跟着官方文档看,外加查到的一些资料
官方文档戳这里,中文版戳这里(安装方法完全可以按照tutorial,很详细,开启服务记住这一句就ok:bin/drill-embedded)
FYI:本文和大部分介绍drill的文字一样无聊,,可能drill都是这么点东西,而且是同一版翻译
Running in embedded mode
安装完可以通过http://localhost:8047/ 访问,也可以:
- cd (path)/drill
- bin/sqlline -u jdbc:drill:zk=local
- Run a query (below).
如果想修改配置,进入drill下conf文件夹,drill-env.sh中可以添加配置信息
简介
- Apache Drill是一个低延迟的分布式海量数据(涵盖结构化、半结构化以及嵌套数据)交互式查询引擎。分布式、无模式(schema-free)
- 是Google Dremel的开源实现,本质是一个分布式的mpp(大规模并行处理)查询层,支持SQL及一些用于NoSQL和Hadoop数据存储系统上的语言
- 更快查询海量数据,通过对PB字节(2的50次方字节)数据的快速扫描完成相关分析
- Drill 提供即插即用,在现有的 Hive 和 HBase中可以随时整合部署。
- 是MR交互式查询能力不足的补充
- 数据模型,嵌套
- 列式存储
- 结合了web搜索和并行DBMS技术
注:Hive (Hive就是在Hadoop上架了一层SQL接口,可以将SQL翻译成MapReduce去Hadoop上执行,这样就使得数据开发和分析人员很方便的使用SQL来完成海量数据的统计和分析,而不必使用编程语言开发MapReduce那么麻烦。)
有一套笔记讲Hive,戳这里
Drill 核心服务是 Drillbit,
Drillbit运行在集群的每个数据节点上时,可以最大化执行查询,不需要网络或是节点之间移动数据
接口
- Drill Shell
- Drill Web Console
- ODBC/JDBC
- C++ API
动态发现Schema
处理过程中会发现schema,
灵活的数据模型
允许数据属性嵌套,从架构角度看,Drill提供了灵活的柱状数据模型
无集中式元数据
不依赖单个的Hive仓库,可以查询多个Hive仓库,将数据结果整合
查询执行
提交一个Drill查询,客户端或应用程序会按照查询格式发一个SQL语句到Drillbit,Drillbit是一个执行入口,运行计划并执行查询
Drillbit街道查询请求后会变成Foreman来带动整个查询,先解析SQL,然后转变成Drill可以识别的SQL
logical plan 描述生成查询结果所需要的工作,并定义数据源和操作,由逻辑运算符的集合构成。

Major Fragments
- a concept that represents a phase of the query execution
- A phase can consist of one or multiple operations that Drill must perform to execute the query.
- Drill assigns each major fragment a MajorFragmentID
- Drill uses an exchange operator to separate major fragments. An exchange is a change in data location and/or parallelization of the physical plan. An exchange is composed of a sender and a receiver to allow data to move between nodes.
Minor Fragments
- Each major fragment is parallelized into minor fragments.
- A minor fragment is a logical unit of work that runs inside a thread. A logical unit of work in Drill is also referred to as a slice.
-
The execution plan that Drill creates is composed of minor fragments. Drill assigns each minor fragment a MinorFragmentID.
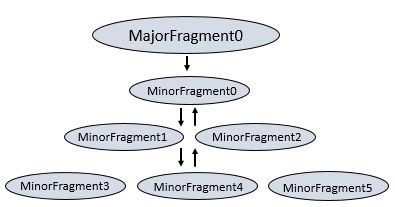
- 流程
The parallelizer in the Foreman creates one or more minor fragments from a major fragment at execution time, by breaking a major fragment into as many minor fragments as it can usefully run at the same time on the cluster.
Drill executes each minor fragment in its own thread as quickly as possible based on its upstream data requirements. Drill schedules the minor fragments on nodes with data locality. Otherwise, Drill schedules them in a round-robin(RR时间段执行方法) fashion on the existing, available Drillbits. - Minor fragments contain one or more relational operators. An operator performs a relational operation, such as scan, filter, join, or group by. Each operator has a particular operator type and an OperatorID. Each OperatorID defines its relationship within the minor fragment to which it belongs.
Execution of Minor Fragments
Minor fragments can run as root, intermediate, or leaf fragments. An execution tree contains only one root fragment. The coordinates of the execution tree are numbered from the root, with the root being zero. Data flows downstream from the leaf fragments to the root fragment.
The root fragment runs in the Foreman and receives incoming queries, reads metadata from tables, rewrites the queries and routes them to the next level in the serving tree. The other fragments become intermediate or leaf fragments.
Intermediate fragments start work when data is available or fed to them from other fragments. They perform operations on the data and then send the data downstream. They also pass the aggregated results to the root fragment, which performs further aggregation and provides the query results to the client or application.
The leaf fragments scan tables in parallel and communicate with the storage layer or access data on local disk. The leaf fragments pass partial results to the intermediate fragments, which perform parallel operations on intermediate results.
Minor Fragment可以作为root、intermediate、leaf Fragment三种类型运 行。一个执行树只包括一个root Fragment。执行树的坐标编号是从root 开始的,root是0。数据流是从下游的leaf Fragment到root Fragment。
运行在Foreman的root Fragment接收传入的查询、从表读取元数据,重 新查询并且路由到下一级服务树。下一级的Fragment包括Intermediate 和leaf Fragment。
当数据可用或者能从其他的Fragment提供时,Intermediate Fragment启 动作业。他们执行数据操作并且发送数据到下游处理。通过聚合Root Fragment的结果数据,进行进一步聚合并提供查询结果给客户端或应 用程序。
Leaf Fragment并行扫描表并且与存储层数据通信或者访问本地磁盘数 据。Leaf Fragment的部分结果传递给Intermediate Fragment,然后对 Intermediate结果执行合并操作
Query
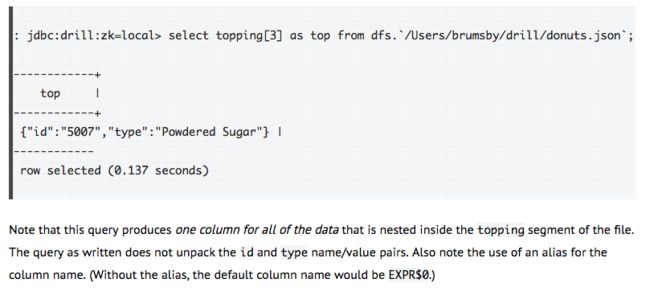
- 比如一个查询语句:select id, type, name, ppu
from dfs./Users/brumsby/drill/donuts.json;
Note that dfs is the schema name, the path to the file is enclosed by backticks, and the query must end with a semicolon.
-
注意需要as top
 Paste_Image.png
Paste_Image.png
如果是嵌套数组,the third value of the second inner array).
select group[1][2] 一个复杂的SQL语句
SELECT * FROM (SELECT t.trans_id,
t.trans_info.prod_id[0] AS prod_id,
t.trans_info.purch_flag AS purchased
FROM `clicks/clicks.json` t) sq
WHERE sq.prod_id BETWEEN 700 AND 750 AND
sq.purchased = 'true'
ORDER BY sq.prod_id;
REST API
get/post,文档在这里,有个jsonapi相关的文档,写的很好,而且也有代码,是我当时看的时候的参考资料
待续。。