殊情况,否则遍历完倒数第二个字符串之后(即:比较过倒数第二个字符串 与 最后一个字符串 之后),得到的
substr_old即为所求
〖特别注意?〗
+ 要考虑到给定的字符串可能为空串、给定的字符串集合可能是空集、所有的字符串之间没有公共前缀(就是说,所有字符串,至少首位字符是不同的)〖能否剪枝?〗暂时看不出剪枝的可能
【代码】
class Solution(object):
def commonPrefix(self, str_a, str_b):
#print "str_a: {}, str_b: {}".format(str_a, str_b)
substr = ""
if len(str_a)>len(str_b):
length = len(str_b)
else:
length = len(str_a)
k=0
while ((k len(substr_new):
substr_old = substr_new
substr_new = self.commonPrefix(strs[-2], strs[-1])
if ("" == substr_old) or ("" == substr_new) or (substr_old[0] != substr_new[0]):
return ""
if len(substr_old) > len(substr_new):
substr_old = substr_new
return substr_old
【结果】
运行时:62 ms
报告链接:https://leetcode.com/submissions/detail/99591515/
不知道其他拥有 LeetCode 帐号的人能不能看到该报告,所以顺便附图如下:
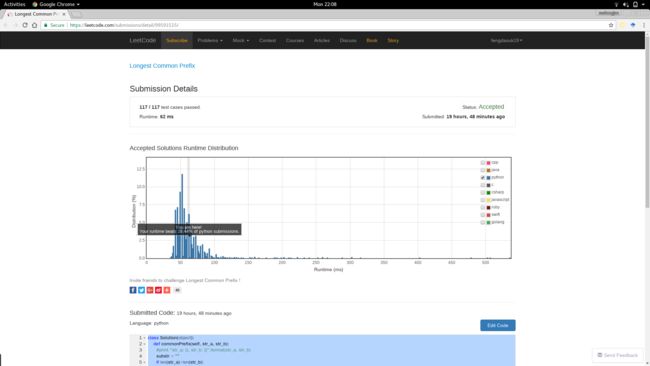
但是其实这份代码极丑无比,注意到上面使用了多个 print 用于 debug……勉勉强强处理了一些特殊情况后才完成了程序。有待后续重新梳理逻辑或检查细节,看是否能够剪掉一些不必要的代码。
02
【语言】
Python
【时间】
170410
【思路】
检查 01 版的代码,会发现很奇怪的重复:即明明在 for 循环中似乎已经遍历了 strs[1:-1],并在每次循环结束前处理了特殊情况,为何同样的特殊情况处理代码需要在最终 return 前再次运行一遍才不会出错?
例如,以上一次的代码而言,若输入为 ["a", "a", "b"],答案应该是 "",但若删去 for 循环后、return 前的那部分特殊情况处理代码,将返回 "a"。这就让我很奇怪。于是我便在 for 循环内部加入了若干 print 语句,输出 substr_new 与 substr_old,惊讶地发现这唯一执行一次的循环(预期应该是 strs[1] 即 "a" 与 strs[2] 即 "b" 之间的比较),居然输出了 "a" 作为公共前缀。于是我多加了几个输出参数,包括输出了 i 与 i+1,然后才明白了:
原来是对
for (i, item) in enumerate(strs[1:-1]):有了不恰当的预期!
我原本是希望循环开始时,i==1;但实际上 enumerate(obj) 执行后,是不管 obj 从哪里来的,直接把其首位元素作为第 0 位元素,从而第 1 轮循环中 i==0。这也就解释了为什么会出现上述这种怪异的情况。
知道了问题所在,就好办了。处理了下标问题,删去for 之后 return 之前的代码,重新提交。
【代码】
class Solution(object):
def commonPrefix(self, str_a, str_b):
substr = ""
if len(str_a)>len(str_b):
length = len(str_b)
else:
length = len(str_a)
k=0
while ((k len(substr_new):
substr_old = substr_new
return substr_old
【结果】
运行时:79 ms
报告链接:https://leetcode.com/submissions/detail/99685590/
不知道其他拥有 LeetCode 帐号的人能不能看到该报告,所以顺便附图如下:
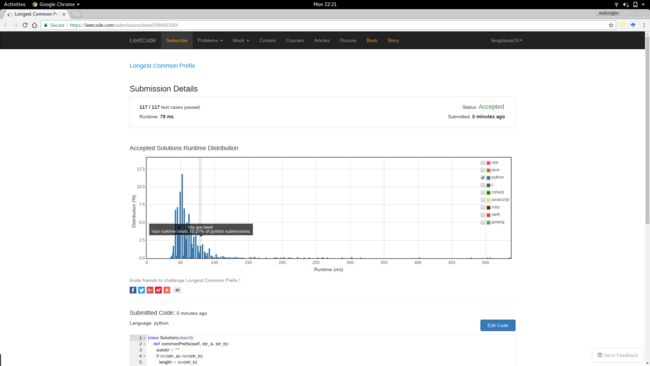
虽然慢了一点,不过总算是处理完成了
03
【语言】
Python
【时间】
170415
【思路】
基本算法思路与之前一致。这里仅阐述优化思路:
在得到 strs[0] 与 strs[1] 之间的公共子串 commonPrefix后,只要比较 commonPrefix 和 strs[i] 即可;若提前发现不同,截断到不同位置。最后返回即为所求。
当然,有一些特殊情况也需要处理的,例如输入为空,或者输入为若干单字符,输入仅有 1 个字符等等问题,不再赘述。
【代码】
class Solution(object):
def longestCommonPrefix(self, strs):
