一、主题式网络爬虫设计方案(15分)
1.主题式网络爬虫名称
关于豆瓣电影《星球大战9》的影评爬虫
2.主题式网络爬虫爬取的内容与数据特征分析
2.1爬取的内容
评论用户,评分等级,评论时间,评论内容
2.2数据特征分析
分析关于电影的用户情感及评分热度
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
实现思路:
1、查看网页源码,分析过程
2、模拟过程,使用requests请求,并伪造headers
3、对请求的数据进行提取处理,并写入到excel中
4、读取excel,然后使用pandas库处理,并做最终可视化展示
技术难点:
1、访问太快会被禁止访问,所以设置延迟
2、只能访问前几页,后面的需要登录才可以请求到数据,需要先自己登录,然后复制cookie过去访问
二、主题页面的结构特征分析(15分)
1、主题页面的结构特征
总共评论4405条,返回翻页发现,每页最大是20条,故需算出总页数,然后循环请求,但是请求到25页时,发现页面就空了,故最大请求条数应该是500条左右

https://movie.douban.com/subject/22265687/comments?start=20&limit=20&sort=new_score&status=P
而通过请求连接发现,翻页是通过start参数来控制,第一页就是0*20,第二页是1*20,以此类推
2、HTML页面解析
1. 发现评论信息是放在下id为comments下

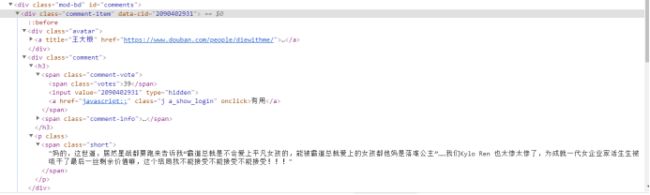
3、 节点(标签)查找方法与遍历发法(必要时画出节点数结构)
通过xpath查找id为comments的节点,然后获取下面的所有class为comment-item的节点,即评论信息,然后在获取
三、网络爬虫程序设计(60分)
爬虫程序主体要包括以下各部分,要附源代码及较详细注释,并在每部分程序后面提供输出结果的截图。
1、数据爬取与采集
我们先人工打开浏览器登录一下,然后通过f12查看登录后的cookie,然后写在代码中

1 headers = { 2 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3', 3 'Accept-Language': 'zh,en-US;q=0.9,en;q=0.8,zh-TW;q=0.7,zh-CN;q=0.6', 4 'Cookie': cookie, 5 'Host': 'movie.douban.com', 6 'Upgrade-Insecure-Requests': '1', 7 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36' 8 }
然后我们对页数进行循环遍历生成
1 for page in (0, 25): 2 print('当前{}页'.format(page + 1)) 3 url = 'https://movie.douban.com/subject/22265687/comments?start={}' \ 4 '&limit=20&sort=new_score&status=P'.format(page * 20)
并对每页下的数据进行请求解析
1 def parse_info(html): 2 # 获取评论内容节点 3 comments = html.xpath('div[@id="comments"]') 4 5 if len(comments) > 0: 6 page_info = [] 7 comment_items = comments[0].xpath('./div[@cass="comment-item"]/div[@class="comment"]') 8 # 获取每一条评论信息 9 for item in comment_items: 10 11 info = item.xpath('./h3/span[@class="comment-info"]') 12 if len(info) < 0: 13 continue 14 # 评论用户 15 user_name = info[0].xpath('./a[1]/text()')[0].strip() 16 # 评分, 去除信息不全的 17 try: 18 star = item.xpath('./span[2]/@class')[0].strip() 19 star = re.search('star(\d+) ', star, re.S).group(1) 20 except: 21 continue 22 # 评论时间 23 up_time = info.xpath('./span')[-1].xpath('./@title')[0].strip() 