介绍
Metal是2014年WWDC发布的.它是一个针对苹果设备(Mac,iPhone,iPad...)设计的图形框架,该框架被设计用来实现两个目标: 图形渲染和并行计算。
Metal 框架支持 GPU 加速高级 3D 图像渲染,以及数据并行计算工作。Metal 提供了先进合理的 API,它不仅为图形的组织、处理和呈现,也为计算命令以及为这些命令相关的数据和资源的管理,提供了细粒度和底层的控制。Metal 的主要目的是最小化 GPU 工作时 CPU 所要的消耗。
Metal 与OPenGL的区别
OpenGL的历史已经超过25年。基于当时设计原则,OpenGL不支持多线程,异步操作,还有着臃肿的特性。为了更好利用GPU,苹果设计了Metal。
Metal的目标包括更高效的CPU&GPU交互,减少CPU负载,支持多线程执行,可预测的操作,资源控制和同异步控制;接口与OpenGL类似,但更加切合苹果设计的GPUs。
Metal组件架构
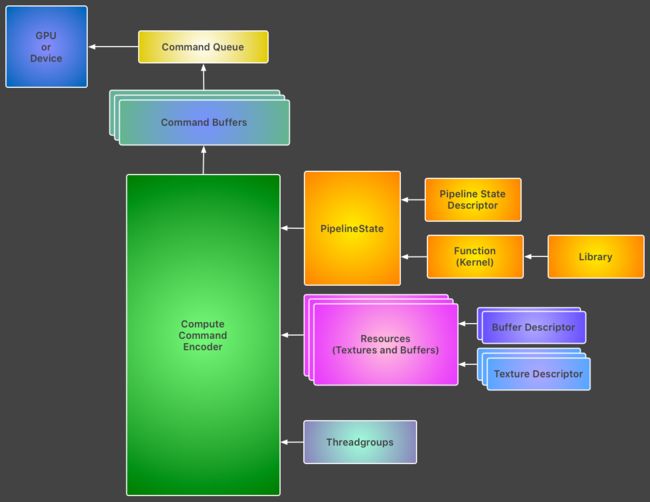
Metal
- MTLDevice (
渲染设备): 该对象代表GPU,使用MTLCreateSystemDefaultDevice获取默认的GPU.
import Metal
let device: MTLDevice? = MTLCreateSystemDefaultDevice()
- MTLCommandQueue (
命令队列): 由device创建,用于创建和组织命令缓冲区MTLCommandBuffer.
let commandQueue: MTLCommandQueue = device?.makeCommandQueue()
- MTLCommandBuffer (
命令缓冲区): 用于存储最终提交给GPU执行的编码命令MTLCommandEncoder.
let commandBuffer: MTLCommandBuffer = commandQueue.makeCommandBuffer()
- MTLCommandEncoder (
命令编码器): 在Metal中,有许多不同类型的命令编码器,每个命令编码器提供一组可以编码到缓冲区中的不同命令:-
计算命令编码器:符合MTLComputeCommandEncoder协议并用于编码计算任务的对象。 -
渲染命令编码器:符合MTLRenderCommandEncoder协议的对象,用于编码图形渲染任务。 -
内存管道编码器:符合MTLBlitCommandEncoder协议并用于内存管理任务的对象。 -
并行渲染命令编码器:符合MTLParallelRenderCommandEncoder协议的对象,用于并行编码的多个图形渲染任务。
-
// 计算命令编码器
let commandEncoder: MTLComputeCommandEncoder = commandBuffer.makeComputeCommandEncoder()
获得命令编码器后,可以使用它编码以下数据并行计算处理命令:
- setComputePipelineState(_:)传递包含将要执行的计算功能的.
- MTLComputePipelineState对象.
- setTexture(:at:)并setBuffer(:at:)指定保存计算功能的输入数据(或输出目标)的资源。索引表示相应参数表中每个资源的位置.
- dispatchThreadgroups(_: threadsPerThreadgroup:)以编码与线程组的指定数量的compute函数用于电网和每线程组的线程数.
- 最后,endEncoding()完成将计算命令编码到命令缓冲区.
