1.简介
Hadoop是一款开源的大数据通用处理平台,其提供了分布式存储和分布式离线计算,适合大规模数据、流式数据(写一次,读多次),不适合低延时的访问、大量的小文件以及频繁修改的文件。
*Hadoop由HDFS、YARN、MapReduce组成。
Hadoop的特点:
1.高扩展(动态扩容):能够存储和处理千兆字节数据(PB),能够动态的增加和卸载节点,提升存储能力(能够达到上千个节点)
2.低成本:只需要普通的PC机就能实现,不依赖高端存储设备和服务器。
3.高效率:通过在Hadoop集群中分化数据并行处理,使得处理速度非常快。
4.可靠性:数据有多份副本,并且在任务失败后能自动重新部署。
Hadoop的使用场景:
1.日志分析,将数据分片并行计算处理。
2.基于海量数据的在线应用。
3.推荐系统,精准营销。
4.搜索引擎。
Hadoop生态圈:
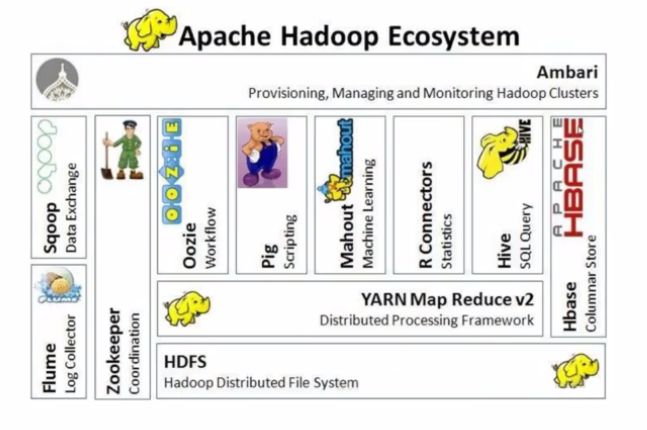
Hive:利用Hive可以不需要编写复杂的Hadoop程序,只需要写一个SQL语句,Hive就会把SQL语句转换成Hadoop的任务去执行,降低使用Hadoop离线计算的门槛。
HBase:海量数据存储的非关系型数据库,单个表中的数据能够容纳百亿行x百万列。
ZooKeeper:监控Hadoop集群中每个节点的状态,管理整个集群的配置,维护节点间数据的一致性。
Flume:海量日志采集系统。
2.内部结构
2.1 HDFS
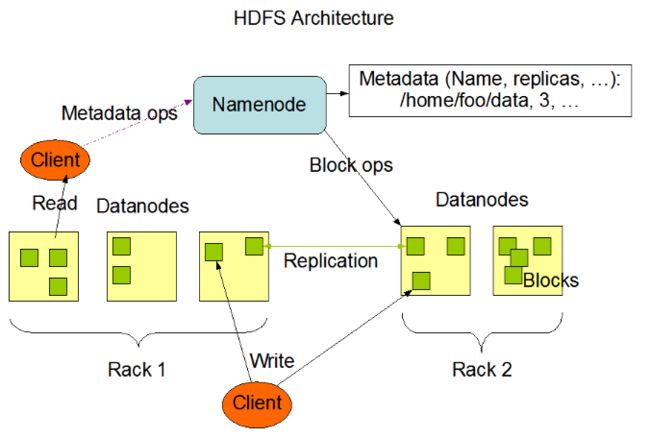
HDFS是分布式文件系统,存储海量的文件,其中HDFS中包含NameNode、DataNode、SecondaryNameNode组件等。
Block数据块
1.HDFS中基本的存储单元,1.X版本中每个Block默认是64M,2.X版本中每个Block默认是128M。
2.一个大文件会被拆分成多个Block进行存储,如果一个文件少于Block的大小,那么其实际占用的空间为文件自身大小。
3.每个Block都会在不同的DataNode节点中存在备份(默认备份数是3)
DataNode
1.保存具体的Blocks数据。
2.负责数据的读写操作和复制操作。
3.DataNode启动时会向NameNode汇报当前存储的数据块信息。
NameNode
1.存储文件的元信息和文件与Block、DataNode的关系,NameNode运行时所有数据都保存在内存中,因此整个HDFS可存储的文件数受限于NameNode的内存大小。
2.每个Block在NameNode中都对应一条记录,如果是大量的小文件将会消耗大量内存,因此HDFS适合存储大文件。
3.NameNode中的数据会定时保存到本地磁盘中(只有元数据),但不保存文件与Block、DataNode的位置信息,这部分数据由DataNode启动时上报和运行时维护。
*NameNode不允许DataNode具有同一个Block的多个副本,所以创建的最大副本数量是当时DataNode的总数。
*DataNode会定期向NameNode发送心跳信息,一旦在一定时间内NameNode没有接收到DataNode发送的心跳则认为其已经宕机,因此不会再给它任何IO请求。
*如果DataNode失效造成副本数量下降并且低于预先设置的阈值或者动态增加副本数量,则NameNode会在合适的时机重新调度DataNode进行复制。
SecondaryNameNode
1.定时与NameNode进行同步,合并HDFS中系统镜像,定时替换NameNode中的镜像。
HDFS写入文件的流程

