原文网址:http://colah.github.io/posts/2015-08-Understanding-LSTMs/
注:本文是根据原文的理解来摘译的,不是像其他博文仅仅是全盘翻译,因为自我感觉即使原文每一个词都认识,都会翻译,还是不容易通俗的理解(可能是我理解能力差吧)。所以,这里我只翻译了最主要的内容,然后写下自己查考其他资料的理解。
之所以是“试图理解”,是因为我的理解可能还有偏差,不够深入。所以要想深入,建议亲自看看原文。
RNN(Recurrent Neural Network 循环神经网络)
人们在理解的时候,比如读一篇文章,都会结合前文的意思来理解当前词语句子的意思,而不是看了后面就忘了前面,这样的话我们很难理解文章的意思。简而言之,我们的记忆可以持续。
但是传统的神经网络模型(Traditional Neural Network)却不能做到这一点,这也是它的一个主要的缺点。
RNN就是来解决这个问题的,它在网络中添加了“循环”(loops),让信息可以更持久。如图所示:

A代表一个神经网络,Xt为输入,Ht为输出,中间的环表示信息可以不断的在神经网络内传播,从上一步传到下一步。
但是光看这个图也是有点费解,可以将它展开,也就是说,上面的结构等价于下面这种结构:

这样就更清晰一些,相当于每一次神经网络的判断过程之后,都会把信息传给下一次判断过程,就类似于我们人脑的思考理解过程了。
事实上,RNNs确实取得了惊人的成就,在语音识别、语言模型、机器翻译、图像捕捉等方面获得了很好的效果。这些成就的核心,其实在于“LSTMs”的使用,LSTM是RNN的一种特殊形式,克服了传统或者说经典RNN模型的问题。
RNNs有啥问题呢?
原文作者举了个例子:”The clouds are in the ___.” 我们要根据前文判断这里应该填啥,很显然答案就是sky,因为这一句前面的信息可以直接推断出来,这也是RNN擅长的地方。

但是很多时候,我们要推断一个词语,需要再前文很远的地方才能找到线索,比如说:”I lived in France, I worked there for many years, I…, I am now fluent in ___.”这里我们首先可以判断出应该填某种“语言”,但是究竟是哪个语言,就需要再往前找,也许很远很远,才能找到France这个词,这样才能确定答案是French。
面对这样的“长距离依赖”(Long-Term Dependencies),RNN的效果就开始变差了。虽然理论上可以通过仔细调参数在解决,但是在实践中,人们发现这个问题很难克服,即RNN很难学习到长距离的信息。

幸好,LSTMs出来,解决了这个问题!
LSTM Networks(Long Short Term Memory Network长短期记忆网络)
其实LSTM最主要的改进之处,就是把神经网络层中对信息的处理变得更加复杂、精细了。先看看传统RNN的内部结构:

如图是三个神经网络,上一个网络的信息(即ht-1)直接传过来,配合当前网络的输入Xt,两者结合之后,再通过tanh层进行信息压缩,就形成当前网络的输出ht。
(这个tanh层就是一个函数,tanh就是双曲正切函数,可以将输入的值转化为-1到1之间的一个值,通常用于对信息的压缩处理,或者规范化处理。这里就不必深究了。)
LSTM的内部结构就稍微复杂一些了

图中有三种元素:红色圈圈,黄色方块,黑色信息流。
红色的圈圈就是各种处理过程,×代表乘法,+就是加法,tanh就是经过tanh函数处理。
黄色方块代表神经网络的一个层,σ是指sigmoid函数层,把数据压缩到0到1的范围,0就代笔信息无法通过该层,1就代笔信息可以全部通过;tanh层就不解释了。
黑色信息流主要要注意信息的流向。
下面就一步步地分解上面的结构,逐层的理解:
1.Cell state(单元状态流)——LSTM的核心
单元状态流就是下面这个水平直线,它用于“记忆”当前的状态,上面包含记忆的删除、更新等。