- MTLComputePipelineState (
计算管道状态): 该MTLComputePipelineState协议定义了一个轻量级对象的接口,用于编码对已编译计算程序的引用。编译的计算程序是一组C ++函数,我们用它来处理缓冲区和纹理。
创建计算管道状态对象可能消耗很多资源,所以通常在应用程序初始化期间创建这些管道状态对象,并在整个生命周期内重用它们。
- Metal Library and Function(
Metal文件和着色器函数): 从项目中加载所以的.metal着色器文件,着色器文件中包含着色器函数.加载方法有以下几种:- newDefaultLibrary()
- makeLibrary(filepath:) throws
- makeLibrary(data:) throws
- makeLibrary(source:options:) throws
- makeLibrary(source:options:completionHandler:)
- Resources and Data (
资源和数据): 如顶点数据,纹理坐标数据,保存在MTLBuffer中.纹理数据保存在MTLTexture中. - 要创建MTLBuffer对象,请使用以下MTLDevice方法:
-
newBufferWithLength(_:options:)MTLBuffer使用新的存储分配创建对象。 -
makeBuffer(bytes:length:options:)MTLBuffer通过将现有存储分配中的数据复制到新分配中来创建对象。 -
makeBuffer(bytesNoCopy:length:options:deallocator:)创建一个MTLBuffer重用现有存储分配的对象,并且不分配任何新存储。
-
- 以下方法创建并返回一个MTLTexture对象:
1. MTLDevice协议的makeTexture(descriptor :)方法使用MTLTextureDescriptor对象创建纹理对象,该纹理对象具有纹理图像数据的新存储分配,以描述纹理的属性。
2.MTLTexture协议的makeTextureView(pixelFormat :)和makeTextureView(pixelFormat:textureType:levels:slices :)方法创建并返回一个与源纹理对象共享相同存储分配的新纹理对象。 因为它们共享相同的存储,所以对纹理进行任何更改,反之亦然。 在本文中,我们提出了像素纹理的纹理表示。 新纹理的像素格式必须与源纹理兼容。
3.在iOS中,MTLBuffer协议的makeTextureWith(descriptor:offset:bytesPerRow :)方法创建并返回一个新的纹理对象,该对象共享源缓冲区对象的存储作为其纹理图像数据。 由于它们共享相同的存储,因此对像素的任何更改都会反映在源缓冲区中,反之亦然。
- Resources organization (
资源组织): 缓冲区和纹理在缓冲区和纹理表中组织。缓冲区表中最多有31个条目,纹理表中最多有31个条目。每个条目由索引表示。您需要将此索引传递给命令编码器。然后,Metal函数(内核)将索引用作函数参数的属性,我们将在后面看到。
- Thread Groups (
线程组): 当您在GPU上执行并行计算时,内核的执行将在多个线程中分解。线程被组织成线程组。线程组中的线程通过线程组内存共享数据并通过同步它们的执行来协调对设备和线程组内存的内存访问来进行协作。
例如要处理的纹理的大小来定义线程组的大小:
let threadGroupCount = MTLSizeMake(16, 16, 1)
let threadGroups: MTLSize = MTLSizeMake(Int(inTexture.width) / threadGroupCount.width, Int(inTexture.height) / threadGroupCount.height, 1)
commandEncoder.dispatchThreadgroups(threadGroups, threadsPerThreadgroup: threadGroupCount)
案例: 通过Metal渲染一个三角形

Metal渲染三角形
示例代码
- 1.初始化
//1.获取MTKView
_view = (MTKView *)self.view;
//一个MTLDevice 对象就代表这着一个GPU,通常我们可以调用方法MTLCreateSystemDefaultDevice()来获取代表默认的GPU单个对象.