24 # 评论内容 25 content = item.xpath('string(./p)')[0].strip() 26 page_info.append([user_name, star, up_time, content]) 27 28 return page_info 29 else: 30 return None 31 # 请求数据,判断是否成功 32 while True: 33 response = requests.get(url=url, headers=headers) 34 # 成功返回状态码为200 35 if response.status_code == 200: 36 html = etree.HTML(response.text) 37 break 38 else: 39 print(response.status_code) 40 time.sleep(2) 41 page_info = parse_info(html)
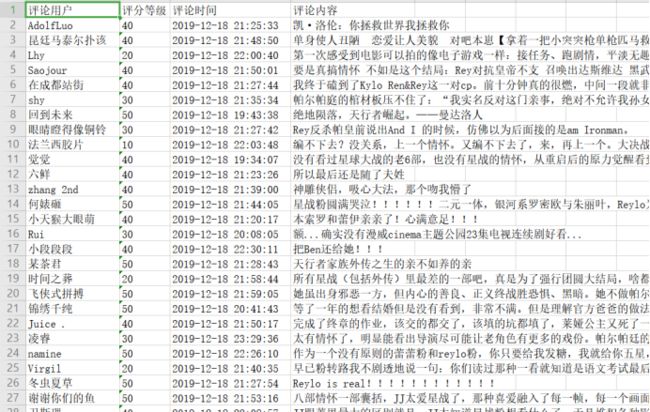
运行截图

最终抓取结果
2、对数据进行清洗和处理
对评分处理,没有的去掉,然后抓取的是字符串,并且需要除10
1 try: 2 star = info[0].xpath('./span[2]/@class')[0].strip() 3 star = re.search('star(\d+) ', star, re.S).group(1) 4 except Exception as e: 5 continue 6 idx = int(star) // 10
对情感值进行统计,并导出excel表
1 # 情感值列表 2 sentiments_list = [] 3 # 消极评论数量 4 low = 0 5 # 正常评论数量 6 center = 0 7 # 积极评论数量 8 high = 0 9 for word in words: 10 snlp = SnowNLP(word) 11 value = snlp.sentiments 12 if value < 0.4: 13 low += 1 14 elif value > 0.6: 15 high += 1 16 else: 17 center += 1 18 sentiments_list.append([word, value]) 19 # 将结果数组转为DataFrame 20 df = pd.DataFrame(sentiments_list, columns=['word', 'sentiments']) 21 # 情感值导出excel 22 df.to_excel('情感值表.xls', encoding='utf-8', index=False, header=['评论', '情感值'])

3、文本分析
对评论内容进行分词,并词频统计
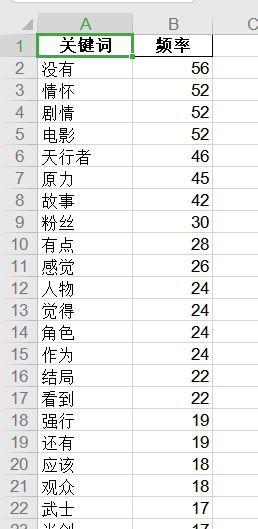
1 # 保存全局分词,用于词频统计 2 all_words = {} 3 for content in words: 4 # TextRank 关键词抽取,只获取固定词性 5 # 仅提取地名、名词、动名词、动词 6 words = jieba.analyse.textrank(content, topK=50, withWeight=False, allowPOS=('ns', 'n', 'vn', 'v')) 7 for word in words: 8 # 记录全局分词 9 if word not in all_words: 10 all_words[word] = 1 11 else: 12 all_words[word] += 1 13 # 生成词云图 14 gen_word_cloud(all_words) 15 # 排序,降序 16 top500 = sorted(all_words.items(), key=lambda x: x[1], reverse=True) 17 # 将结果数组转为df序列 18 df_words = pd.DataFrame(top500) 19 # 词频表导出excel 20 df_words.to_excel('词频统计.xls', encoding='utf-8', index=False, header=['关键词', '频率'])
词云图展示

1 def gen_word_cloud(all_words): 2 # 词云分析 3 wordcloud = WordCloud( 4 font_path='simhei.ttf', # 字体 5 background_color='white', # 背景色 6 max_font_size=120, # 频率最大单词字体大小 7 width=1000, # 宽度 8 height=600, # 高度 9 ).fit_words(all_words) 10 # 词云图片保存在本地 11 wordcloud.to_file("词云图.jpg")
