1. TCP心跳检查、断开等待时间、TCP空闲后慢启动
默认Linux的TCP的心跳机制,2小时发送1个心跳包,并且常常默认关闭了心跳检查,某些网络场景下,可能会出现tcp链接一方断开,而另一方仍然以为连接正常,另一方的连接将无法正常释放,随着请求增多可能导致无法接受新的连接(例如:Docker或者K8s的IPVS超时问题)。
TCP的3次握手4次挥手机制,当客户端一方主动关闭连接,服务端连接将进入TIME_WAIT状态,如果大量客户端恶意进行这种操作,将导致服务端大量连接进入TIME_WAIT状态,我们将超时等待时间调小以便快速回收这些连接。
内核协议栈参数 net.ipv4.tcp_slow_start_after_idle 默认是开启的,这个参数的用途,是为了规避 CWND 无休止增长,因此在连接不断开,但一段时间不传输数据的话,就将 CWND 收敛到 initcwnd,kernel-2.6.32 是 10,kernel-2.6.18 是 2。因此在 HTTP Connection: keep-alive 的环境下,若连续两个 GET 请求之间存在一定时间间隔,则此时服务器端会降低 CWND 到初始值,当 Client 再次发起 GET 后,服务器会重新进入慢启动流程。
这种友善的保护机制,但是对于目前的网络坏境没必要这么谨慎和彬彬有礼,建议将此功能关闭,以提高长连接环境下的用户体验感。
vi /etc/sysctl.conf
# 开启SYN Cookies。当出现SYN等待队列溢出时,启用cookies来处理,可防范少量SYN攻击,默认为0,表示关闭
net.ipv4.tcp_syncookies = 1
# 开启重用。允许将TIME-WAIT sockets重新用于新的TCP连接,默认为0,表示关闭
net.ipv4.tcp_tw_reuse = 1
# 开启TCP连接中TIME-WAIT sockets的快速回收,默认为0,表示关闭
net.ipv4.tcp_tw_recycle = 1
# 修改系統默认的 TIMEOUT 时间
net.ipv4.tcp_fin_timeout = 30
# 超过这个时间秒数没有数据传输,开始发送探测包。
net.ipv4.tcp_keepalive_time = 60
# 探测间隔秒数,多久探测一次
net.ipv4.tcp_keepalive_intvl = 20
# 探测次数,如果超过该次数后仍无法发出探测包或者收到响应包,则表示连接已不可用
net.ipv4.tcp_keepalive_probes = 3
# 关闭慢启动
net.ipv4.tcp_slow_start_after_idle=0
重启系统后生效,可以通过sysctl -a|grep tcp_keepalive命令查看配置是否生效。
2. 任意用户最大进程数、单个进程的最大文件描述符
Linux对于每个用户,系统限制其最大进程(线程)数。为提高性能,可以根据设备资源情况,设置各linux 用户的最大进程数。
对于需要做许多 socket 连接并使它们处于打开状态的Java 应用程序而言,最好修改每个进程可打开的文件数,缺省值是 1024。(linux中,socket也使用了文件描述符,不论是操作磁盘文件还是socket通讯,我们都以流的的形式读写。)
vi /etc/security/limits.conf
* - noproc 65535
* - nofile 65535
在ubuntu上默认忽略了limits.conf的配置,需要手动开启配置。
vi /etc/pam.d/su
# 取消下面的注释以启动limit配置
# session required pam_limits.so
3. 关闭虚拟内存、交换文件
大多数操作系统尝试为文件系统缓存使用尽可能多的内存,并急切换出未使用的应用程序内存。这可能导致JVM堆的一部分内存甚至其可执行页面内存换出到磁盘上。