1.HDFS Client向NameNode申请写入文件。
2.NameNode根据文件大小,返回文件要写入的DataNode列表以及Block id (此时NameNode已存储文件的元信息、文件与DataNode、Block之间的关系)
3.HDFS Client收到响应后,将文件写入第一个DataNode中,第一个DataNode接收到数据后将其写入本地磁盘,同时把数据传递给第二个DataNode,直到写入备份数个DataNode。
4.每个DataNode接收完数据后都会向前一个DataNode返回写入成功的响应,最终第一个DataNode将返回HDFS Client客户端写入成功的响应。
5.当HDFS Client接收到整个DataNodes的确认请求后会向NameNode发送最终确认请求,此时NameNode才会提交文件。
*当写入某个DataNode失败时,数据会继续写入其他的DataNode,NameNode会重新寻找DataNode继续复制,以保证数据的可靠性。
*每个Block都会有一个校验码并存放在独立的文件中,以便读的时候来验证数据的完整性。
*文件写入完毕后,向NameNode发送确认请求,此时文件才可见,如果发送确认请求之前NameNode宕机,那么文件将会丢失,HDFS客户端无法进行读取。
HDFS读取文件的流程
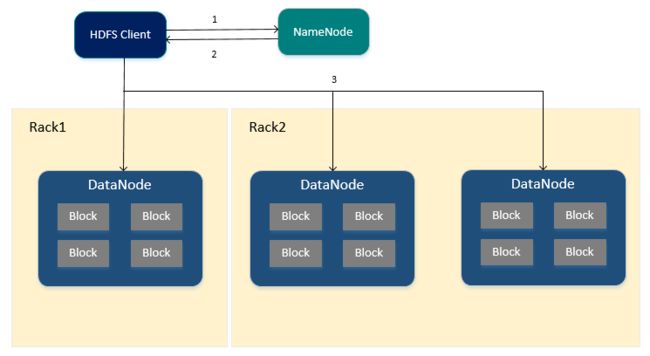
1.HDFS Client向NameNode申请读取指定文件。
2.NameNode返回文件所有的Block以及这些Block所在的DataNodes中(包括复制节点)
3.HDFS Client根据NameNode的返回,优先从与HDFS Client同节点的DataNode中直接读取(若HDFS Client不在集群范围内则随机选择),如果从DataNode中读取失败则通过网络从复制节点中进行读取。
机架感知
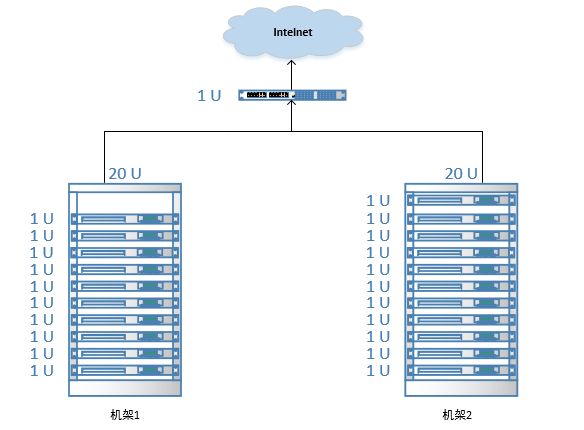
分布式集群中通常包含非常多的机器,由于受到机架槽位和交换机网口的限制,通常大型的分布式集群都会跨好几个机架,由多个机架上的机器共同组成一个分布式集群。
机架内的机器之间的网络速度通常都会高于跨机架机器之间的网络速度,并且机架之间机器的网络通信通常受到上层交换机间网络带宽的限制。
Hadoop默认没有开启机架感知功能,默认情况下每个Block都是随机分配DataNode,需要进行相关的配置,那么在NameNode启动时,会将机器与机架的对应信息保存在内存中,用于在HDFS Client申请写文件时,能够根据预先定义的机架关系合理的分配DataNode。
Hadoop机架感知默认对3个副本的存放策略为:
第1个Block副本存放在和HDFS Client所在的节点中(若HDFS Client不在集群范围内则随机选取)
第2个Block副本存放在与第一个节点不同机架下的节点中(随机选择)
第3个Block副本存放在与第2个副本所在节点的机架下的另一个节点中,如果还有更多的副本则随机存放在集群的节点中。
*使用此策略可以保证对文件的访问能够优先在本机架下找到,并且如果整个机架上发生了异常也可以在另外的机架上找到该Block的副本。
2.2 YARN
YARN是分布式资源调度框架(任务计算框架的资源调度框架),主要负责集群中的资源管理以及任务调度并且监控各个节点。
ResourceManager
1.是整个集群的资源管理者,管理并监控各个NodeManager。
2.处理客户端的任务请求。
3.启动和监控ApplicationMaster。
4.负责资源的分配以及调度。
NodeManager
1.是每个节点的管理者,负责任务的执行。
2.处理来自ResourceManager的命令。
3.处理来自ApplicationMaster的命令。
ApplicationMaster
1.数据切分,用于并行计算处理。
2.计算任务所需要的资源。
3.负责任务的监控与容错。
任务运行在YARN的流程
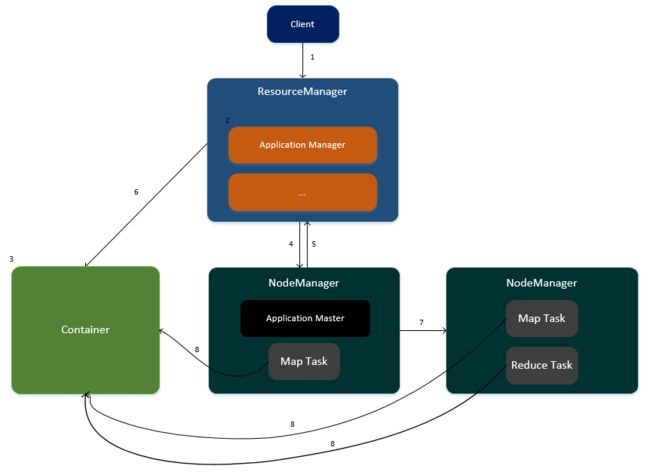
1.客户端提交任务请求到ResourceManager。
2.ResourceManager生成一个ApplicationManager进程,用于任务的管理。
3.ApplicationManager创建一个Container容器用于存放任务所需要的资源。
4.ApplicationManager寻找其中一个NodeManager,在此NodeManager中启动一个ApplicationMaster,用于任务的管理以及监控。
5.ApplicationMaster向ResourceManager进行注册,并计算任务所需的资源汇报给ResourceManager(CPU与内存)
6.ResourceManager为此任务分配资源,资源封装在Container容器中。
7.ApplicationMaster通知集群中相关的NodeManager进行任务的执行。
8.各个NodeManager从Container容器中获取资源并执行Map、Reduce任务。
2.3 MapReduce
MapReduce是分布式离线并行计算框架,高吞吐量,高延时,原理是将分析的数据拆分成多份,通过多台节点并行处理,相对于Storm、Spark任务计算框架而言,MapReduce是最早出现的计算框架。
MapReduce、Storm、Spark任务计算框架对比:

