1 概述
- MapReduce源自Google的MapReduce论文,论文发表于2004年12月
- Hadoop MapReduce可以说是Google MapReduce的一个开源实现
- MapReduce优点在于可以将海量的数据进行离线处理,并且MapReduce也易于开发,因为MapReduce框架帮我们封装好了分布式计算的开发。而且对硬件设施要求不高,可以运行在廉价的机器上
- MapReduce也有缺点,它最主要的缺点就是无法完成实时流式计算,只能离线处理。
MapReduce属于一种编程模型,用于大规模数据集(大于1TB)的并行运算。
概念"Map(映射)"和"Reduce(归约)",是它们的主要思想,都是从函数式编程语言里借来的,还有从矢量编程语言里借来的特性。
它极大地方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。
当前的软件实现是指定一个Map(映射)函数,用来把一组键值对映射成一组新的键值对,指定并发的Reduce(归约)函数,用来保证所有映射的键值对中的每一个共享相同的键组。
在学习MapReduce之前我们需要准备好Hadoop的环境,也就是需要先安装好HDFS以及YARN,环境的搭建方式可以参考我之前的两篇文章
- 大数据入门(四) - 分布式资源调度——YARN框架
- 大数据入门(三) - HDFS 伪分布式环境搭建
2 MapReduce编程模型
通过wordcount词频统计分析案例入门
在安装Hadoop时,它就自带有一个WordCount的案例,这个案例是统计文件中每个单词出现的次数,也就是词频统计,我们在学习大数据开发时,一般都以WordCount作为入门。
例如,我现在有一个test.txt,文件内容如下:
hello world
hello hadoop
hello MapReduce
现在的需求是统计这个文件中每个单词出现的次数。假设我现在写了一些代码实现了这个文件的词频统计,统计的结果如下:
hello 3
world 1
hadoop 1
MapReduce 1
以上这就是一个词频统计的例子。
词频统计看起来貌似很简单的样子,一般不需要多少代码就能完成了,而且如果对shell脚本比较熟悉的话,甚至一句代码就能完成这个词频统计的功能。确实词频统计是不难,但是为什么还要用大数据技术去完成这个词频统计的功能呢?这是因为实现小文件的词频统计功能或许用简单的代码就能完成,但是如果是几百GB、TB甚至是PB级的大文件还能用简单的代码完成吗?这显然是不可能的,就算能也需要花费相当大的时间成本。
而大数据技术就是要解决这种处理海量数据的问题,MapReduce在其中就是充当一个分布式并行计算的角色,分布式并行计算能大幅度提高海量数据的处理速度,毕竟多个人干活肯定比一个人干活快。
又回到我们上面所说到的词频统计的例子,在实际工作中很多场景的开发都是在WordCount的基础上进行改造的。例如,要从所有服务器的访问日志中统计出被访问得最多的url以及访问量最高的IP,这就是一个典型的WordCount应用场景,要知道即便是小公司的服务器访问日志通常也都是GB级别的。
-
使用MapReduce执行WordCount的流程示意图

