RxJava是近两年来越来越流行的一个异步开发框架,其使用起来十分简单方便,功能包罗万象,十分强大。
但当我们想跟进去源码一窥究竟的时候却发现,它的实现逻辑比较复杂,注释又写得比较简单,加之其中的类与对象名一直在subscribe,observe,observable等几个单词来来回回,让人眼睛越看越瞎,经常看着看着就被绕进去了。
虽然网上关于RxJava分析的文章有很多,但刚接触的时候,也跟很多人一样,看完还是觉得似懂非懂。在这里,我们将试图只抽出主干代码,以代码执行顺序来描述RxJava,回答这几个问题。
RxJava框架内部的主干逻辑是怎样的?
RxJava究竟是如何实现一句话线程切换的?
多次调用
subscribeOn()或observeOn()切换线程会有什么效果?
回答了这几个问题以后,我们大概就能对RxJava的基本原理有初步的认知了。
这里的代码抽取自RxJava2,RxJava1虽然在实现上有一定程度的不同,但其核心思想与原理是一样的。
RxJava的基本角色
一般我们使用RxJava都是编写类似如下的代码:
Observable.create(new ObservableOnSubscribe()) //创建一个事件流,参数是我们创建的一个事件源
.map(...)//有时我们会需要使用操作符进行变换
.subscribeOn(Schedulers.io())//指定事件源代码执行的线程
.observeOn(AndroidSchedulers.mainThread())//指定订阅者代码执行的线程
.subscribe(new Observer())//参数是我们创建的一个订阅者,在这里与事件流建立订阅关系
RxJava是一种基于观察者模式的响应式编程框架,其中的主要角色有:
Observable 是RxJava描述的事件流,在链式调用中非常清晰,事件从创建到加工处理再到被订阅者接收到,就是一个接一个的Observable形成的一个事件流。在上面代码中,每一步方法的调用,都会返回一个新的Observable给下一步,这个是RxJava源码的基础。同样是链式调用,但它与我们常见的Builder模式不太一样,每个操作符,每次线程切换,每步都会新建一个Observable而非直接加工上一步的Observable返回给下一步。(在源码中不同的加工会创建不同的Observable,比如map()会创建一个ObservableMap,subscribeOn()会创建一个ObservableSubscribeOn,但它们实际上都是Observable的子类)。
ObservableOnSubscribe 是这个事件流的源头,下面我们称之为事件源,一般由我们自己创建并传入。我们创建时,需要重写其subscribe()方法,为了和Observable中的subscribe()方法区别,我们将在下面贴出的代码中将其改名为call()。我们在调用链中有时会用到各种操作符进行一些变换,事实上每个操作符都会重写这么一个call()方法,相对于我们创建事件源时在这里写入的源业务代码,这些操作符在这里要做的事是由RxJava钦定的,一般是连接事件流的上下游。在这里我们将准备好被订阅的数据,并调用subscribe()参数中ObservableEmitter的onNext(),onCompleted()或onError()通知订阅者数据准备情况。
Observer 是整个事件流的订阅者,也就是说,它将会订阅前面事件创建,加工以后的最终结果。它也是由我们创建的,我们将要重写它的onNext(),onCompleted(),onError()和onSubscribe(),在接下来的分析中我们将简化一些,只关注onNext()。我们创建出了Observer以后,将会使用经过上面所有步骤的最后一步生成的Observable,调用它的subscribe(),与事件源产生联系。
最简单情况
我们先来看最简单的情况,没有使用操作符,没有切换线程。我们写的调用代码是下面这样的(以下源码都是精简、改写过后的主干逻辑代码),为了区分,我将ObservableOnSubscribe中的subscribe()改叫call(),于是:
Observable.create(new ObservableOnSubscribe去繁就简,订阅者中我们暂时只关注onNext()。我们在这里,创建了一个事件源,一个订阅者,并以订阅者为参数调用了subscribe()。那么其中的调用过程是怎样的呢?我们跟进源码看看。
先看Observable类的静态方法create():
public class Observable {
final ObservableOnSubscribe source;
...
