越学习越发现自己知之甚少,道阻且长,还是认真看下这篇文章,好好琢磨琢磨GAN吧。
今天将和大家一起学习在GAN界占有重要位置的WGAN,它提出了一种新的距离度量,较之前的f散度,它的数学性质更为优秀。我们将先通过一个例子细说一下f散度的问题,然后介绍Wasserstein距离并用一个小例子给出计算方法,最后利用对偶理论求解Wasserstein距离。
作者&编辑 | 小米粥
说到对GAN的理解,我们不能简单停留在“生成器产生样本,判别器分辨样本真假”的阶段了,在经过第二篇文章后,对GAN的理解应该是:先学习一个关于生成器定义的隐式概率分布和训练数据集的本质概率分布之间的距离度量,然后优化生成器来缩减这个距离度量。今天的主要内容依旧围绕这个距离度量来展开。
1 度量的问题
在第二篇文章的最后,我们简要讨论了f散度的问题。实际中,生成器定义的隐式概率分布和训练数据集的本质概率分布几乎不存在重叠部分,而且随着数据维度增加,这个趋势会更加严重,那么采样计算得来的f散度距离不仅不连续,而且几乎处处导数为0。
用一个非常简单的例子来解释一下,在二维空间有两个无任何重合的均匀分布,其中
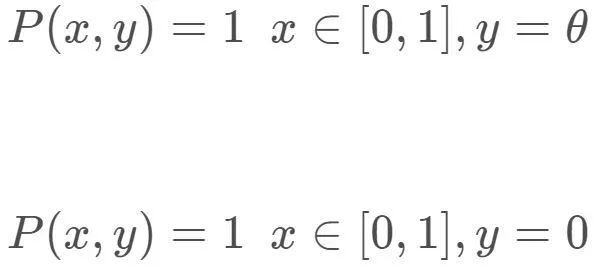

我们来计算一下两个分布的KL散度,JS散度,总变差。

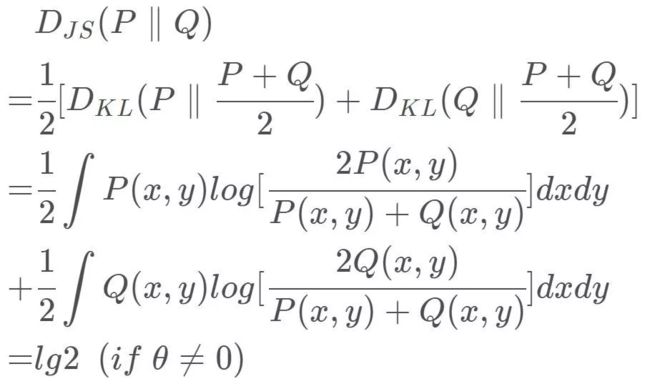

可以看出,当P和Q没有重合或者重合部分可忽略时,其f散度值为常数;当两者完全重合时,f散度值为0。这样的话,f散度无法为生成器提供可以减少损失函数的梯度信息,生成器无法训练获得优化方向。
对于此问题的一种解决方案是:通过对数据集中的样本和生成器生成的样本增加噪声,使得原本的两个低维概率分布“弥散”到整个高维空间,强行让它们产生不可忽略的重叠,此时的f散度便能“指示”出两个分布的距离。在训练过程中,我们可以先添加方差比较大的噪声,以尽可能使两个分布产生较大重叠部分,随着两个分布距离的拉近,可以逐渐降低噪声的方差,直至最后可以去掉噪声完全靠JS散度来指示生成器的学习。
但是为了本质地解决问题,我们需要寻找一种更合理的距离度量。直观上,该距离最好处处连续,在两个分布不重合的位置处处可导且导数不能为0。
2 Wasserstein距离
Wasserstein距离是一个数学性质非常良好距离度量,数学形式稍微有点复杂。我们用一个小例子来引入,定义两个离散概率分布P和Q,其随机变量取值只能为1,2,3,4。如何对P调整使其等于Q?