MapReduce执行流程
MapReduce将程序划分为Map任务以及Reduce任务两部分。
Map任务处理流程
1.读取文件中的内容,解析成Key-Value的形式 (Key为偏移量,Value为每行的数据)
2.重写map方法,编写业务逻辑,生成新的Key和Value。
3.对输出的Key、Value进行分区(Partitioner类)
4.对数据按照Key进行排序、分组,相同key的value放到一个集合中(数据汇总)
*处理的文件必须要在HDFS中。
Reduce任务处理流程
1.对多个Map任务的输出,按照不同的分区,通过网络复制到不同的reduce节点。
2.对多个Map任务的输出进行合并、排序。
3.将reduce的输出保存到文件,存放在HDFS中。
3.Hadoop的使用
3.1 安装
由于Hadoop使用Java语言进行编写,因此需要安装JDK。

从CDH中下载Hadoop 2.X并进行解压,CDH是Cloudrea公司对各种开源框架的整合与优化(较稳定)
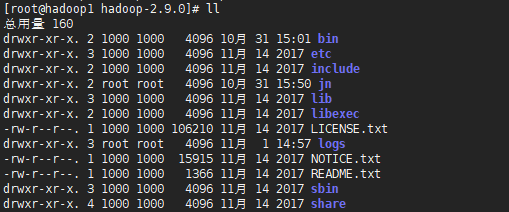
etc目录:Hadoop配置文件存放目录。
logs目录:Hadoop日志存放目录。
bin目录、sbin目录:Hadoop可执行命令存放目录。
etc目录
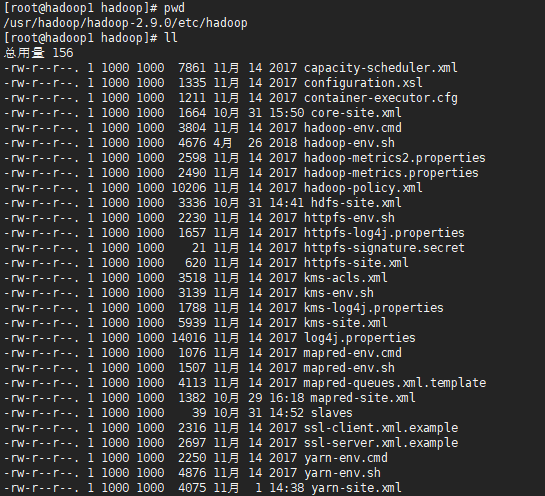
bin目录

sbin目录

3.2 Hadoop配置
1.配置环境
编辑etc/hadoop/hadoop-env.sh文件,修改JAVA_HOME配置项为本地JAVA的HOME目录,此文件是Hadoop启动时加载的环境变量。

编辑/etc/hosts文件,添加主机名与IP的映射关系。
2.配置Hadoop公共属性(core-site.xml)
3.配置HDFS(hdfs-site.xml)
4.配置YARN(yarn-site.xml)
5.配置MapReduce(mapred-site.xml)
6.配置SSH
由于在启动hdfs、yarn时都需要对用户的身份进行验证,因此可以配置SSH设置免密码登录。
//生成秘钥
ssh-keygen -t rsa //复制秘钥到本机ssh-copy-id 192.168.1.80
3.3 启动HDFS
1.格式化NameNode
2.启动HDFS,将会启动NameNode、DataNode、SecondaryNameNode三个进程,可以通过jps命令进行查看。