public static Observable create(ObservableOnSubscribe source) {
return new Observable(source);
}
可以看到create()使用我们在参数中提供的source创建了一个Observable(实际上创建的是ObservableCreate,但是为了简化代码,我们统一视作Observable,下同)。其中ObservableOnSubscribe是个接口,我们创建的时候必须重写它的call()方法,我们的源业务代码就写在这里面。
然后看Observable类中的subscribe()方法:
public class Observable {
final ObservableOnSubscribe source;
protected void subscribe(Observer observer) {
source.call(observer);
}
其中参数中的observer就是我们创建传入的订阅者。可以看到,subscribe()中回调了我们重写的call(),并把我们创建的订阅者以call()参数的形式交给了事件源。这样在call()中,我们就可以在我们的事件源业务代码中适时调用onNext(o),这样,就将事件源和订阅者联系了起来。也就是说,调用subscribe()方法实际上建立了我们创建的事件源与订阅者的订阅关系。如果画图来描述代码执行的流程的话,就是:
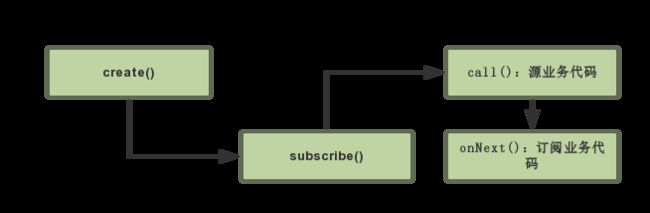
上面这张是代码执行顺序图,在这张图中我们发现,所有的业务代码都是在subscribe()调用以后才会执行的。也就是说,在我们使用RxJava的时候,不管前面调用了create(),map()或是observeOn()等等有多少东西,只要没有调用subscribe(),所有的业务代码,包括事件源的代码,都不会执行。
流程中加上一个操作符
有时我们会使用操作符对事件源产生的数据进行变化,这里以比较常见的map()为例,我们来看一下作为一个链中的中间过程,RxJava是怎样做到承上启下的。
map()的作用是将传递的数据类型进行转换,比如调用map()的上游是一个Observable
Observable.create(new ObservableOnSubscribe我们在这段代码中先是创建了一个事件源,然后中间经过了一次map()的转换,使创建出的Observable转换成为了Observable传递到下游,最后进行订阅。那么在这个过程中,RxJava是如何连接起这个事件流的,内部又进行了什么处理使得我们的业务代码最终能按顺序执行呢?我们将map()的源码精简一下:
public final Observable map(Function mapper) {
//第一层
return create(new ObservableOnSubscribe() { //新建了一个事件源
@Override
public void call(@NonNull Observer 这段代码中,有几个很重要的地方:
首先,我们必须要清楚,这里的代码的执行顺序并不是顺序执行的,它包含了三层,其中后两层都是回调层,只有第一层会被立即执行,后面两层要等到回调时才会执行。
我们先看第一层,我们发现在RxJava在map()中,跟我们创建原始Observable一模一样地调用了一次create()创建了一个Observable,并将它返回给了下游。我们可以理解为,我们使用map()操作符时,实际上用它创建的新的Observable替换掉了我们自己用create()创建的包含了我们业务代码的那个Observable。那我们创建的原始Observable去哪里了呢?接着看。