输入的数据集会被拆分为多个块,然后这些块都会被放到不同的节点上进行并行的计算
在Splitting这一环节会把单词按照分割符或者分割规则进行拆分,拆分完成后就到Mapping
到Mapping这个环节后会把相同的单词通过网络进行映射或者说传输到同一个节点上
接着这些相同的单词就会在Shuffling环节时进行洗牌也就是合并
合并完成之后就会进入Reducing环节,这一环节就是把所有节点合并后的单词再进行一次合并,
也就是会输出到HDFS文件系统中的某一个文件中
大体来看就是一个拆分又合并的过程,所以MapReduce是分为map和Reduce的。最重要的是,要清楚这一流程都是分布式并行的,每个节点都不会互相依赖,都是相互独立的。
3 MapReduce执行流程
MapReduce作业会被拆分成Map和Reduce阶段
- Map阶段对应的就是一堆的Map Tasks
- 同样的Reduce阶段也是会对应一堆的Reduce Tasks
输入与输出
MapReduce框架专门用于
键和值类型必须可序列化,因此需要实现Writable接口
Hadoop Writable接口是基于DataInput和DataOutput实现的序列化协议,紧凑(高效使用存储空间),快速(读写数据、序列化与反序列化的开销小)
Hadoop中的键(key)和值(value)必须是实现了Writable接口的对象(键还必须实现WritableComparable,以便进行排序)。
package org.apache.hadoop.io;
import java.io.DataOutput;
import java.io.DataInput;
import java.io.IOException;
import org.apache.hadoop.classification.InterfaceAudience;
import org.apache.hadoop.classification.InterfaceStability;
/**
* Any key or value type in the Hadoop Map-Reduce
* framework implements this interface.
*
* Implementations typically implement a static read(DataInput)
* method which constructs a new instance, calls {@link #readFields(DataInput)}
* and returns the instance.
* public class MyWritable implements Writable {
* // Some data
* private int counter;
* private long timestamp;
*
* public void write(DataOutput out) throws IOException {
* out.writeInt(counter);
* out.writeLong(timestamp);
* }
*
* public void readFields(DataInput in) throws IOException {
* counter = in.readInt();
* timestamp = in.readLong();
* }
*
* public static MyWritable read(DataInput in) throws IOException {
* MyWritable w = new MyWritable();
* w.readFields(in);
* return w;
* }
* }
*/
@InterfaceAudience.Public
@InterfaceStability.Stable
public interface Writable {
/**
* Serialize the fields of this object to out.
*/
void write(DataOutput out) throws IOException;
/**
* Deserialize the fields of this object from in.
*
* For efficiency, implementations should attempt to re-use storage in the
* existing object where possible.
*/
void readFields(DataInput in) throws IOException;
}
Hadoop自身提供了多种具体的Writable类,包含了常见的Java基本类型(boolean、byte、short、int、float、long和double等)和集合类型(BytesWritable、ArrayWritable和MapWritable等)。这些类型都位于org.apache.hadoop.io包中。