4、可视化处理
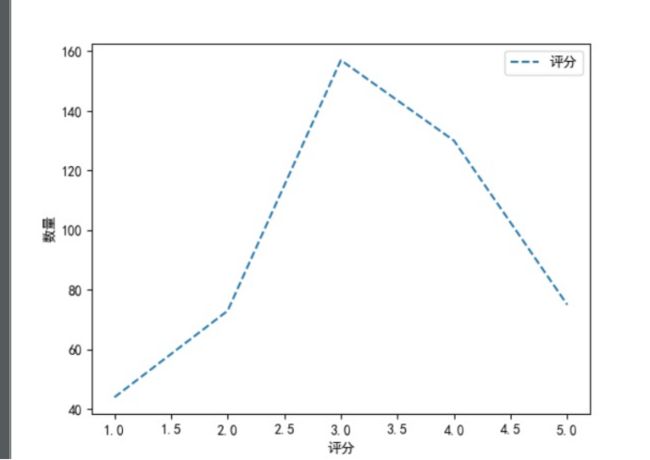
对评分进行折线图统计
1 # 评分统计 2 def seg_star(stars): 3 x = [1, 2, 3, 4, 5] 4 y_data = [0, 0, 0, 0, 0] 5 for star in stars: 6 idx = int(star) // 10 7 y_data[idx - 1] += 1 8 plt.plot(x, y_data, ls="--", label="评分") 9 plt.legend() 10 plt.xlabel('评分') 11 # y轴文字 12 plt.ylabel('数量') 13 # 保存为图片 14 plt.savefig('评分统计折线图.jpg')
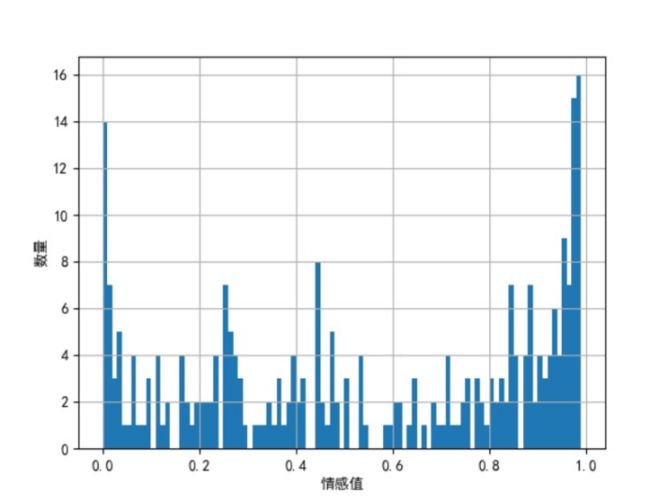
情感直方图
1 # 直方图绘制 2 df['sentiments'].hist(bins=np.arange(0, 1, 0.01)) 3 # x轴文字 4 plt.xlabel('情感值') 5 # y轴文字 6 plt.ylabel('数量') 7 # 保存为图片 8 plt.savefig('情感值直方图.jpg')
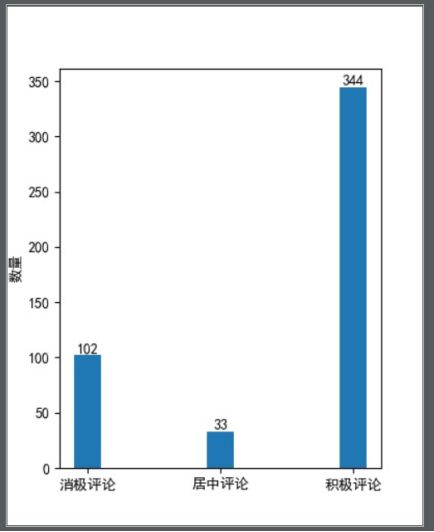
评分情感数量统计图
1 # 画柱状图 2 plt.figure(figsize=(4, 5)) # 指定图片大小为400*500 3 plt.bar(['消极评论', '居中评论', '积极评论'], [low, center, high], width=0.2) 4 # 标注数字 5 for x, y in zip(['消极评论', '居中评论', '积极评论'], [low, center, high]): 6 plt.text(x, y, '%d' % y, ha='center', va='bottom') 7 # y轴文字 8 plt.ylabel('数量') 9 # 保存为图片 10 plt.savefig('情感统计条形图.jpg')
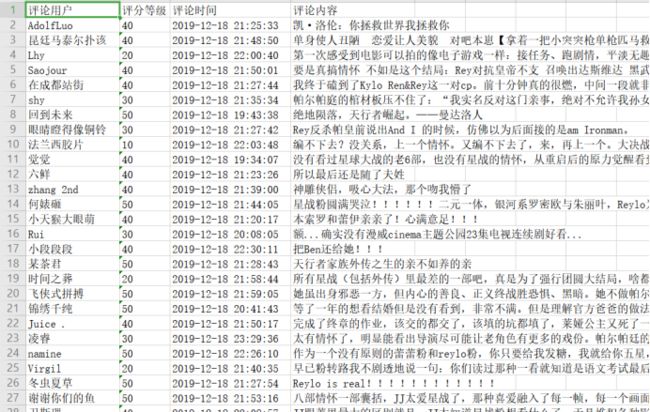
5、数据持久化
数据储存方式为excel
1 # 保存成excel 2 def save_data(datas): 3 # 创建excel 4 xls = openpyxl.Workbook() 5 sheet = xls.active 6 # 标题 7 title = ['评论用户', '评分等级', '评论时间', '评论内容'] 8 # 添加列头 9 sheet.append(title) 10 # 遍历结果集,添加到excel中 11 for line in datas: 12 sheet.append(line) 13 xls.save(file_name)
6、最终代码
1 import requests 2 from lxml import etree 3 import time 4 import openpyxl 5 import re 6 import jieba 7 import jieba.analyse 8 import pandas as pd 9 from wordcloud import WordCloud 10 from snownlp import SnowNLP 11 import matplotlib.pyplot as plt 12 import matplotlib 13 import numpy as np 14 15 16 def parse_info(html): 17 # 获取评论内容节点 18 comments = html.xpath('//div[@id="comments"]') 19 if len(comments) > 0: 20 page_info = [] 21 comment_items = comments[0].xpath('./div[@class="comment-item"]/div[@class="comment"]') 22 # 获取每一条评论信息 23 for item in comment_items: 24 info = item.xpath('./h3/span[@class="comment-info"]') 25 if len(info) < 0: 26 continue 27 # 评论用户 28 user_name = info[0].xpath('./a[1]/text()')[0].strip() 29 # 评分, 去除信息不全的 30 try: 31 star = info[0].xpath('./span[2]/@class')[0].strip() 32 star = re.search('star(\d+) ', star, re.S).group(1) 33 except Exception as e: 34 continue 35 # 评论时间 36 up_time = info[0].xpath('./span')[-1].xpath('./@title')[0].strip() 37 # 评论内容 38 content = item.xpath('string(./p)').strip() 39 page_info.append([user_name, star, up_time, content]) 40 return page_info 41 else: 42 return None 43 44 45 def parse_douban(): 46 headers = { 47 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3', 48 'Accept-Language': 'zh,en-US;q=0.9,en;q=0.8,zh-TW;q=0.7,zh-CN;q=0.6', 49 'Cookie': cookie, 50 'Host': 'movie.douban.com', 51 'Upgrade-Insecure-Requests': '1', 52 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36' 53 } 54 55 # 结果集 56 datas = [] 57 for page in range(0, 25): 58 print('当前{}页'.format(page + 1)) 59 url = 'https://movie.douban.com/subject/22265687/comments?start={}' \ 60 '&limit=20&sort=new_score&status=P'.format(page * 20) 61 # 请求数据,判断是否成功 62 while True: 63 response = requests.get(url=url, headers=headers) 64 # 成功返回状态码为200 65 if response.status_code == 200: 66 html = etree.HTML(response.text) 67 print('访问成功') 68 break 69 else: 70 print(response.status_code) 71 time.sleep(2) 72 page_info = parse_info(html) 73 if page_info is not None: 74 datas.extend(page_info) 75 # 每请求一页就延时一下 76 time.sleep(0.5) 77 78 return datas 79 80 81 # 保存成excel 82 def save_data(datas): 83 # 创建excel 84 xls = openpyxl.Workbook() 85 sheet = xls.active 86 # 标题 87 title = ['评论用户', '评分等级', '评论时间', '评论内容'] 88 # 添加列头 89 sheet.append(title) 90 # 遍历结果集,添加到excel中 91 for line in datas: 92 sheet.append(line) 93 xls.save(file_name) 94 95 96 def gen_word_cloud(all_words): 97 # 词云分析 98 wordcloud = WordCloud( 99 font_path='simhei.ttf', # 字体 100 background_color='white', # 背景色 101 max_font_size=120, # 频率最大单词字体大小 102 width=1000, # 宽度 103 height=600, # 高度 104 ).fit_words(all_words) 105 # 词云图片保存在本地 106 wordcloud.to_file("词云图.jpg") 107 108 109 # 情感值分析 110 def snow_nlp(words): 111 # 情感值列表 112 sentiments_list = [] 113 # 消极评论数量 114 low = 