_view.device = MTLCreateSystemDefaultDevice();
if(!_view.device)
{
NSLog(@"Metal is not supported on this device");
return;
}
//2.创建CCRender
_renderer = [[CCRenderer alloc] initWithMetalKitView:_view];
//用视图大小初始化渲染器
[_renderer mtkView:_view drawableSizeWillChange:_view.drawableSize];
//设置MTKView代理
_view.delegate = _renderer;
//2.从项目中加载所以的.metal着色器文件
id defaultLibrary = [_device newDefaultLibrary];
//从库中加载顶点函数
id vertexFunction = [defaultLibrary newFunctionWithName:@"vertexShader"];
//从库中加载片元函数
id fragmentFunction = [defaultLibrary newFunctionWithName:@"fragmentShader"];
//3.配置用于创建管道状态的管道
MTLRenderPipelineDescriptor *pipelineStateDescriptor = [[MTLRenderPipelineDescriptor alloc] init];
//管道名称
pipelineStateDescriptor.label = @"Simple Pipeline";
//可编程函数,用于处理渲染过程中的各个顶点
pipelineStateDescriptor.vertexFunction = vertexFunction;
//可编程函数,用于处理渲染过程总的各个片段/片元
pipelineStateDescriptor.fragmentFunction = fragmentFunction;
//设置管道中存储颜色数据的组件格式
pipelineStateDescriptor.colorAttachments[0].pixelFormat = mtkView.colorPixelFormat;
//4.同步创建并返回渲染管线对象
NSError *error = NULL;
_pipelineState = [_device newRenderPipelineStateWithDescriptor:pipelineStateDescriptor
error:&error];
- 2.创建命令队列
// 创建命令队列
_commandQueue = [_device newCommandQueue];
- 3.创建命令缓存区
// 为当前渲染的每个渲染传递创建一个新的命令缓冲区
id commandBuffer = [_commandQueue commandBuffer];
//指定缓存区名称
commandBuffer.label = @"MyCommand";
- 4.创建命令编码器
// MTLRenderPassDescriptor:一组渲染目标,用作渲染通道生成的像素的输出目标。
MTLRenderPassDescriptor *renderPassDescriptor = view.currentRenderPassDescriptor;
//判断渲染目标是否为空
if(renderPassDescriptor != nil)
{
// 创建渲染命令编码器,这样我们才可以渲染到something
id renderEncoder =[commandBuffer renderCommandEncoderWithDescriptor:renderPassDescriptor];
//渲染器名称
renderEncoder.label = @"MyRenderEncoder";
// 设置我们绘制的可绘制区域
/*
typedef struct {
double originX, originY, width, height, znear, zfar;
} MTLViewport;
*/
//视口指定Metal渲染内容的drawable区域。 视口是具有x和y偏移,宽度和高度以及近和远平面的3D区域
//为管道分配自定义视口需要通过调用setViewport:方法将MTLViewport结构编码为渲染命令编码器。 如果未指定视口,Metal会设置一个默认视口,其大小与用于创建渲染命令编码器的drawable相同。
MTLViewport viewPort = {
0.0,0.0,_viewportSize.x,_viewportSize.y,-1.0,1.0
};
[renderEncoder setViewport:viewPort];
//[renderEncoder setViewport:(MTLViewport){0.0, 0.0, _viewportSize.x, _viewportSize.y, -1.0, 1.0 }];
// 设置当前渲染管道状态对象
[renderEncoder setRenderPipelineState:_pipelineState];
// 从应用程序OC 代码 中发送数据给Metal 顶点着色器 函数
//顶点数据+颜色数据
// 1) 指向要传递给着色器的内存的指针
// 2) 我们想要传递的数据的内存大小
// 3)一个整数索引,它对应于我们的“vertexShader”函数中的缓冲区属性限定符的索引。
[renderEncoder setVertexBytes:triangleVertices
length:sizeof(triangleVertices)
atIndex:CCVertexInputIndexVertices];
//viewPortSize 数据
