本案例数据取自kaggle。
这次的案例使用的数据做了脱敏处理,可能通过降维压缩或是其他的一些方式进行了变换处理。
1、读入数据
先导入常用库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 解决坐标轴刻度负号乱码
plt.rcParams['axes.unicode_minus'] = False
# 解决中文乱码问题
plt.rcParams['font.sans-serif'] = ['Simhei']
#显示全部特征
pd.set_option('display.max_columns', None)
%matplotlib inline
读入数据
data=pd.read_csv('creditcard.csv')
data.head()


Class为标签列,0表示正常客户,1表示欺诈客户。
我们可以看到,V1-V28是经过降维压缩等转换手段得到的28个特征,是经过了归一化的,Amount这个特征表示交易金额,我们是需要将其也进行归一化的。
data.shape
数据集维度是(284807, 31)。
data.info()

数据集不存在缺失值且没有字符串变量。
data['Class'].value_counts()
标签分布极不平衡。
2、数据处理
首先,我们要将Amount标准化,并将不需要用到的Time去掉。
from sklearn.preprocessing import StandardScaler
data['Amount'] = StandardScaler().fit_transform(data['Amount'].reshape(-1,1))
data=data.loc[:,data.columns!='Time']
data.head()
3、样本不均衡解决方案
由于我们的数据极不平衡,在这里有上采样(将少数类增多到和多数类一样)和下采样(减少多数类使其数量与少数类相同)两种方式。先来看看下采样的方式。
3.1 下采样策略
## 下采样
# 分离特征和标签
X = data.loc[:, data.columns != 'Class']
y = data['Class']
# 计算少数类个数
number_records_fraud = len(data[data.Class == 1])
# 取得少数类样本的索引
fraud_indices = np.array(data[data.Class == 1].index)
# 取得多数类样本的索引
normal_indices = data[data.Class == 0].index
# 从多数类中随机选择与少数类个数相同的样本数作为样本
random_normal_indices = np.random.choice(normal_indices, number_records_fraud, replace = False)
random_normal_indices = np.array(random_normal_indices)
# 合并随机取得的0类和全部的1类的索引
under_sample_indices = np.concatenate([fraud_indices,random_normal_indices])
# 根据索引得到下采样后的数据集
under_sample_data = data.iloc[under_sample_indices,:]
# 分离特征和标签
X_undersample = under_sample_data.ix[:, under_sample_data.columns != 'Class']
y_undersample = under_sample_data.ix[:, under_sample_data.columns == 'Class']
print("正样本比例(0类): ", len(under_sample_data[under_sample_data.Class == 0])/len(under_sample_data))
print("负样本比例(1类): ", len(under_sample_data[under_sample_data.Class == 1])/len(under_sample_data))
print("下采样后总样本个数为: ", len(under_sample_data))

下采样后正负类个数相等,样本总数减少为984。
划分测试集和训练集。
from sklearn.model_selection import train_test_split
# 切分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size = 0.3, random_state = 0)
print("源数据训练集样本数: ", len(X_train))
print("源数据测试集样本数: ", len(X_test))
print("源数据总样本数: ", len(X_train)+len(X_test))
# 下采样
X_train_undersample, X_test_undersample, y_train_undersample, y_test_undersample = train_test_split(X_undersample
,y_undersample
,test_size = 0.3
,random_state = 0)
print('\n')
print("下采样后训练集样本数: ", len(X_train_undersample))
print("下采样后测试集样本数: ", len(X_test_undersample))
print("下采样后样本总数: ", len(X_train_undersample)+len(X_test_undersample))