0 115 # 正常评论数量 116 center = 0 117 # 积极评论数量 118 high = 0 119 for word in words: 120 snlp = SnowNLP(word) 121 value = snlp.sentiments 122 if value < 0.4: 123 low += 1 124 elif value > 0.6: 125 high += 1 126 else: 127 center += 1 128 sentiments_list.append([word, value]) 129 # 将结果数组转为DataFrame 130 df = pd.DataFrame(sentiments_list, columns=['word', 'sentiments']) 131 # 情感值导出excel 132 df.to_excel('情感值表.xls', encoding='utf-8', index=False, header=['评论', '情感值']) 133 # 直方图绘制 134 df['sentiments'].hist(bins=np.arange(0, 1, 0.01)) 135 # x轴文字 136 plt.xlabel('情感值') 137 # y轴文字 138 plt.ylabel('数量') 139 # 保存为图片 140 plt.savefig('情感值直方图.jpg') 141 142 # 画柱状图 143 plt.figure(figsize=(4, 5)) # 指定图片大小为400*500 144 plt.bar(['消极评论', '居中评论', '积极评论'], [low, center, high], width=0.2) 145 # 标注数字 146 for x, y in zip(['消极评论', '居中评论', '积极评论'], [low, center, high]): 147 plt.text(x, y, '%d' % y, ha='center', va='bottom') 148 # y轴文字 149 plt.ylabel('数量') 150 # 保存为图片 151 plt.savefig('情感统计条形图.jpg') 152 153 154 # 评分统计 155 def seg_star(stars): 156 x = [1, 2, 3, 4, 5] 157 y_data = [0, 0, 0, 0, 0] 158 for star in stars: 159 idx = int(star) // 10 160 y_data[idx - 1] += 1 161 plt.figure() 162 plt.plot(x, y_data, ls="--", label="评分") 163 plt.legend() 164 plt.xlabel('评分') 165 # y轴文字 166 plt.ylabel('数量') 167 # 保存为图片 168 plt.savefig('评分统计折线图.jpg') 169 170 171 # 分词并统计 172 def seg_depart(words): 173 # 保存全局分词,用于词频统计 174 all_words = {} 175 for content in words: 176 # TextRank 关键词抽取,只获取固定词性 177 # 仅提取地名、名词、动名词、动词 178 words = jieba.analyse.textrank(content, topK=50, withWeight=False, allowPOS=('ns', 'n', 'vn', 'v')) 179 for word in words: 180 # 记录全局分词 181 if word not in all_words: 182 all_words[word] = 1 183 else: 184 all_words[word] += 1 185 # 生成词云图 186 gen_word_cloud(all_words) 187 # 排序,降序 188 top500 = sorted(all_words.items(), key=lambda x: x[1], reverse=True) 189 # 将结果数组转为df序列 190 df_words = pd.DataFrame(top500) 191 # 词频表导出excel 192 df_words.to_excel('词频统计.xls', encoding='utf-8', index=False, header=['关键词', '频率']) 193 194 195 if __name__ == "__main__": 196 # 储存文件名 197 file_name = '星球9影评.xlsx' 198 cookie = 'bid=RA47mCn8jns; douban-fav-remind=1; __yadk_uid=KgOjFzNBFlx2BIqCAZv0sDnAcUUNFLcc; ll="108309"; trc_cookie_storage=taboola%2520global%253Auser-id%3D751098a0-eba6-4d58-9238-ffb6ce1c9886-tuct47a058c; __gads=ID=f1c44b7e3685ecb3:T=1571501126:S=ALNI_Maxii85e0vX-F9TCUt7gB8TGSw4cA; __utmc=30149280; __utmc=223695111; _vwo_uuid_v2=D397EEE8C1B4A53B7AE894D1130A06008|ab9eefd2bf71bcb86c5bf8f1e0acbb87; __utmz=30149280.1576584118.11.9.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; ap_v=0,6.0; _pk_ref.100001.4cf6=%5B%22%22%2C%22%22%2C1576738591%2C%22https%3A%2F%2Fwww.baidu.com%2Fs%3Fie%3Dutf-8%26f%3D8%26rsv_bp%3D1%26tn%3Dbaidu%26wd%3D%25E8%25B1%2586%25E7%2593%25A3%26oq%3D%2525E7%2525A5%2525A8%2525E6%252588%2525BF%2525E7%2525BD%252591%26rsv_pq%3Dffdf6fa10000d4b2%26rsv_t%3D379aFjV%252Bjy0GlPQGAbqS8HUe%252Fd%252FAYerEeU30lnTLeieUD%252Ba4XQxA3miOQM4%26rqlang%3Dcn%26rsv_enter%3D1%26rsv_dl%3Dtb%26rsv_sug3%3D7%26rsv_sug1%3D1%26rsv_sug7%3D100%26rsv_sug2%3D0%26inputT%3D899%26rsv_sug4%3D899%22%5D; _pk_ses.100001.4cf6=*; __utma=30149280.941855647.1569745576.1576584118.1576738591.12; __utmz=223695111.1576740585.10.9.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; __utmb=223695111.0.10.1576740585; __utma=223695111.13086392.1571304138.1576738591.1576740585.10; __utmb=30149280.1.10.1576738591; dbcl2="200835379:38bnY8zREqw"; ck=o-Px; _pk_id.100001.4cf6=7b594b040ee131b3.1571304137.8.1576742234.1576584193.; push_noty_num=0; push_doumail_num=0' 199 # 抓取数据 200 datas = parse_douban() 201 # 保存数据 202 save_data(datas) 203 204 # pandas 读取 205 df = pd.read_excel('星球9影评.xlsx') 206 207 # 设置中文字体和负号正常显示 208 matplotlib.rcParams['font.sans-serif'] = ['SimHei'] 209 matplotlib.rcParams['axes.unicode_minus'] = False 210 211 # 词频统计 212 seg_depart(df['评论内容'].values) 213 # 情感值分析 214 snow_nlp(df['评论内容'].values) 215 # 评分图 216 seg_star(df['评分等级'].values)
四、结论(10分)
1、经过对主题数据的分析与可视化,可以得到哪些结论?
通过评分统计,发现大部分观众持中评态度,好评还是比差评多的
通过情感值分析,大部分的观众还是持积极态度
词云图发现,讨论的热度还是没有偏离电影主题
2、对本次程序设计任务完成的情况做一个简单的小结
通过本次作业,学习了下python自带的情感值分析等库,发现结果貌似跟人的思维还是有点偏差,目前也只会这些了,以后多多加油。