其实是很简单的一个问题,我们逐位置来分解计算,对于P的1位置,其值为0.25,我们将这0.25保持在1位置,即可有如下分解矩阵:
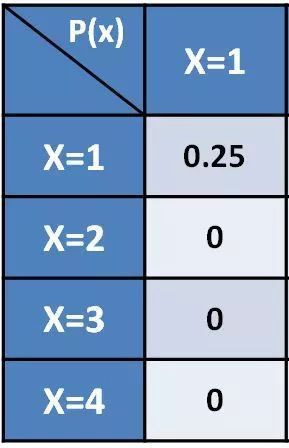
对于P的2位置,其值为0.25,我们也将这0.25全部保持在2位置,即有分解矩阵:

对于P的3位置,其值为0.5,我们将其中的0.25放置到1位置,将0.25放置到2位置,即有分解矩阵:

类似的,P的4位置为0,不用做任何分解和移动,这样我们可看到经过逐个位置分解和移动后,新的分布已经和Q完全一样了,如下:
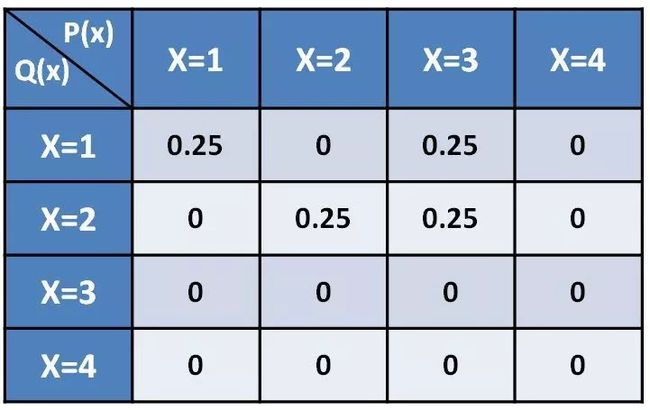
然后,我们再考虑关于路程的移动耗费问题。如果定义从1位置到2位置路程为1,从1位置到3位置路程为2......对P的1位置,将0.25保留在1位置不产生移动耗费,对P的2位置,将0.25保留在2位置也不产生移动耗费,但是对P的3位置,将0.25移动到1位置,需要耗费:0.25*(3-1)=0.5;将0.25移动到2位置,需要耗费:0.25*(2-1)=0.25,故整个方案将产生0.75的耗费。当然,我们也可以有其他传输方案,例如:
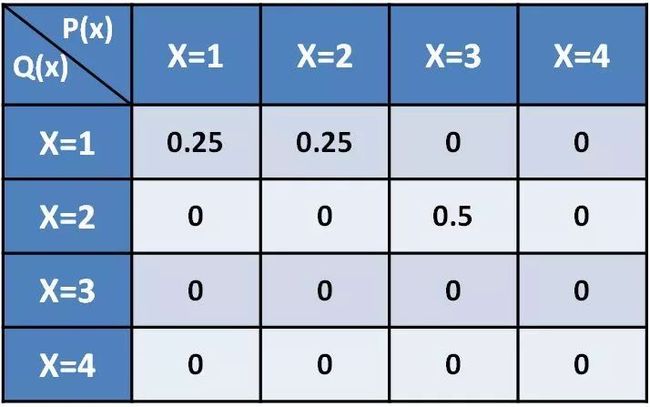
可以证明的是总存在一个耗费最小的方案。Wasserstein距离便是某一种最小耗费方案对应的总耗费值。
在数学形式上,

Π是两个分布构成的全部可能的联合分布的集合,γ是该集合中的一个联合分布,且该联合分布要求:

简而言之就是,γ定义一个传输方案,d定义了路程函数,对每个方案求积分计算总传输耗费值,最后在所有这些方案中取最小耗费值的传输方案,其对应的总耗费值即为距离。
在WGAN中,

