作为大数据团队,需要给公司的各条业务线提供数据服务。为了更好地洞察用户行为,支撑各大事业群的产品和运营同学给用户提供更好、更深层次的服务,我们自研了流量分析平台 APPDATA,代替了分散在各个事业群和业务线的商业化流量分析工具,完成了流量分析的全集团统一。本文介绍 APPDATA 的演进过程,主要包括:1)满帮流量分析的业务背景,以及 APPDATA 的产品定位;2)立项之初的技术架构和实现及遭遇到的问题;3)将 Kylin 作为 APPDATA 的核心多维分析引擎所带来的巨大改变;4)对 Kylin 的一些调优操作,以及为了更好的满足业务需求,对 Kylin 做出的一点改造。
APPDATA 是什么?
满帮流量分析的场景特点
第一个特点,满帮流量数据规模盘大。满帮集团作为全国最大的车货匹配信息平台,连接着上千万的司机和货主用户,这些用户每天都会访问平台各种各样的产品来进行发货、找货,以及使用一些如加油、ETC充值、借贷等服务,从而每天会产生近十亿的流量数据,近半年的数据累计达千亿级。
第二,业务重度依赖流量分析。海量的流量数据记录着非常丰富的用户行为。无论哪条业务线,无论是管理者、数据分析师、产品经理,还是运营人员,都非常希望深入分析流量数据,以此来洞察用户,为各项业务的展开提供决策支持。业务线对流量分析的诉求十分强烈,数据团队每周会收到几十个流量数据相关的需求。
第三,人工提数方式处理需求。在数据团队成立的初期,我们以人工提数的方式处理需求。业务人员每周会把需求提交给数据分析师,数据分析师进行排期、写 SQL 提数,最后把数据反馈给需求方。这种方式非常的原始低效,一方面,业务人员要等较长的时间才能拿到结果;另一方面,人工处理需求的成本非常高,当时我们有两个数据分析师全人力投入支持。
APPDATA 产品定位
针对上述流量分析场景的特点,我们希望能有一款自助流量分析的数据产品,提供给业务人员,快速高效的响应流量分析的需求。同时,也可以将那两个 all in 在 流量数据提取工作上的数据分析师解救出来,让他们能专注到更需要「人智」的数据处理工作上。这款自助流量分析产品就是 APPDATA。我们盘点了之前收到所有流量分析相关的提数需求,梳理出了 APPDATA 的 Feature List:
多维查询:提供在不同维度组合下,页面/自定义事件的PV、UV、停留时长等指标查询;
自定义漏斗分析:支持用户自定义漏斗转化路径,由系统计算出漏斗每步骤的人数、转化率;
留存分析:提供留存分析,帮助产品做黏性分析;
用户画像:实现流量数据和用户画像标签数据的联动,提供用户画像信息查询;
我们希望通过这四个功能覆盖 80% 的流量分析需求,通过产品满足数据分析,让大数据在驱动业务中工具化,自动化。
早期方案和挑战
明确产品规划之后,我们开始推进产品落地。
早期方案
立项之初,出于效率优先的考虑,采用的方案如下图所示:
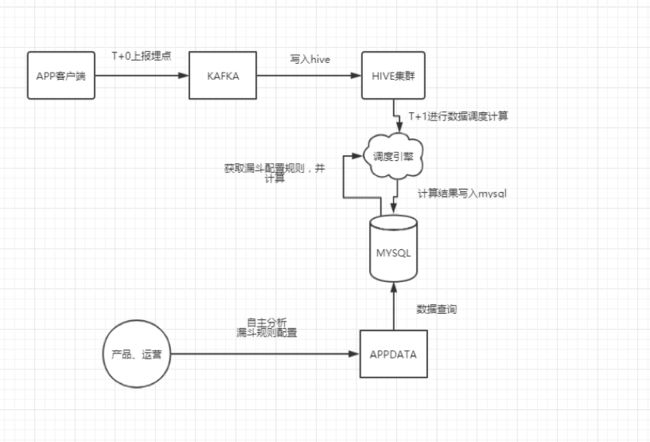