交换对性能,节点稳定性非常不利,应不惜一切代价避免交换。它可能导致垃圾收集持续数分钟而不是毫秒,并且可能导致节点响应缓慢甚至断开与群集的连接。在弹性分布式系统中,让操作系统杀死该节点更为有效。
推荐如下两种方式:
完全禁用:
vi /etc/fstab
注释掉所有包含swap的行减少交换:
vi /etc/sysctl.conf
# vm.swappiness设置为1,这减少了内核的交换趋势,并且在正常情况下不应导致交换,同时仍允许整个系统在紧急情况下进行交换。
vm.swappiness = 1
4. 增加内存映射文件计数
linux提供了mmap()函数,mmap实现了用户空间和内核空间的数据直接交互而省去了空间不同数据不通的繁琐过程。
java中提供的java.nio.channels.FileChannel以及DirectByteBuffer等类库的实现,底层都使用mmap函数。
ElasticSearch中对于索引文件的存储,使用了
mmapfs。
vi /etc/sysctl.conf
# 调整为默认值的4倍
vm.max_map_count=262144
5. 使用 BBR 拥塞控制算法
传统 TCP 拥塞控制算法,基于 丢包反馈 的协议。
基于「丢包反馈」的协议是一种 被动式 的拥塞控制机制,其依据网络中的 丢包事件 来做网络拥塞判断。即便网络中的负载很高时,只要没有产生拥塞丢包,协议就不会主动降低自己的发送速度。
这种协议可以 最大程度的利用网络剩余带宽,提高吞吐量。 然而,由于基于丢包反馈协议在网络近饱和状态下所表现出来的侵略性,一方面大大提高了网络的带宽利用率;但另一方面,对于基于丢包反馈的拥塞控制协议来说,大大提高网络利用率同时意味着下一次拥塞丢包事件为期不远了,所以这些协议 在提高网络带宽利用率的同时也间接加大了网络的丢包率 ,造成整个网络的抖动性加剧。
丢包并不总是拥塞导致,丢包可能原因是多方面,比如:
- 全球最牛的防火墙 GWF 的随机丢包策略
- 网路中由于多路径衰落(multi-path fading)所造成的信号衰减(signal degradation)
- 通道阻塞造成的丢包(packet drop),再者损坏的封包(corrupted packets)被拒绝通过
- 有缺陷的网路硬件、网路驱动软件发生故障
- 信号的信噪比(SNR)的影响
我们自然不喜欢 GWF 这种人为的随机丢包策略,当路过 GWF 时,数据被丢包,我们在此时应该 立刻重新发包,增大发送的频率,而不希望降低速度,也就是不希望传统的 TCP 拥塞算法去控制。
由此,就出现了基于不丢包的拥塞控制算法 CDG , 以 延迟 作为判断依据,延迟增大说明拥塞, 数据开始在路由器的缓冲中积累. 降低发送 窗口 。然而 CDG 算法与基于丢包的算法不兼容, 只有全球的设备都换上 CDG,但这是不可能的,目前市面上的设备不可能一下子都切换到 CDG,因此 Google 就不开心了,Google 的科学家们开发了一种过渡算法来解决这个问题,这个算法的名字就是 BBR(Bottleneck Bandwidth and RTT) ,它是一种全新的 拥塞控制算法 ,BBR 同 CDG 一致的思想是不以丢包作为拥塞控制信号,但是和 CDG 不同的是,BBR 能和 cubic 和 reno 共存。
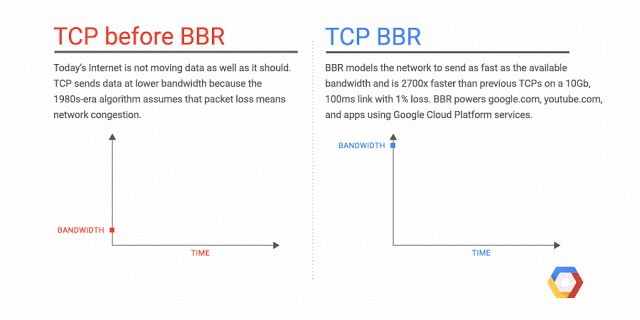
BBR 由 Google 开发,供 Linux 内核的 TCP 协议栈使用,有了 BBR 算法,Linux 服务器可以显著提高吞吐量并减少连接延迟,简单来说 BBR 能加速网络传输速度。此外,部署 BBR 也很容易,因为该算法只需要发送方,而不需要网络或接收方的支持。
BBR Centos7部署方案请参考:https://www.codercto.com/a/25431.html