当然也可以定义2-Wasserstein距离:
或者k-Wasserstein距离:
针对于刚开始提出的小例子,我们用Wasserstein则可得到:
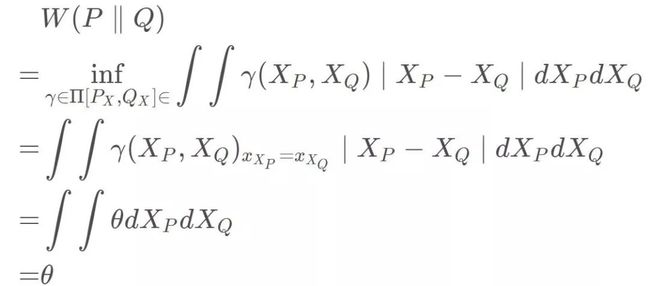
可以看出Wasserstein距离处处连续,而且几乎处处可导,数学性质非常好,能够在两个分布没有重叠部分的时候,依旧给出合理的距离度量。
3对偶问题
如果要计算Wasserstein距离,那需要遍历所有满足条件的联合概率分布,然后计算每个联合概率分布下的总消耗值,最后取最小的总消耗值,在维度较高时,该问题几乎不可解决。与之前fGAN有点类似,当一个优化问题难以求解时,可以考虑将其转化为比较容易求解的对偶问题。关于对偶理论,其最早源于求解线性规划问题,每个线性规划问题都有一个与之对应的对偶问题,对偶问题是以原问题的约束条件和目标函数为基础构造而来的,对于一个不易求解的线性规划问题,当求解成功对偶问题时,其原问题也自然解决。
据此,我们先将Wasserstein距离表示成线性规划的形式,定义向量(即将联合概率分布“离散化”并拉成列向量):

定义向量:

对于两个约束条件,定义矩阵:

定义向量:

定义了这些复杂的矩阵和向量后,我们的Wasserstein距离则可以表达成以下线性规划的形式:

对偶理论是一个非常漂亮的理论,尤其是对于强对偶问题,有:
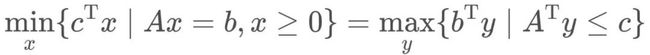
即只需求解原问题的对偶问题,得到对偶问题的解的同时也得到了原问题的解。即使对于弱对偶问题,虽不能精确求解,但是给出了原问题的下界:
在第二篇的fGAN中,我们便给出了f散度的一个下界,不过幸运的是,这次面对的是一个强对偶问题:
对于原问题的对偶问题,我们定义向量:

其限制条件要求,

即

综上所述,有
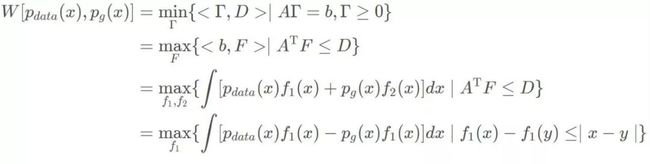
现在,定义一个神经网络F(x)来拟合一下上个式子的f(x),采用抽样计算的方式,就有了WGAN的判别器(现在叫critic)损失函数:

critic不像原始GAN的判别器具有分别真假样本的具象意义了,它的输出代表什么无从知晓。它像一个“部件”,使用这个训练好的部件再加上对样本的充分采样,便能得到两个分布的Wasserstein距离,自然而然,生成器的优化目标是使得Wasserstein距离最小。
这里面存在一个比较难解决的问题,1-Lipschitz限制即要求在任意点,函数的一阶导数在[-1,1]的范围内,这个限制在神经网络中并不容易实现,之后的许多GAN便是围绕这点来展开的。
其实今天着重把Wasserstein距离和计算方法介绍了下,对于比较有难度的Lipschitz限制并未讨论,在接下来的两篇文章中,我们将分别从解决1-Lipschitz限制和IPM的角度继续深入GAN的目标函数。
[1] Arjovsky M, Chintala S, Bottou L. Wasserstein GAN[J]. 2017.
[2] Hong Y , Hwang U , Yoo J , et al. How Generative Adversarial Networks and Their Variants Work: An Overview[J]. ACM Computing Surveys, 2017.
[3]Wasserstein GAN and the Kantorovich-Rubinstein Duality. https://vincentherrmann.github.io/blog/wasserstein/
总结
这篇文章带领大家领略了一下WGAN,学习了一种新的距离度量,展示了使用对偶方法转化Wasserstein距离,最后留了一个大坑,解决1-Lipschitz问题,
下期预告:Lipschitz限制与SNGAN
如果想加入我们,后台留言吧
转载文章请后台联系
侵权必究
技术交流请移步知识星球
更多请关注知乎专栏《有三AI学院》和公众号《有三AI》