接着我们看到第二层,在Observable中我们写源业务代码的地方(重写的call()中)调用了subscribe()。subscribe()在上文中我们已经提到,他联系起了事件源与订阅者。要注意的是,在这里subscribe()的调用者是调用map()的Observable,也就是我们创建的原始Observable。所以它建立订阅关系的是我们创建的原始Observable与map()创建的新订阅者。根据上文,这个call()方法的调用时机,是下游也就是我们自己手动调用subscribe()时。而这里第二层的subscribe()又将回调原始Observable创建时我们重写的call()。也就是说,这一层的执行顺序是向上的,由我们手动调用subscribe()起,向上回调call()并调用上游的subscribe(),直到调用我们创建的原始Observable中重写的call(),也就是我们的源业务代码。
我们再看第三层,在新创建的订阅者中的onNext(),调用了call()参数中的订阅者,也就是下游由我们创建的,包含我们订阅业务代码的订阅者的onNext()。也就是说,现在我们的源业务代码执行结果将交给由map()创建的订阅者,而它又将交给我们的订阅业务代码。这里的实现,有点类似于链表中增加一个节点,创建一个新节点,由上游直接指向下游,变为上游指向新节点,新节点再指向下游。
而我们使用map()产生的类型转换,就发生在mapper.call(var1)中,在第三层。
我们画个图总结一下这里的顺序:
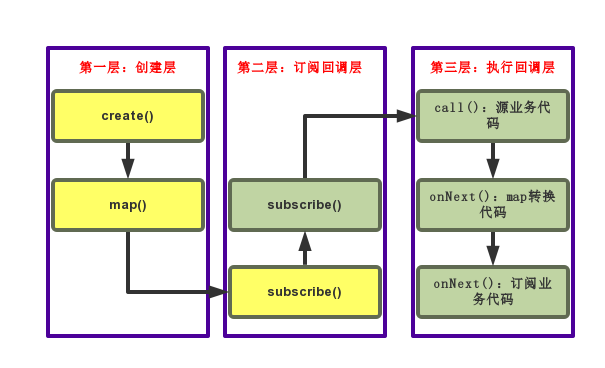
黄色是我们上面代码使用RxJava时调用的三个步骤。由这个流程图我们可以很清楚地看到,RxJava的整体执行顺序分成了三层。
第一层,是我们使用RxJava时进行的一系列链式调用,每次调用实际上都创建了一个新的Observable返回给下层,这一层的目的,就是创建一个个Observable,终点是subscribe()的调用,由此开始进入第二层。第一层按顺序执行完毕时,这些新建的Observable之间实际上还并没有建立联系。
第二层,是逆向顺序的回调层,以我们手动调用的subscribe()开始,逐级向上游回溯。每一级的subscribe()都会调用上级重写的call(),而中间每一级的call()又会调用subscribe(),直到调用到我们创建的原始Observable中重写的call(),开始执行我们的源业务代码,进入第三层。这一层的目的,是逐级建立订阅关系,我们的订阅业务代码被包含在原始Observer中,由我们手动调用subscribe()(黄色subscribe())开始,向上逐级传递。这一层执行完毕以后,第一层创建的每个Observable才真正形成了一条链。
第三层,是正向顺序的回调层,从我们的源业务代码所在的call()开始,顺序执行,并由onNext()将结果传递至下一级。可以看到,我们在map()中写入的告诉RxJava具体如何进行转换的代码,同其他业务代码一样,也是在这一层执行的。
切换线程
我们再来看RxJava是如何实现切换线程的。通常我们使用RxJava的线程切换功能时,只需要在调用链中加上一句subscribeOn()或observeOn()。参数中传入的是一个Scheduler,这个Scheduler是一个调度器,这里不具体解释其运作原理,简单来说,在我们调用subscribeOn(Schedulers.io())或是subscribeOn(AndroidSchedulers.mainThread())时,RxJava将会依照我们提出的不同线程要求,在不同的线程池中选择线程为我们执行代码。
subscribeOn
先看subscribeOn()的简化源码:
public final Observable subscribeOn(Scheduler scheduler){
//第一层
return Observable.create(new ObservableOnSubscribe() {
@Override