定制Writable类
虽然Hadoop内建了多种Writable类提供用户选择,Hadoop对Java基本类型的包装Writable类实现的RawComparable接口,使得这些对象不需要反序列化过程,便可以在字节流层面进行排序,从而大大缩短了比较的时间开销,但是当我们需要更加复杂的对象时,Hadoop的内建Writable类就不能满足我们的需求了(需要注意的是Hadoop提供的Writable集合类型并没有实现RawComparable接口,因此也不满足我们的需要),这时我们就需要定制自己的Writable类,特别将其作为键(key)的时候更应该如此,以求达到更高效的存储和快速的比较。
下面的实例展示了如何定制一个Writable类,一个定制的Writable类首先必须实现Writable或者WritableComparable接口,然后为定制的Writable类编写write(DataOutput out)和readFields(DataInput in)方法,来控制定制的Writable类如何转化为字节流(write方法)和如何从字节流转回为Writable对象。
package com.javaedge.hadoop.project;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.VLongWritable;
import org.apache.hadoop.io.Writable;
/**
* This MyWritable class demonstrates how to write a custom Writable class
*
* @author sss
* @date 2019-04-07
*/
public class MyWritable implements Writable {
private VLongWritable field1;
private VLongWritable field2;
public MyWritable() {
this.set(new VLongWritable(), new VLongWritable());
}
public MyWritable(VLongWritable fld1, VLongWritable fld2) {
this.set(fld1, fld2);
}
public void set(VLongWritable fld1, VLongWritable fld2) {
//make sure the smaller field is always put as field1
if (fld1.get() <= fld2.get()) {
this.field1 = fld1;
this.field2 = fld2;
} else {
this.field1 = fld2;
this.field2 = fld1;
}
}
/**
* How to write and read MyWritable fields from DataOutput and DataInput stream
* @param out
* @throws IOException
*/
@Override
public void write(DataOutput out) throws IOException {
field1.write(out);
field2.write(out);
}
@Override
public void readFields(DataInput in) throws IOException {
field1.readFields(in);
field2.readFields(in);
}
/**
* Returns true if o is a MyWritable with the same values.
*/
@Override
public boolean equals(Object o) {
if (!(o instanceof MyWritable)) {
return false;
}
MyWritable other = (MyWritable) o;
return field1.equals(other.field1) && field2.equals(other.field2);
}
@Override
public int hashCode() {
return field1.hashCode() * 163 + field2.hashCode();
}
@Override
public String toString() {
return field1.toString() + "\t" + field2.toString();
}
}
此外,K类型必须实现WritableComparable接口以便于按框架进行排序.
/**
* A {@link Writable} which is also {@link Comparable}.
*
* WritableComparables can be compared to each other, typically
* via Comparators. Any type which is to be used as a
* key in the Hadoop Map-Reduce framework should implement this
* interface.
*
* Note that hashCode() is frequently used in Hadoop to partition
* keys. It's important that your implementation of hashCode() returns the same
* result across different instances of the JVM. Note also that the default
* hashCode() implementation in Object does not
* satisfy this property.
*
* Example:
*
* public class MyWritableComparable implements WritableComparable {
* // Some data
* private int counter;
* private long timestamp;
*
* public void write(DataOutput out) throws IOException {
* out.writeInt(counter);
* out.writeLong(timestamp);
* }
*
* public void readFields(DataInput in) throws IOException {
* counter = in.readInt();
* timestamp = in.readLong();
* }
*
* public int compareTo(MyWritableComparable o) {
* int thisValue = this.value;
* int thatValue = o.value;
* return (thisValue < thatValue ? -1 : (thisValue==thatValue ? 0 : 1));
* }
*
* public int hashCode() {
* final int prime = 31;
* int result = 1;
* result = prime * result + counter;
* result = prime * result + (int) (timestamp ^ (timestamp >>> 32));
* return result
* }
* }
*
*/
@InterfaceAudience.Public
@InterfaceStability.Stable
public interface WritableComparable extends Writable, Comparable {
}
MapReduce作业的输入和输出类型:
其实简单来说这也是一个输入输出的流程,要注意的是在MapReduce框架中输入的数据集会被序列化成键/值对,map阶段完成后会对这些键值对进行排序,最后到reduce阶段中进行合并输出,输出的也是键/值对

-
示意图
InputFormat:将我们输入数据进行分片(split)
/**
* Split-up the input file(s) into logical {@link InputSplit}s, each of
* which is then assigned to an individual {@link Mapper}.
*
*
* Provide the {@link RecordReader} implementation to be used to glean
* input records from the logical InputSplit for processing by
* the {@link Mapper}.
*
*
*
* The default behavior of file-based {@link InputFormat}s, typically
* sub-classes of {@link FileInputFormat}, is to split the
* input into logical {@link InputSplit}s based on the total size, in
* bytes, of the input files. However, the {@link FileSystem} blocksize of
* the input files is treated as an upper bound for input splits. A lower bound
* on the split size can be set via
*
* mapreduce.input.fileinputformat.split.minsize.
*
* Clearly, logical splits based on input-size is insufficient for many
* applications since record boundaries are to respected. In such cases, the
* application has to also implement a {@link RecordReader} on whom lies the
* responsibility to respect record-boundaries and present a record-oriented
* view of the logical InputSplit to the individual task.
*/
@InterfaceAudience.Public
@InterfaceStability.Stable
public abstract class InputFormat {
/**
* Logically split the set of input files for the job.
*
* Each {@link InputSplit} is then assigned to an individual {@link Mapper}
* for processing.
*
* Note: The split is a logical split of the inputs and the
* input files are not physically split into chunks. For e.g. a split could
* be <input-file-path, start, offset> tuple. The InputFormat
* also creates the {@link RecordReader} to read the {@link InputSplit}.
*
* @param context job configuration.
* @return an array of {@link InputSplit}s for the job.
*/
public abstract List getSplits(JobContext context);
/**
* Create a record reader for a given split. The framework will call
* {@link RecordReader#initialize(InputSplit, TaskAttemptContext)} before
* the split is used.
* @param split the split to be read
* @param context the information about the task
* @return a new record reader
*/
public abstract
RecordReader createRecordReader(InputSplit split,
TaskAttemptContext context
) throws IOException,
InterruptedException;
}
常用以下实例