*若启动时出现错误,则可以进入logs目录查看相应的日志文件。
当HDFS启动完毕后,可以访问http://localhost:50070进入HDFS的可视化管理界面,可以在此页面中监控整个HDFS集群的状况并且进行文件的上传以及下载。
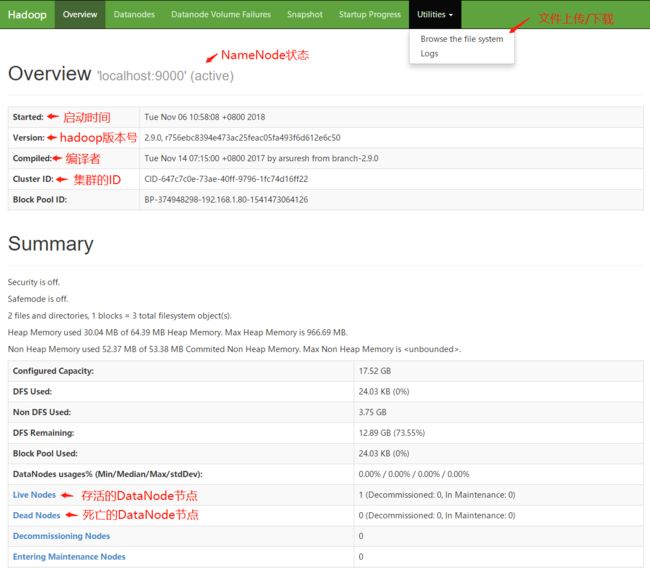
*进入HDFS监控页面下载文件时,会将请求重定向,重定向后的地址的主机名为NameNode的主机名,因此客户端本地的host文件中需要配置NameNode主机名与IP的映射关系。
3.4 启动YARN