用户访问客户端产生埋点数据,上报到数据团队的集群,落到 Hive 中,数据分析师根据业务人员的查询需求,提前编写相应的 SQL 逻辑,在 Hive 中进行计算,通过流程引擎每天将数据结果导入到 MySQL 中,前台再根据相应的筛选条件,进行数据查询以及结果呈现。早期方案能实现以下功能:
- T+1 的单维度下,页面/自定义事件的PV、UV、停留时长指标查询;
- 自定义漏斗分析,但漏斗模型配置后第二天才会生效输出数据;
- 有限的留存数据查询,仅支持每个埋点的次日留存人数;
可以看到早期方案实现的效果远未达到最初产品规划的效果,仅能覆盖最基础的流量数据查询需求。然而,随着业务的发展和业务人员数据意识的增强,对流量数据的查询越来越精细化,用户希望得到更丰富的维度、更及时的数据。
早期方案面临的挑战
早期方案存在怎样的问题,导致 APPDATA 无法满足精细化的流量数据查询?总结有以下四个原因:
- 仅支持单维度条件查询,UV 无法实现二次聚合。UV 的计算不是单纯的相加,需要依据 UID 做去重计算。早期方案需要数据分析师根据用户的查询需求,提前编写 SQL 计算逻辑,而多维度下的 UV 查询需要根据用户的查询条件实时做去重计算,很显然早期方案无法做到。
- 用户自定义的数据,如漏斗分析,配置需要 T+1 才能生效。用户在系统上新建漏斗,需要第二天才能看到结果。这个延迟是非常影响业务,因为新加的漏斗,往往会包含新上线的埋点,那么新上线的埋点需要 T+1 出数据,漏斗配置又需要 T+1 才有数据,无法在最好的时机支持运营策略和产品设计上的调整。
- 人工编写 SQL 计算逻辑,维护起来很困难,开发周期长。APPDATA 上流量指标的计算较为复杂,由数据分析师编写 SQL 逻辑,维护起来很麻烦,当有调整时,需要一定的开发周期,无法快速响应业务上的诉求。
- 埋点数据量庞大,导致 MySQL 查效率低。系统时常出现查不出来数据的情况,使得用户对系统的可靠性产生怀疑。
基于 Kylin 的解决方案
针对上述存在的诸多问题,研发团队提出引入 Kylin 作为系统的核心计算引擎加以解决。
为什么选择 Kylin?
回答这个问题,主要还是从实际面临的问题出发思考。下图的左边是上文提到的早期方案存在的四个问题,右边是 Kylin 的一些特性,可以看到 kylin 特性能较好的解决问题。
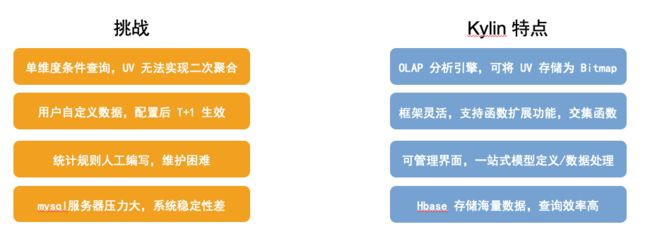
Kylin 是一个 OLAP 引擎,可以非常快速的响应海量数据的多维查询场景。对于 UV 二次聚合,可以将 UV 存储成 Bitmap,这样就可以实现根据用户查询条件的二次聚合;
Kylin 有灵活的框架,支持函数功能扩展,可以利用它提供的交集函数解决自定义数据 T+1 生效的问题;
Kylin提供了一个可视化管理界面,只需在前期对数据做简单的处理和转化,后续的数据处理工作都可以在界面上完成,包括定义 Cube 模型、处理数据、到最后的查询,不用写一行代码,可以大大的提高效率;
-
Kylin 使用 Hbase 来存储数据,不会有 MySQL 那样存太多导致查询效率低的问题。
除此之外,还有两个原因:
一个是成本问题,Kylin 支持标准 SQL,可用使用 JDBC 连接,早期方案也使用 JDBC 连接,新旧方案切换成本比较可控;
Kylin 支持 T+0 Cube构建,可以让 APPDATA 提供 T+0 流量数据查询,我们认为实时数据的查询也是非常有必要的。
基于上述的这些原因,我们选择引入 Kylin 作为 APPDATA 的核心计算引擎。
Kylin 和 APPDATA 结合的技术架构
APPDATA 和 Kylin 结合的技术架构图如下所示:
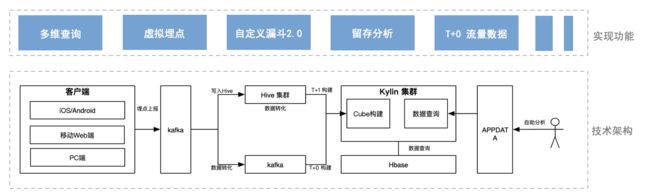
从左往右,客户端产生埋点数据,上报到大数据,这些数据首先通过 Kafka 接进来,对于 T+1 的数据,数据写入 Hive,每天的凌晨根据事先写好的 SQL 逻辑对数据做简单的处理和转化,最终形成一张宽表, 然后根据配置好的 Cube 模型,每天构建一次,然后将结果数据导入到 Hbase。对于 T+0 的数据处理,数据进来后会落到 kafka,在两个 kafka 之间我们用程序做了数据转化的工作,最终的效果也是形成一张宽表,这里和离线数据不同的是,Cube 构建是每十分钟构建一次,同样的,结果数据也会导入到 Hbase。数据都准备好之后,剩下的就是响应用户的查询了。
新方案能做到哪些早期方案做不到的功能:
- 多维查询:系统有十多个维度可以相互交叉,并且和任意日期关联。在新的方案中,对于这种多维的查询,不再需要像以前一样,提前梳理用户可能查询的指标,对数据建模,然后再进行复杂的数据处理,只需要对数据进行简单的处理和转化,配置好 Cube 的模型,然后构建 Cube,APPDATA 根据查询条件生成相应 SQL 请求 Kylin,就可以得到结果,整个过程非常的优雅;
- 虚拟埋点:虚拟埋点就是若干个埋点组合成的埋点,在很多场景下,只查询单个埋点的数据是不够的,需要拉通全域流量数据来看。而虚拟埋点涉及到 UV 聚合去重,早期方案是做不到的,而在新的方案中,只要用户把这个虚拟埋点具体包含哪些埋点告诉系统,系统生成 SQL 去查询 Kylin 就可以;
- 自定义漏斗2.0:在新方案中,我们利用 Kylin 提供的交集函数,实现了漏斗配置后即刻返回结果数据的效果;
- T+0 流量数据:新的方案实现了 T+0 的流量数据查询,端到端的延迟大概是15分钟左右。
显然,新的实现方式能够更近一步支持精细化的流量分析,提供丰富的维度、T+0 的数据、即时灵活的自定义数据,让系统的功能得到了非常强大扩展。
数据情况和运行效率
硬件配置
Kylin 集群总共有三台服务器,一台用于构建 Cube,两台用于查询;HBase 服务器一共八台,每台机器内存 256GB,CPU24 核,硬盘 8TB;计算集群服务器 60 台,内存 192GB,CPU 24 核,硬盘 144TB。
数据量
目前 APPDADA 生产线上有 5 个 Cube,每天有八九亿的数据增量,提供近半年数据查询,共累计了 10+T 的数据。接入了 8 个客户端,覆盖公司所有业务线的流量数据。
