内容简述:
一:爬虫概述和学习路线
二:协议和请求方法
三:抓包工具-谷歌浏览器抓包介绍
四:urllib库介绍和使用
五:构建高级请求对象Request的get和post
一:爬虫起源
大数据时代数据来源:
1.企业生产的用户数据(BAT) 例如:百度指数|阿里指数|微指数等
http://index.baidu.com/ http://index.1688.com/
2.数据管理咨询公司 例如:艾瑞咨询|埃森哲
http://www.iresearch.com.cn/ https://www.accenture.com/cn-en
3.政府/机构提供的公开数据 例如:统计局|世界银行等
http://www.stats.gov.cn/ https://data.worldbank.org.cn/
4.第三方数据平台购买数据 例如:贵阳大数据交易平台
5.爬虫爬取数据
二:爬虫概念及分类
概念:是抓取网页数据的程序。
使用场景分类:通用爬虫和聚焦爬虫概念
通用爬虫:
通用网络爬虫是捜索引擎抓取系统(Baidu、Google、Yahoo等)的组成部分。
主要目的是将互联网上的网页下载到本地,形成一个互联网内容的镜像备份。
通用爬虫工作流程:
1-抓取网页
A-向搜索引擎主动提供
B-其它优质网站设置外链
C-搜索引擎与DNS服务商合作,快速收录新网站
2-数据存储
3-数据处理
4-提供检索服务、网站排名
缺点
1-数据大部分无用
2-搜索引擎无法针对于某个用户提供服务
Robots协议:协议会指明通用爬虫可以爬取网页的权限。
Robots.txt 并不是所有爬虫都遵守,大型的搜索引擎爬虫会遵守。
聚焦爬虫:是"面向特定个性化需求"的一种网络爬虫程序。
三:怎么爬数据?
1.确定需要爬取的网页URL。
2.通过HTTP/HTTP协议获取HTML页面。
3.提取HTML页面里有用的数据:
a.如果是需要的数据,就保存起来。
b.如果是页面里的其他URL,那就继续执行第二步。
四:学习爬虫必备知识点
1.Python的基本语法知识
2.如何抓取HTML页面:
HTTP请求的处理,urllib、requests
处理后的请求可以模拟浏览器发送请求,获取服务器响应文件
3.解析服务器响应的内容
re、xpath、BeautifulSoup4(bs4)、jsonpath、pyquery等
4.如何采集动态HTML、验证码的处理
Selenium+ PhantomJS(无界面浏览器):
模拟真实浏览器加载js、ajax等非静态页面
Tesseract:机器学习库,机器图像识别系统,可以处理简单的验证码。
复杂的验证码可以通过手动输入/专门的打码平台
5.Scrapy框架:(Scrapy|Pyspider)
个性化高性能(底层使用-异步网络框架twisted),下载速度快,
提供了数据存储、数据下载、提取规则等组件。
6.分布式策略 scrapy-reids:
在Scrapy的基础上添加了以 Redis 为核心的组件。支持分布式的功能。
主要在Redis里做请求指纹去重、请求分配、数据临时存储等。
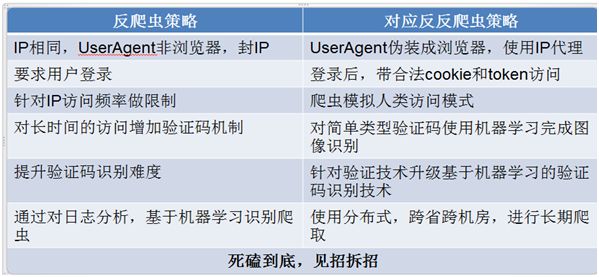
7.爬虫-反爬虫-反反爬虫之间的战斗
User-Agent、代理、验证码、动态数据加载、加密数据。
五:HTTP和HTTPS
HTTP协议(HyperText TransferProtocol,超文本传输协议):
是一种发布和接收 HTML页面的方法。
HTTPS(Hypertext TransferProtocol over Secure Socket Layer)
是HTTP的安全版,在HTTP下加入SSL层。
SSL(Secure Sockets Layer 安全套接层)主要用于Web的安全传输协议,在传输层对网络连接进行加密,保障在Internet上数据传输的安全。
HTTP的端口号为80,HTTPS的端口号为443
HTTP工作原理
网络爬虫抓取过程可以理解为模拟浏览器操作的过程。
浏览器的主要功能是向服务器发出请求,在浏览器窗口中展示你选择的网络资源,HTTP是一套计算机通过网络进行通信的规则。
HTTP通信由两部分组成: 客户端请求消息 与 服务器响应消息

浏览器发送HTTP请求的过程:
1-当用户在浏览器的地址栏中输入一个URL并按回车键之后,浏览器会向HTTP服务器发送HTTP请求。HTTP请求主要分为“Get”和“Post”两种方法。
2-当我们在浏览器输入URL http://www.hao123.com的时候,浏览器发送一个Request请求去获取hao123的html,服务器把Response文件对象发送回给浏览器。
3-浏览器分析Response中的 HTML,发现其中引用了很多其他文件,比如Images文件,CSS文件,JS文件。浏览器会自动再次发送Request去获取css|js
4-当所有的文件都下载成功后,网页会根据HTML语法结构,完整进行显示。
六-URL
Uniform/Universal Resource Locator的缩写):统一资源定位符。
是用于完整地描述互联网上网页和其他资源的地址的一种手段。
基本格式:scheme://host[:port#]/path/…/[?query-string][#anchor]
Scheme:协议(例如:http,https, ftp)
Host:服务器的IP地址或者域名
port#:服务器的端口(如果是走协议默认端口,缺省端口80)
path:访问资源的路径
query-string:参数,发送给http服务器的数据