启动YARN后,将会启动ResourceManager以及NodeManager进程,可以通过jps命令进行查看。

当YARN启动完毕后,可以访问http://localhost:8088进入YARN的可视化管理界面,可以在此页面中查看任务的执行情况以及资源的分配。

3.5 使用Shell命令操作HDFS
HDFS中的文件系统与Linux类似,由/代表根目录。
hadoop fs -cat :显示文件中的内容。
hadoop fs -copyFromLocal :将本地中的文件上传到HDFS。
hadoop fs -copyToLocal :将HDFS中的文件下载到本地。
hadoop fs -count :查询指定路径下文件的个数。
hadoop fs -cp :在HDFS内对文件进行复制。
hadoop fs -get :将HDFS中的文件下载到本地。
hadoop fs -ls :显示指定目录下的内容。
hadoop fs -mkdir :创建目录。
hadoop fs -moveFromLocal :将本地中的文件剪切到HDFS中。
hadoop fs -moveToLocal :将HDFS中的文件剪切到本地中。
hadoop fs -mv :在HDFS内对文件进行移动。
hadoop fs -put :将本地中的文件上传到HDFS。
hadoop fs -rm :删除HDFS中的文件。
3.6 JAVA中操作HDFS
/** * @Auther: ZHUANGHAOTANG
* @Date: 2018/11/6 11:49
* @Description:
*/publicclass HDFSUtils {
/** * HDFS NamenNode URL
*/privatestaticfinalString NAMENODE_URL = "hdfs://hadoop1:8020";
/** * 配置项
*/privatestaticConfiguration conf =null;
static {
conf =new Configuration();
}
/** * 创建目录
*/publicstaticvoidmkdir(String dir)throws Exception {
if (StringUtils.isBlank(dir)) {
thrownewException("Parameter Is NULL");
}
dir = NAMENODE_URL + dir;
FileSystem fs = FileSystem.get(URI.create(NAMENODE_URL), conf);
if(!fs.exists(new Path(dir))) {
fs.mkdirs(new Path(dir));
}
fs.close();
}
/** * 删除目录或文件
*/publicstaticvoiddelete(String dir)throws Exception {
if (StringUtils.isBlank(dir)) {
thrownewException("Parameter Is NULL");
}
dir = NAMENODE_URL + dir;
FileSystem fs = FileSystem.get(URI.create(NAMENODE_URL), conf);
fs.delete(newPath(dir),true);
fs.close();
}
/** * 遍历指定路径下的目录和文件
*/publicstaticList listAll(String dir)throws Exception {
List names =newArrayList<>();
if (StringUtils.isBlank(dir)) {
thrownewException("Parameter Is NULL");
}
dir = NAMENODE_URL + dir;
FileSystem fs = FileSystem.get(URI.create(dir), conf);
FileStatus[] files = fs.listStatus(new Path(dir));
for(inti = 0, len = files.length; i < len; i++) {
if(files[i].isFile()) {//文件 names.add(files[i].getPath().toString());
} elseif(files[i].isDirectory()) {//目录 names.add(files[i].getPath().toString());
} elseif(files[i].isSymlink()) {//软或硬链接 names.add(files[i].getPath().toString());
}
}
fs.close();
return names;
}
/** * 上传当前服务器的文件到HDFS中
*/publicstaticvoiduploadLocalFileToHDFS(String localFile, String hdfsFile)throws Exception {
if(StringUtils.isBlank(localFile) || StringUtils.isBlank(hdfsFile)) {
thrownewException("Parameter Is NULL");
}
hdfsFile = NAMENODE_URL + hdfsFile;
FileSystem fs = FileSystem.get(URI.create(NAMENODE_URL), conf);
Path src =new Path(localFile);
Path dst =new Path(hdfsFile);
fs.copyFromLocalFile(src, dst);
fs.close();
}
/** * 通过流上传文件
*/publicstaticvoiduploadFile(String hdfsPath, InputStream inputStream)throws Exception {
if (StringUtils.isBlank(hdfsPath)) {
thrownewException("Parameter Is NULL");
}
hdfsPath = NAMENODE_URL + hdfsPath;
FileSystem fs = FileSystem.get(URI.create(NAMENODE_URL), conf);
FSDataOutputStream os = fs.create(new Path(hdfsPath));
BufferedInputStream bufferedInputStream =new BufferedInputStream(inputStream);
byte[] data =newbyte[1024];
while(bufferedInputStream.read(data) != -1) {
os.write(data);
}
os.close();
fs.close();
}
/** * 从HDFS中下载文件
*/publicstaticbyte[] readFile(String hdfsFile)throws Exception {
if (StringUtils.isBlank(hdfsFile)) {
thrownewException("Parameter Is NULL");
}
hdfsFile = NAMENODE_URL + hdfsFile;
FileSystem fs = FileSystem.get(URI.create(NAMENODE_URL), conf);
Path path =new Path(hdfsFile);
if (fs.exists(path)) {
FSDataInputStream is = fs.open(path);
FileStatus stat = fs.getFileStatus(path);
byte[] data =newbyte[(int) stat.getLen()];
is.readFully(0, data);
is.close();
fs.close();
return data;
} else {
thrownewException("File Not Found In HDFS");
}
}
}
3.7 执行一个MapReduce任务
Hadoop中提供了hadoop-mapreduce-examples-2.9.0.jar,其封装了一些任务计算方法,可以直接进行调用。
*使用hadoop jar命令执行JAR包。
1.创建一个文件,将此文件上传到HDFS中。

2.使用Hadoop提供的hadoop-mapreduce-examples-2.9.0.jar执行wordcount词频统计功能,然后在YARN管理页面中进行查看。

YARN管理页面中可以查看任务的执行进度:

3.当任务执行完毕后,可以查看任务的执行结果。

*任务的执行结果将会放到HDFS的文件中。 欢迎工作一到五年的Java工程师朋友们加入Java群: 891219277
群内提供免费的Java架构学习资料(里面有高可用、高并发、高性能及分布式、Jvm性能调优、Spring源码,MyBatis,Netty,Redis,Kafka,Mysql,Zookeeper,Tomcat,Docker,Dubbo,Nginx等多个知识点的架构资料)合理利用自己每一分每一秒的时间来学习提升自己,不要再用"没有时间“来掩饰自己思想上的懒惰!趁年轻,使劲拼,给未来的自己一个交代!