Split
将数据块交MapReduce作业来处理,数据块是MapReduce中最小的计算单元
- 在HDFS中,数据块是最小的存储单元,默认为128M
- 默认情况下,HDFS与MapReduce是一一对应的,当然我们也可以手动所设置它们之间的关系(但是不建议这么做)
OutputFormat
输出最终的处理结果
/**
* OutputFormat describes the output-specification for a
* Map-Reduce job.
*
* The Map-Reduce framework relies on the OutputFormat of the
* job to:
*
* -
* Validate the output-specification of the job. For e.g. check that the
* output directory doesn't already exist.
*
-
* Provide the {@link RecordWriter} implementation to be used to write out
* the output files of the job. Output files are stored in a
* {@link FileSystem}.
*/
@InterfaceAudience.Public
@InterfaceStability.Stable
public abstract class OutputFormat
{
/**
* Get the {@link RecordWriter} for the given task.
*
* @param context the information about the current task.
* @return a {@link RecordWriter} to write the output for the job.
* @throws IOException
*/
public abstract RecordWriter getRecordWriter(TaskAttemptContext context);
/**
* Check for validity of the output-specification for the job.
*
* This is to validate the output specification for the job when it is
* a job is submitted. Typically checks that it does not already exist,
* throwing an exception when it already exists, so that output is not
* overwritten.
*
* @param context information about the job
*/
public abstract void checkOutputSpecs(JobContext context);
/**
* Get the output committer for this output format. This is responsible
* for ensuring the output is committed correctly.
* @param context the task context
* @return an output committer
*/
public abstract
OutputCommitter getOutputCommitter(TaskAttemptContext context);
}
常用实例


我们可以再来看一张图,假设我们手动设置了block与split的对应关系,一个block对应两个split:
- OutputFormat
OutputFormt接口决定了在哪里以及怎样持久化作业结果。Hadoop为不同类型的格式提供了一系列的类和接口,实现自定义操作只要继承其中的某个类或接口即可。你可能已经熟悉了默认的OutputFormat,也就是TextOutputFormat,它是一种以行分隔,包含制表符界定的键值对的文本文件格式。尽管如此,对多数类型的数据而言,如再常见不过的数字,文本序列化会浪费一些空间,由此带来的结果是运行时间更长且资源消耗更多。为了避免文本文件的弊端,Hadoop提供了SequenceFileOutputformat,它将对象表示成二进制形式而不再是文本文件,并将结果进行压缩。
3 MapReduce核心概念
-
假设我们手动设置了block与split的对应关系,一个block对应两个split
上图中一个block对应两个split(默认是一对一),一个split则是对应一个Map Task。Map Task将数据分完组之后到Shuffle,Shuffle完成后就到Reduce上进行输出,而每一个Reduce Tasks会输出到一个文件上,上图中有三个Reduce Tasks,所以会输出到三个文件上。
3.1 Split