anchor:锚(跳转到网页的指定锚点位置)
七:请求方法

八:发送请求谷歌调试细节
General:
Request URL: https://www.baidu.com/ 请求地址
Request Method: GET 请求方法
Status Code: 200 OK 状态码
Remote Address: 61.135.169.125:443 客户端请求ip
Response Headers
Cache-Control: private 告诉客户端下次请求的方式
Connection: Keep-Alive 客户端和服务端的连接类型
Content-Encoding: gzip 服务端返回的数据是经过gzip编码的
Content-Type:text/html;charset=utf-8 响应文件的类型和字符编码
Date: Wed, 27 Jun 2018 01:48:50GMT 服务器发送文件的时间
Server: BWS/1.1 服务器版本
Set-Cookie: BDSVRTM=68; path=/ 设置cookie信息
RequestHeaders
Accept:text/html 可以接受返回的类型
Accept-Encoding: gzip,
deflate, br 可以接受的字符编码
Accept-Language:zh-CN,zh;q=0.9 语言
Cache-Control:max-age=0 不会缓存服务器资源
Connection: keep-alive 和服务端连接类型
Cookie: BAIDUID=F68132AFC5355:FG=1; Cookie类型
Host: www.baidu.com 请求地址
User-Agent:Mozilla/5.0 (Windows NT6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181Safari/537.36 浏览器名称
九: urllib库
urllib库是Python提供的用于操作URL的模块
urllib.request可以用来发送request和获取request的结果
urllib.parse用来解析和处理URL
【1】urllib.request.urlopen方法
urlopen(url, data = None,context = None)
如果有data,则代表是post请求,context表示的是https请求的消除ssl错误
urllib.request.urlretrieve(url, file_path) 将url内容直接下载到file_path中
注意:windows和mac在通过urlopen发送https请求的时候有可能报错
错误:SSL: CERTIFICATE_VERIFY_FAILED
原因:Python 2.7.9 之后引入了一个新特性,当使用urllib.urlopen打开一个 https 链接时,会验证一次 SSL证书。
解决方案:
1-使用ssl创建未经验证的上下文,在urlopen中传入上下文参数
context = ssl._create_unverified_context()
urllib.request.urlopen("url",context=context).read()
2-全局取消证书验证
在文件中导入ssl并添加一行代码
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
【2】HTTPResponse对象常见方法
read() 读取的是二进制数据
字符串类型和字节类型
字符串==》字节 编码encode()
字节==》字符串 解码decode()
readline() 读取一行
readlines()读取全部,返回一个列表
【注意】上面的读取都是字节类型,转为字符串类型需要解码
getcode()状态码
geturl() 获取url
getheaders()响应头信息 列表里面有元祖
status属性 http状态码
【3】urllib.parse
A-urllib.parse.urlencode
通过post提交的数据,需通过此函数转码,且发送请求的时候必须为字节格式的,
所以post请求数据经常如下使用
data :是一个字典
data =urllib.parse.urlencode(data).encode('utf-8')
B-urllib.parse.quote()
get参数中,有中文的,需要使用这个函数转码
http://www.baidu.com?name=中国
http://tool.chinaz.com/tools/urlencode.aspx 编码在线工具
C-urllib.parse.unquote() url解码
十一:构造请求对象Request(高级请求)
User-Agent在线解析工具 http://www.atool.org/useragent.php
request = urllib.request.Request(fullurl,headers=None)
可以直接传递headers,也可request.add_header('User-Agent','xxx')
十二:带中文的get请求
十三:POST请求(百度翻译)
温馨提示:
a.如果只加User-Agent获取不到想要的结果,将所有请求头复制再次请求
b.不要带-请求头里面'Accept-Encoding': 'gzip, deflate'
十四:作业
1-完成课堂代码
2-完成必应翻译get和post请求