LSTM有三个“门”来保护和控制cell state。
2.遗忘门

再次说明一下,ht-1是上个网络的output(输出),xt当前网络的input(输入)。
信息输入了之后,σ层就会把信息转化为ft,如果决定要忘记,ft就是0,如果这个信息要保留,则为1,选择部分记忆则按照实际情况输出0~1的数。
为什么要有“遗忘门”?例如,当我们碰到一个新的主语,如Peter,因为是男的,所以如果后面要用代词的话,就要用he而不能用she。但是可能我们在理解之前的语句的时候,cell state中保存的主语是Alice,这样的话我们就需要把Alice忘掉,否则后面的代词就不知道咋用了。
3.输入门
输入门决定什么信息需要被存储进cell state。
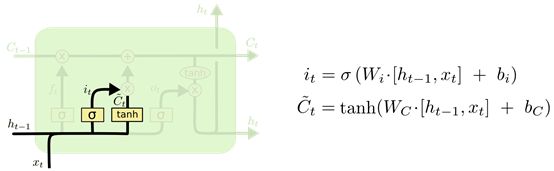
上一个输出加上这一次的输入,统一经过σ层,决定要更新啥信息。还要另外经过tanh层,将信息转化为一个新的候选值(这个我还是不太懂,反正我觉得tanh的作用就是把各种各样的数据都规范化吧),两者再相乘,就是cell state中需要更新的值了。有啥信息需要更新呢?比如cell state是专门存储“性别”的,那么之前的主语性别是女,现在碰到的新主语性别是男,就要把性别更新成男。
——对于输入门的结构,我觉得可以这么形象化地理解:
上一个网络的输出ht-1和这一个网络的输入xt是一群人,要进城门。σ层是门口的扫描仪,让ht-1和xt都经过,看看有没有“违禁物品”,有没有“特殊物品”,扫描之后,就会给后面的关卡报告一个0~1的数,这个数的含义就是告诉关卡你们应该让哪些人通过。
Tanh是门口的服务员,觉得这些人的穿着都各式各样,不便于管理,就给他们每个人都穿上同一款的制服,唯一的区别就是型号不一样。
圈圈里面一个×就是关卡,它手上有扫描仪给它的报告,于是面对这一群穿着统一制服的人,跟他们说“这里只允许**型号的人通过!”。于是,符合要求的人就过关了,不符合的就只能结束旅行了。
这样应该就稍微好理解了吧hhhh~~
上面的两个门,“遗忘门”和“输入门”已经决定好了什么要遗忘,什么要更新保留了,现在要真的在cell state上执行了:
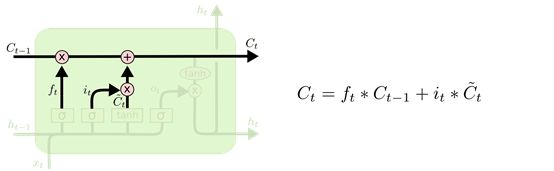
Ct-1就是曾经的记忆,先跟ft一乘,该忘记的就忘记了~~忘记曾经的Ta,忘记曾经的欢声笑语,忘记···哦不好意思,戏精本质暴露了。
接着,cell state加上从输入门传来的要添加的信息。这样,cell就更新了!成为了Ct。
4.输出门
终于要输出了,输出的结果依赖于cell state,这时前面的遗忘、输入的作用就显现出来了。

注意这个图里面:

如图所示,σ层识别哪一部分信息要输出,乘以当前的状态Ct(经过tanh处理过了),就得到了我们的输出。
还是拿实例来说明,例如我们的模型要根据前文预测后文,相当于机器写文章吧。其中一个部分是根据主语写出后面的谓语,不同的主语对应的谓语不同,如I后面是am,We后是are,跟主语是单数还是复数有关,所以这里需要输出“是单数还是复数”这个信息。
这么着LSTM就走了一遍了,其实说实话还是感觉一头雾水,目前感觉只是感性上理解了,但是理性上,尤其是背后的实际算法还是不太理解。
也许接下来就是要实践了,在实践中慢慢地加深理解了。
对于LSTM的理解,还推荐另一篇文章:
https://medium.com/mlreview/understanding-lstm-and-its-diagrams-37e2f46f1714
祝大家学习顺利,欢迎交流!