public void call(@NonNull ObservableEmitter 我们发现跟map()类似,它同样是创建一个新的Observable返回给下游。然而它重写的call()中,没有调用subscribe()而是直接调用了上游的call(),因为它除了切换线程之外并没有其它的事情需要做。而且,调用上游的call()这件事是在使用调度器分配的一个新的线程中进行的。注意,我们在这里与之前的map()相比发现,切换线程这件事是执行在第二层,订阅回调层的,而它并没有创建相应的第三层。也就是说,我们使用subscribeOn()切换线程时,在第二层就已经切换了,这个时候我们所有的业务代码都还没有执行,它们要到第三层才会执行!
这里看图更加直观:
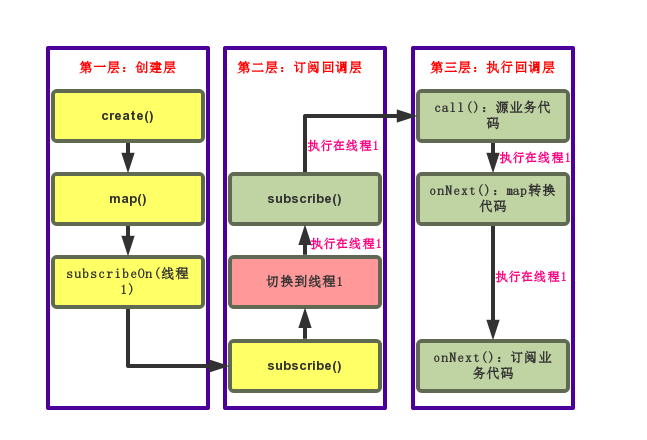
可以看到subscribeOn()产生的线程切换发生在代码执行的第二层,而它的回溯又将会执行在新的线程中。因此,在subscribeOn切换线程以后的流程,均将在新的线程中执行。也就是说,如果我们只调用了subscribeOn()进行线程切换,将改变后面包括源业务代码、操作符转换、订阅业务代码的所有业务代码,的执行的线程。
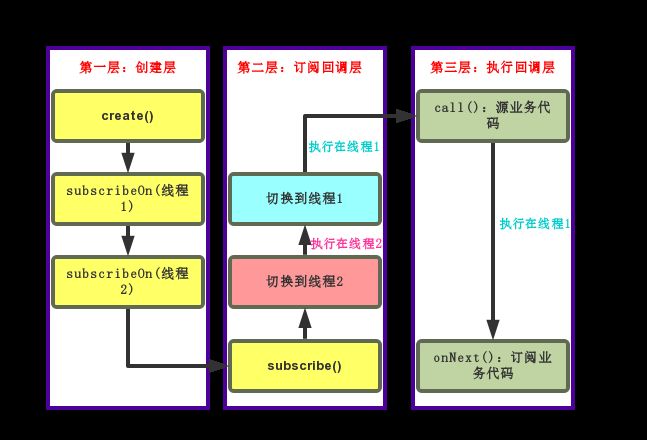
如果我们多次调用subscribeOn()进行线程切换会产生什么效果呢?从图中可以看出,虽然在第二层中每次切换以后后续的代码都会在新线程中执行,但是真正影响到执行层的只有最后一次切换,也就是我们手动调用subscribeOn()的第一次。我们第二次调用subscribeOn()实际上也起了作用,但它只影响了图中第二层中的一段代码的,而我们的业务代码均执行在第三层,所以我们在平时使用RxJava时是无法感觉到其效果的。
observeOn()
我们再来看observeOn():
public final Observable observeOn(Scheduler scheduler) {
//第一层
return Observable.create(new ObservableOnSubscribe() {
@Override
public void call(@NonNull Observer 可以看到,observeOn()的结构就跟map()非常相似了,同样是分了三层。它在第二层与subscribeOn()一样,调用了上层的call()进行回溯,不同的是在这里它并没有在一个新线程中做这件事。observeOn()的线程切换发生在第三层,也就是在执行层。此时,它上游的业务代码已经执行了,将结果传递到它这里,它才进行线程的切换并在新线程中继续向下游执行。也就是说,observeOn()不会影响调用链中在它前面的流程,而在它后面的流程全部都将在切换后的新线程中执行。
Observable.create(...) //不受影响
.map(...)//不受影响
.observeOn(线程1)//切换到线程1
.map(...)//在线程1执行
.subscribe(new Observer我们再画个流程图,比较清楚:
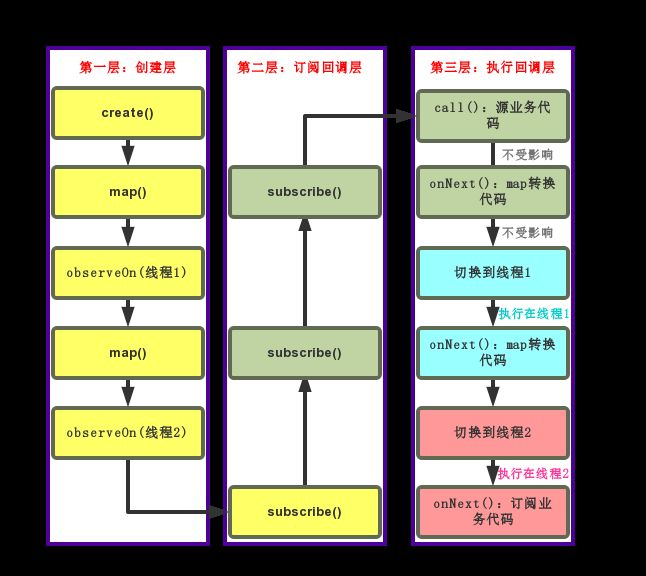
图中看的非常清楚,两次调用observeOn()产生的线程切换都发生在第三层执行层,而在切换线程前的业务代码由于已经执行了,故不受切换线程切换的影响。
这里我们还看到,在我们多次调用observeOn()进行线程切换时,每次调用都将改变下次调用observeOn()前部分的代码执行线程,而我们的订阅业务代码将执行在链中最后一次调用observeOn()指定的线程。
总结
RxJava的主干分为了三层,其中第一层创建Observable,第二层从下游回溯建立起上下游的订阅关系,第三层开始真正执行我们提供的所有的业务代码。其中,操作符进行的转换发生在第三层,而我们调用subscribeOn()切换线程发生在第二层,调用observeOn()切换线程发生在第三层。
到此,我们只是通过精简过的代码初步了解了RxJava的主干逻辑和基本原理,实际上RxJava的源码中进行了大量的封装与解耦,同时还包括了错误处理,背压处理以及订阅回收等一系列的东西。我们要完全了解这个框架的精妙之处,还需要下一番功夫。
很惭愧,做了一点微小的工作,谢谢大家。