"""
:type strs: List[str]
:rtype: str
"""
if len(strs) == 0:
return ""
elif len(strs) == 1:
return strs[0]
elif (len(strs[0]) == 0) or (len(strs[1]) == 0):
return ""
commonprefix = ""
(i, j) = (0, 0)
while (i < len(strs[0])) and (j < len(strs[1])):
if strs[0][i] == strs[1][j]:
commonprefix += strs[0][i]
(i, j) = (i+1, j+1)
else:
break
if (len(strs) == 2) or ("" == commonprefix):
return commonprefix
length = len(commonprefix)
for s in strs:
if len(s) == 0:
return ""
elif len(s) == 1:
if s[0] == commonprefix[0]:
commonprefix = s[0]
length = 1
continue
else:
return ""
(i, j) = (0, 0)
while (i < length) and (j < len(s)):
if commonprefix[i] == s[j]:
(i, j) = (i+1, j+1)
else:
length = i
commonprefix = commonprefix[:length]
return commonprefix
【结果】
运行时:52 ms
报告链接:https://leetcode.com/submissions/detail/100169585/
不知道其他拥有 LeetCode 帐号的人能不能看到该报告,所以顺便附图如下:
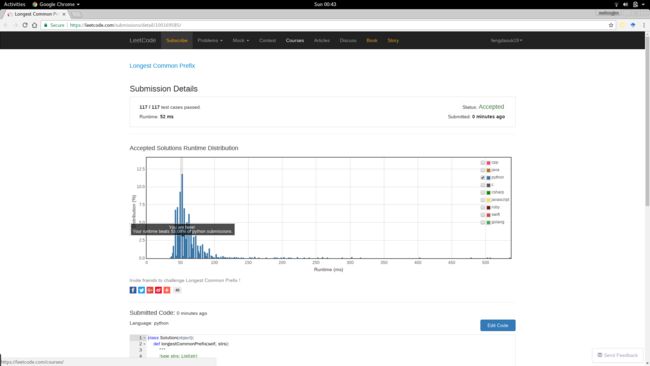
不是最优解。多尝试了几次,例如下述几个报告(1, 2, 3),这个优化思路似乎没有起到明显的作用。
还是需要研究一下参考答案。
04
【语言】
Python
【时间】
170808
【思路】
空间复杂度为 O(n)(n 为字符串数组长度),时间复杂度为 O(n)。
思路是:最长公共子串,即从首字符开始、在所有字符串中均出现的子串。那么只要:
- 从 0 位开始,遍历过字符串的每一位,每一次比较同一位置的所有字符;若在同一位置上只有一个字符,那么显然到当前位置为止,都是公共子串;直到某一位置,出现了 1 个以上的字符,说明最长串到前一位为止
- 由于最长子串不会超过所有字符串中最短的那个字符串,因此首先要确定最短字符串的长度,这是遍历字符位的上限
利用 Python 的 list 和 set,能很容易知道所有字符串在同一位置上的独立字符到底有多少。
【代码】
class Solution(object):
def longestCommonPrefix(self, strs):
"""
:type strs: List[str]
:rtype: str
"""
commons = ""
maxlens = [len(s) for s in strs]
if 0 == len(maxlens):
return commons
else:
maxlen = min(maxlens)
if 0 == maxlen:
return commons
for i in range(maxlen):
tset = list(set([s[i] for s in strs]))
if len(tset) > 1:
return commons
else:
commons += tset[0]
return commons
【结果】
运行时:35 ms
报告链接:https://leetcode.com/submissions/detail/112975588/
不知道其他拥有 LeetCode 帐号的人能不能看到该报告,所以顺便附图如下:
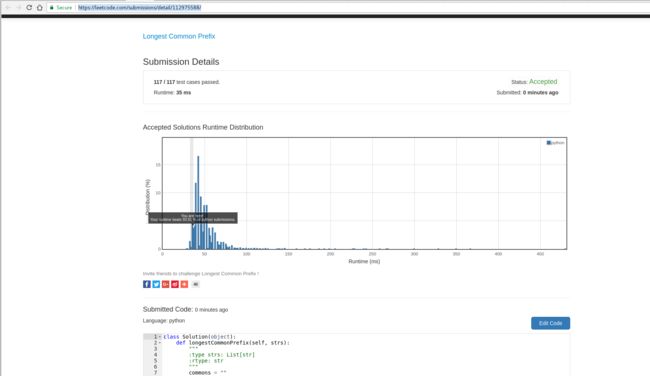
00
参考解法:
- C++
- 思路
- 只要是公共子串,就一定在每个子串中都出现。那么,直接比较
strs[0]中的字符与其余字符即可 - 明确上述情况下停止比较字符的条件
- 只要是公共子串,就一定在每个子串中都出现。那么,直接比较
- 思路
- Java
- 思路
- 排序后,逐一比较最短串与最长串之间的字符即可
- 提醒:这个解法中在最后的
return前需要补一个} - 问题:为什么
if语句中要增加b.length > i?首先,由于已经排序,这一条件必然成立;其次,删去该条件,也能 AC……不懂这句的意义,是否冗余?
- 另一个个 Java 解法还不懂:Java
- 思路
自己实现一遍最优解:
+[date-language] 。。。