并发量
APPDATA 以 Web 服务和 API 两种形式服务于公司内部业务人员和业务系统,业务人员的数量在 150 个人左右,对接广告系统、活动运营平台两个业务系统。
查询效率
查询的效率依赖于查询条件的复杂程度,经过简单的测试,目前我们 85% 的查询是小于 800 毫秒,95% 的查询小于 3 秒,99% 的查询小于 7 秒。
调优和改造
在文章的最后,介绍在使用 Kylin 的过程中,做的一些调优操作,以及为了实现业务上的需求,对 Kylin 做的一点改进。
性能调优
首先,我们对维度做了优化。Kylin 核心的工作就是构建 N 个维度的 Cube,实现聚合的预计算。理论上,构建 N 个维度的 Cube 会生成 2 的 N 次方个 Cuboid。随着维度的增加,Cuboid 的数量会爆炸式地增长,给 Cube 的构建带来巨大的压力。而在实际数据查询中一些维度之间的组合是不必要的。这样就可以通过修剪无查询需求的 Cuboid,来缓解 Cube 构建的压力。
第二个是 Rowkey 的顺序优化。一般而言,Kylin 以 HBase 作为存储引擎,而 HBase 是以 Rowkey 顺序存储行的,设计良好的 Rowkey 将更有效地完成数据的查询过滤和定位,减少 IO 次数,提高查询速度。这意味着我们可以把查询中被用作过滤条件的维度放在非过滤条件维度的前面,基数较高的维度,放在基数较低维度的前面,这样就可以跳过一些不必要的扫描,快速的定位到查询场景。通过种方式,可以将绝大部分的查询效率稳定在亚秒级。
上述的这两个调优操作都能在 Kylin 提供的可视化界面的「高级配置」设置完成。
在应用层面的一点改进
为了帮助提升产品关键路径的转化,我们支持产品同学到 APPDATA 上构建漏斗,上文中提到我们用 Kylin 提供的交集函数来计算漏斗数据。假设一个两步的漏斗,计算时,先分别独立计算访问过两个步骤的用户数,得到的第一步的用户数作为第一步的人数,然后求两群人的交集,得到的人数作为第二步的人数。这里的求交集就是用到交集函数。
为了满足业务上的需要,在配置漏斗时,每一个步骤可以是单个的埋点,也可以是由多个埋点组合成的虚拟埋点。而单个埋点和虚拟埋点是有差异的,前者是物理上的概念,后者是逻辑上的。Kylin 原本提供的交集函数只能支持物理概念上的单个埋点,而不支持多个埋点组合成虚拟埋点,也就是说,不可以先对单个埋点求并集,然后再求交集。在这里,我们所做的改造就是扩展交集函数支持逻辑上的虚拟埋点。可以看到扩展后,我们可以先让单个埋点做或者运算,再求交集。
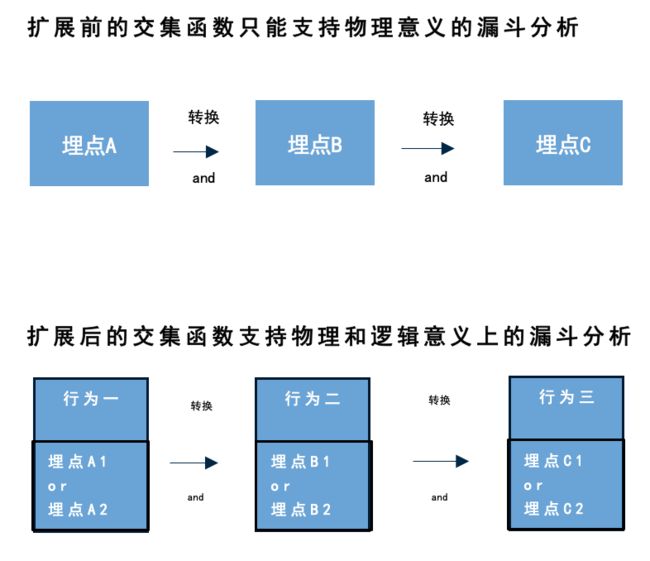
我们用扩展后的交集函数计算漏斗和留存数据。对于漏斗,用户先创建虚拟埋点,绑定若干个埋点,再创建漏斗,后台调用交集函数,给出结果。对于留存数据,用户也是先创建虚拟埋点,系统调用交集函数,计算每个虚拟埋点的日留存、周留存、月留存数据。
写在最后
本文最早发布在 apachekylin 公众号,以及infoQ,如需转载请注明出处和作者名字。