4 MapReduce 1.x 架构
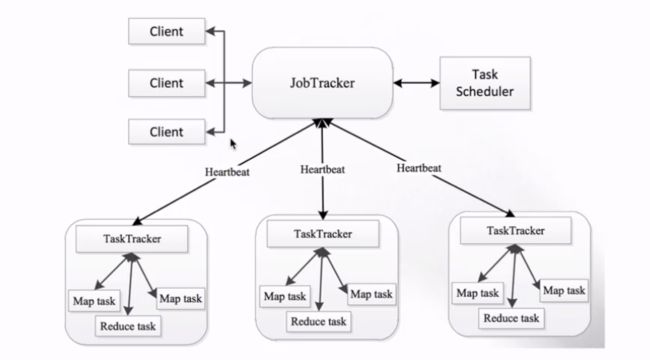
4.1 JobTracker(JT)
作业的管理者,它会将作业分解成一堆的任务,也就是Task,Task里包含MapTask和ReduceTask.
它会将分解后的任务分派给TaskTracker运行,它还需要完成作业的监控以及容错处理(task作业宕掉,会重启task)
如果在一定的时间内,JT没有收到某个TaskTracker的心跳信息的话,就会判断该TaskTracker宕机,然后就会将该TaskTracker上运行的任务指派到其他的TaskTracker
4.2 TaskTracker
任务的执行者,我们的Task(MapTask和ReduceTask)都是在TaskTracker上运行的,TaskTracker可以与JobTracker进行交互
例如执行、启动或停止作业以及发送心跳信息给JobTracker等。
4.3 MapTask
自己开发的Map任务会交由该Task完成,
- 它会解析每条记录的数据,交给自己的Map方法处理
- 处理完成会将Map的输出结果写到本地磁盘
不过有些作业可能只有map没有reduce,这时候一般会将结果输出到HDFS文件系统里。
4.4 ReduceTask
- 将MapTask输出的数据进行读取
- 按照数据的规则进行分组,然后传给我们自己编写的reduce方法处理
- 处理完成后默认将输出结果写到HDFS
5 MapReduce 2.x 架构
MapReduce2.x架构图如下,可以看到JobTracker和TaskTracker已经不复存在了,取而代之的是ResourceManager和NodeManager
不仅架构变了,功能也变了,2.x之后新引入了YARN,在YARN之上我们可以运行不同的计算框架,不再是1.x那样只能运行MapReduce了:

关于MapReduce2.x的架构之前已经在大数据入门(四) - 分布式资源调度——YARN框架
一文中说明过了,这里不再赘述
6 Java 实现 wordCount
-
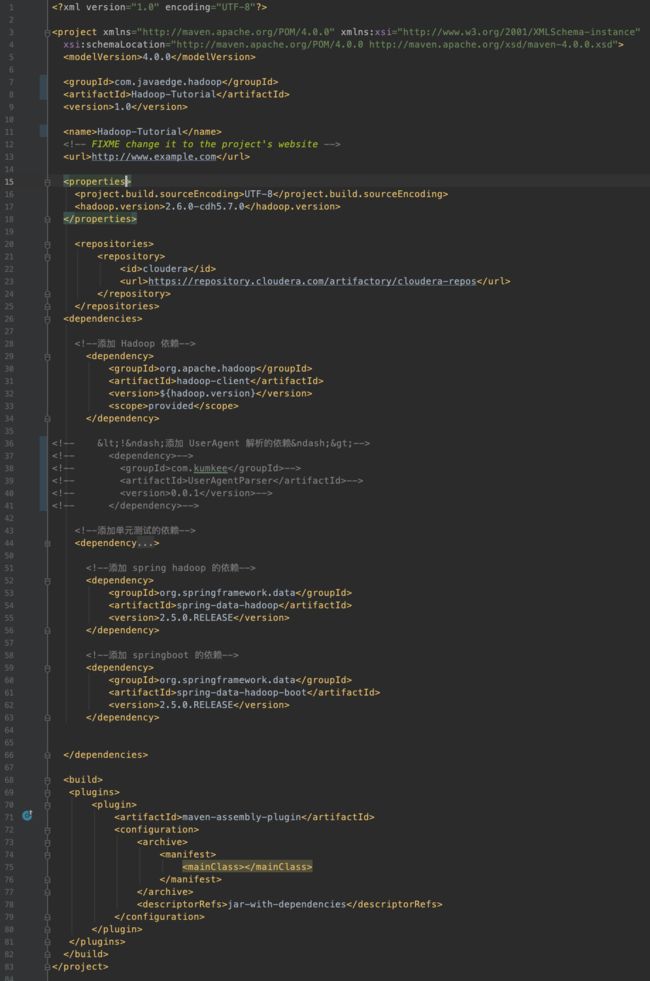
1.创建一个Maven工程,配置依赖如下
-
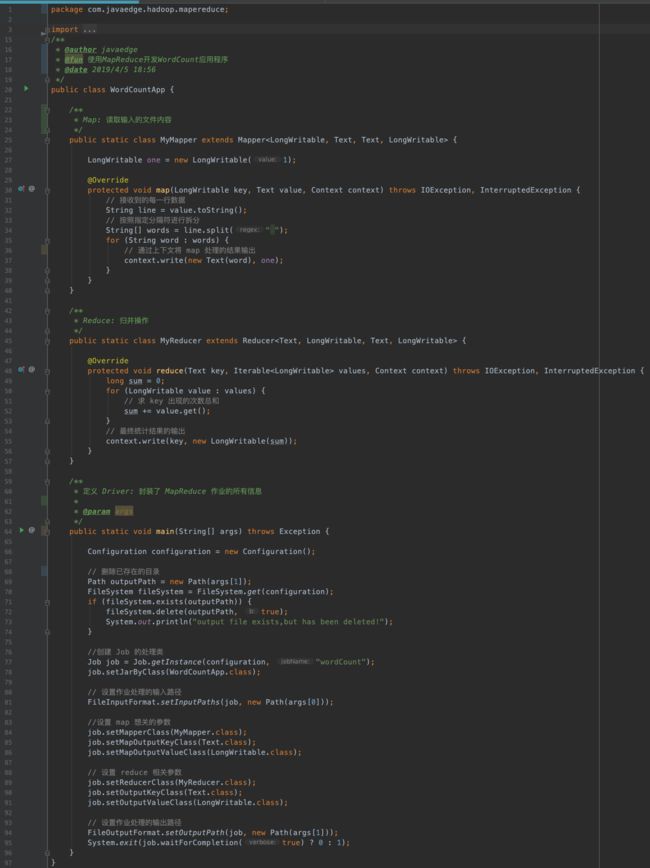
创建一个类,开始编写我们wordcount的实现代码:
-
3.编写完成之后,在IDEA里通过Maven进行编译打包