3.2 正则化参数择优
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import KFold, cross_val_score
from sklearn.metrics import confusion_matrix,recall_score,classification_report
def printing_Kfold_scores(x_train_data,y_train_data):
fold = KFold(5,shuffle=False)
# 超参数C范围
c_param_range = [0.01,0.1,1,10,100]
results_table = pd.DataFrame(index = range(len(c_param_range),2), columns = ['C_parameter','Mean recall score'])
results_table['C_parameter'] = c_param_range
# the k-fold will give 2 lists: train_indices = indices[0], test_indices = indices[1]
j = 0
for c_param in c_param_range:
print('-------------------------------------------')
print('超参数C: ', c_param)
print('-------------------------------------------')
print('\n')
recall_accs = []
for iteration, indices in enumerate(fold.split(x_train_data)):
# 建立l1正则化的逻辑回归模型
lr = LogisticRegression(C = c_param, penalty = 'l1')
# 训练模型
lr.fit(x_train_data.iloc[indices[0],:],y_train_data.iloc[indices[0],:].values.ravel())
# 模型预测
y_pred_undersample = lr.predict(x_train_data.iloc[indices[1],:].values)
# 计算召回率
recall_acc = recall_score(y_train_data.iloc[indices[1],:].values,y_pred_undersample)
recall_accs.append(recall_acc)
print('Iteration ', iteration,': recall= ', recall_acc)
# The mean value of those recall scores is the metric we want to save and get hold of.
results_table.ix[j,'Mean recall score'] = np.mean(recall_accs)
j += 1
print('')
print('Mean recall score ', np.mean(recall_accs))
print('')
best_c = results_table.loc[results_table['Mean recall score'].astype('float64').idxmax()]['C_parameter']
# Finally, we can check which C parameter is the best amongst the chosen.
print('*********************************************************************************')
print('超参数C为{}时,模型交叉验证得分最高'.format(best_c))
print('*********************************************************************************')
return best_c
在0.01、0.1、1、10、100这五个不同量级中选出最优的超参数C(正则化惩罚系数),评价得分标准为recall。
best_c = printing_Kfold_scores(X_train_undersample,y_train_undersample)
3.3 模型评估
def plot_confusion_matrix(cm, classes,
title='Confusion matrix',
cmap=plt.cm.Blues):
"""
This function prints and plots the confusion matrix.
"""
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=0)
plt.yticks(tick_marks, classes)
thresh = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, cm[i, j],
horizontalalignment="center",
color="white" if cm[i, j] > thresh else "black")
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
import itertools
lr = LogisticRegression(C = best_c, penalty = 'l1')
lr.fit(X_train_undersample,y_train_undersample.values.ravel())
y_pred_undersample = lr.predict(X_test_undersample.values)
# Compute confusion matrix
cnf_matrix = confusion_matrix(y_test_undersample,y_pred_undersample)
np.set_printoptions(precision=2)
print("测试集Recall: ", cnf_matrix[1,1]/(cnf_matrix[1,0]+cnf_matrix[1,1]))
# Plot non-normalized confusion matrix
class_names = [0,1]
plt.figure()
plot_confusion_matrix(cnf_matrix
, classes=class_names
, title='Confusion matrix')
plt.show()
测试集Recall: 0.9387755102040817

上面是模型在下采样之后的测试集上的表现,我们再来看看在没有下采样的测试集上的表现。
lr = LogisticRegression(C = best_c, penalty = 'l1')
lr.fit(X_train_undersample,y_train_undersample.values.ravel())
y_pred = lr.predict(X_test.values)
# Compute confusion matrix
cnf_matrix = confusion_matrix(y_test,y_pred)
np.set_printoptions(precision=2)
print("测试集Recall: ", cnf_matrix[1,1]/(cnf_matrix[1,0]+cnf_matrix[1,1]))
# Plot non-normalized confusion matrix
class_names = [0,1]
plt.figure()
plot_confusion_matrix(cnf_matrix
, classes=class_names
, title='Confusion matrix')
plt.show()
测试集Recall: 0.9183673469387755