//1) 发送到顶点着色函数中,视图大小
//2) 视图大小内存空间大小
//3) 对应的索引
[renderEncoder setVertexBytes:&_viewportSize
length:sizeof(_viewportSize)
atIndex:CCVertexInputIndexViewportSize];
// 画出三角形的3个顶点
// @method drawPrimitives:vertexStart:vertexCount:
//@brief 在不使用索引列表的情况下,绘制图元
//@param 绘制图形组装的基元类型
//@param 从哪个位置数据开始绘制,一般为0
//@param 每个图元的顶点个数,绘制的图型顶点数量
/*
MTLPrimitiveTypePoint = 0, 点
MTLPrimitiveTypeLine = 1, 线段
MTLPrimitiveTypeLineStrip = 2, 线环
MTLPrimitiveTypeTriangle = 3, 三角形
MTLPrimitiveTypeTriangleStrip = 4, 三角型扇
*/
[renderEncoder drawPrimitives:MTLPrimitiveTypeTriangle
vertexStart:0
vertexCount:3];
// 表示已该编码器生成的命令都已完成,并且从NTLCommandBuffer中分离
[renderEncoder endEncoding];
}
- 5.添加当前绘制到命令缓存区
// 一旦框架缓冲区完成,使用当前可绘制的进度表
[commandBuffer presentDrawable:view.currentDrawable];
- 6.提交命令到GPU
// 最后,在这里完成渲染并将命令缓冲区推送到GPU
[commandBuffer commit];
Metal文件代码
#include
//使用命名空间 Metal
using namespace metal;
// 导入Metal shader 代码和执行Metal API命令的C代码之间共享的头
#import "CCShaderTypes.h"
// 顶点着色器输出和片段着色器输入
//结构体
typedef struct
{
//处理空间的顶点信息
float4 clipSpacePosition [[position]];
//颜色
float4 color;
} RasterizerData;
//顶点着色函数
vertex RasterizerData
vertexShader(uint vertexID [[vertex_id]],
constant CCVertex *vertices [[buffer(CCVertexInputIndexVertices)]],
constant vector_uint2 *viewportSizePointer [[buffer(CCVertexInputIndexViewportSize)]])
{
/*
处理顶点数据:
1) 执行坐标系转换,将生成的顶点剪辑空间写入到返回值中.
2) 将顶点颜色值传递给返回值
*/
//定义out
RasterizerData out;
//初始化输出剪辑空间位置
out.clipSpacePosition = vector_float4(0.0, 0.0, 0.0, 1.0);
// 索引到我们的数组位置以获得当前顶点
// 我们的位置是在像素维度中指定的.
float2 pixelSpacePosition = vertices[vertexID].position.xy;
//将vierportSizePointer 从verctor_uint2 转换为vector_float2 类型
vector_float2 viewportSize = vector_float2(*viewportSizePointer);
//每个顶点着色器的输出位置在剪辑空间中(也称为归一化设备坐标空间,NDC),剪辑空间中的(-1,-1)表示视口的左下角,而(1,1)表示视口的右上角.
//计算和写入 XY值到我们的剪辑空间的位置.为了从像素空间中的位置转换到剪辑空间的位置,我们将像素坐标除以视口的大小的一半.
out.clipSpacePosition.xy = pixelSpacePosition / (viewportSize / 2.0);
//把我们输入的颜色直接赋值给输出颜色. 这个值将于构成三角形的顶点的其他颜色值插值,从而为我们片段着色器中的每个片段生成颜色值.
out.color = vertices[vertexID].color;
//完成! 将结构体传递到管道中下一个阶段:
return out;
}
//当顶点函数执行3次,三角形的每个顶点执行一次后,则执行管道中的下一个阶段.栅格化/光栅化.
// 片元函数
//[[stage_in]],片元着色函数使用的单个片元输入数据是由顶点着色函数输出.然后经过光栅化生成的.单个片元输入函数数据可以使用"[[stage_in]]"属性修饰符.
//一个顶点着色函数可以读取单个顶点的输入数据,这些输入数据存储于参数传递的缓存中,使用顶点和实例ID在这些缓存中寻址.读取到单个顶点的数据.另外,单个顶点输入数据也可以通过使用"[[stage_in]]"属性修饰符的产生传递给顶点着色函数.
//被stage_in 修饰的结构体的成员不能是如下这些.Packed vectors 紧密填充类型向量,matrices 矩阵,structs 结构体,references or pointers to type 某类型的引用或指针. arrays,vectors,matrices 标量,向量,矩阵数组.
fragment float4 fragmentShader(RasterizerData in [[stage_in]])
{
//返回输入的片元颜色
return in.color;
}
效果