-
4.把打包好的jar包上传到服务器上:

-
上传到Hadoop服务器


全路径没有问题
hadoop fs -ls hdfs://localhost:9000


7 重构
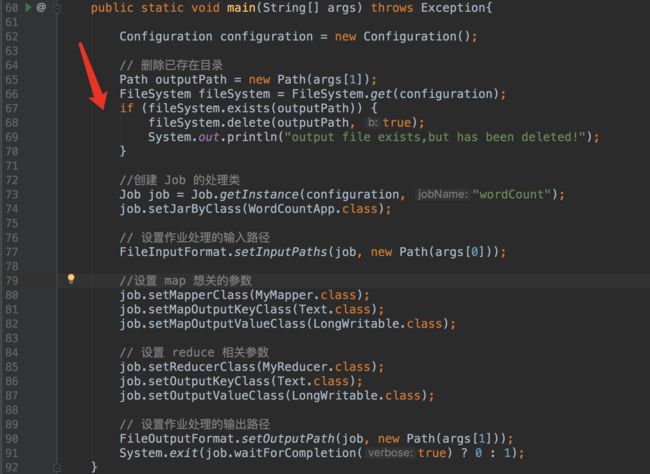
8 Combiner编程
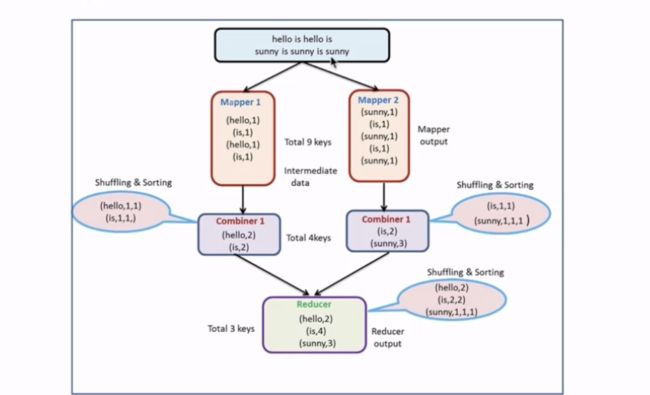
9 Partitoner