可以看到recall略有降低,但是通过混淆矩阵可以看到,将正常客户误判为欺诈客户的人数为9505,这其实是很不好的。
我们再看一下如果使用未经过下采样的训练集训练出的模型预测效果如何。
lr = LogisticRegression(C = best_c, penalty = 'l1')
lr.fit(X_train,y_train.values.ravel())
y_pred_undersample = lr.predict(X_test.values)
# 计算混淆矩阵
cnf_matrix = confusion_matrix(y_test,y_pred_undersample)
np.set_printoptions(precision=2)
print("测试集Recall: ", cnf_matrix[1,1]/(cnf_matrix[1,0]+cnf_matrix[1,1]))
class_names = [0,1]
plt.figure()
plot_confusion_matrix(cnf_matrix
, classes=class_names
, title='Confusion matrix')
plt.show()
测试集Recall: 0.5510204081632653

可以看到,recall值仅有0.55非常低。
3.4 阈值对结果的影响
其实sklearn中的逻辑回归默认概率>0.5判断为1类,但我们是可以自己设定阈值的,不同的阈值会影响最终的模型评价结果。
lr = LogisticRegression(C = 0.01, penalty = 'l1')
lr.fit(X_train_undersample,y_train_undersample.values.ravel())
y_pred_undersample_proba = lr.predict_proba(X_test_undersample.values)
thresholds = [0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9]
plt.figure(figsize=(10,10))
j = 1
for i in thresholds:
y_test_predictions_high_recall = y_pred_undersample_proba[:,1] > i
plt.subplot(3,3,j)
j += 1
# 计算混淆矩阵
cnf_matrix = confusion_matrix(y_test_undersample,y_test_predictions_high_recall)
np.set_printoptions(precision=2)
print("阈值为{}时测试集Recall: {}".format(i,cnf_matrix[1,1]/(cnf_matrix[1,0]+cnf_matrix[1,1])))
class_names = [0,1]
plot_confusion_matrix(cnf_matrix
, classes=class_names
, title='Threshold >= %s'%i)


3.5 上采样策略
我们前面看到了,采用下采样策略,训练出来的模型对测试集预测结果recall大约为0.91,远远好于不进行下采样的训练模型recall值(仅为0.55),但是会将9505名正常客户误判为欺诈客户。
那么我们再采用上采样的方式来训练模型,看看效果如何。
import pandas as pd
from imblearn.over_sampling import SMOTE
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import confusion_matrix
from sklearn.model_selection import train_test_split
credit_cards=pd.read_csv('creditcard.csv')
columns=credit_cards.columns
features_columns=columns.delete(len(columns)-1)
features=credit_cards[features_columns]
labels=credit_cards['Class']
features_train, features_test, labels_train, labels_test = train_test_split(features,
labels,
test_size=0.2,
random_state=0)
oversampler=SMOTE(random_state=0)
os_features,os_labels=oversampler.fit_sample(features_train,labels_train)
os_features = pd.DataFrame(os_features)
os_labels = pd.DataFrame(os_labels)
best_c = printing_Kfold_scores(os_features,os_labels)
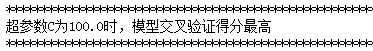
我们来看下经过SMOTE上采样后数据训练的模型预测效果如何。
lr = LogisticRegression(C = best_c, penalty = 'l1')
lr.fit(os_features,os_labels.values.ravel())
y_pred = lr.predict(features_test.values)
# Compute confusion matrix
cnf_matrix = confusion_matrix(labels_test,y_pred)
np.set_printoptions(precision=2)
print("测试集Recall: ", cnf_matrix[1,1]/(cnf_matrix[1,0]+cnf_matrix[1,1]))
# Plot non-normalized confusion matrix
class_names = [0,1]
plt.figure()
plot_confusion_matrix(cnf_matrix
, classes=class_names
, title='Confusion matrix')
plt.show()
测试集Recall: 0.9108910891089109

可以看到,recall值约为0.91,与下采样时几乎是一样,但是仅有536名正常客户被误判为了欺诈客户,相比于下采样9505个误判值来说,上采样的方式似乎更优。
PS:本文代码参考自《唐宇迪机器学习》