上一篇完整介绍elk等的安装步骤,下面介绍下它们的配置
我们做日志采集的时候一般步骤如:
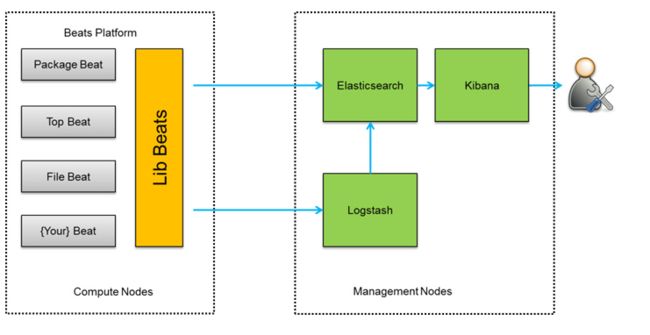
image
日志庞大时,filebeat和logstash或者logstash和es之间可以增加kafka或redis
首先来看下它们各自的日志中文解析:
我的版本5.6.16
filebeat.yml
###################### Filebeat Configuration Example #########################
# This file is an example configuration file highlighting only the most common
# options. The filebeat.full.yml file from the same directory contains all the
# supported options with more comments. You can use it as a reference.
#
# You can find the full configuration reference here:
# https://www.elastic.co/guide/en/beats/filebeat/index.html
#=========================== Filebeat prospectors =============================
filebeat.prospectors:
# Each - is a prospector. Most options can be set at the prospector level, so
# you can use different prospectors for various configurations.
# Below are the prospector specific configurations.
# 指定要监控的日志,可以指定具体得文件或者目录
- input_type: log #输入filebeat的类型,包括log(具体路径的日志)和stdin(键盘输入)两种。
# Paths that should be crawled and fetched. Glob based paths.
paths:
- /var/log/nginx/* #(这是默认的)(自行可以修改)
#- c:\programdata\elasticsearch\logs\*
type: "nginx"
fields:
logtype: nginx
# Exclude lines. A list of regular expressions to match. It drops the lines that are
# matching any regular expression from the list.
#exclude_lines: ["^DBG"] #排除正则匹配的日志
# Include lines. A list of regular expressions to match. It exports the lines that are
# matching any regular expression from the list.
#include_lines: ["^ERR", "^WARN"] #收集正则匹配的日志
# Exclude files. A list of regular expressions to match. Filebeat drops the files that
# are matching any regular expression from the list. By default, no files are dropped.
#exclude_files: [".gz$"] #排除正则匹配的文件
# Optional additional fields. These field can be freely picked
# to add additional information to the crawled log files for filtering
# 向输出的每一条日志添加额外的信息,比如“level:debug”,方便后续对日志进行分组统计。
# 默认情况下,会在输出信息的fields子目录下以指定的新增fields建立子目录,例如fields.level
# 这个得意思就是会在es中多添加一个字段,格式为 "filelds":{"level":"debug"}
fields:
level: debug
review: 1
### Multiline options
# Mutiline can be used for log messages spanning multiple lines. This is common
# for Java Stack Traces or C-Line Continuation
# The regexp Pattern that has to be matched. The example pattern matches all lines starting with [
# 适用于日志中每一条日志占据多行的情况,比如各种语言的报错信息调用栈
# 多行日志开始的那一行匹配的pattern
multiline.pattern: ^\[
# Defines if the pattern set under pattern should be negated or not. Default is false.
# 是否需要对pattern条件转置使用,不翻转设为true,反转设置为false。 【建议设置为true】
multiline.negate: true
# Match can be set to "after" or "before". It is used to define if lines should be append to a pattern
# that was (not) matched before or after or as long as a pattern is not matched based on negate.
# Note: After is the equivalent to previous and before is the equivalent to to next in Logstash
# 匹配pattern后,与前面(before)还是后面(after)的内容合并为一条日志
multiline.match: after
#================================ General =====================================
# The name of the shipper that publishes the network data. It can be used to group
# all the transactions sent by a single shipper in the web interface.
name: first
# The tags of the shipper are included in their own field with each
# transaction published.
tags: ["service-X", "web-tier"]
# Optional fields that you can specify to add additional information to the
# output.
fields:
env: staging
#================================ Outputs =====================================
# Configure what outputs to use when sending the data collected by the beat.
# Multiple outputs may be used.
#默认的输出到es,配置es的地址端口和ssl信息
#-------------------------- Elasticsearch output ------------------------------
#output.elasticsearch:
# Array of hosts to connect to.
#hosts: ["localhost:9200"]
# Optional protocol and basic auth credentials.
#protocol: "https"
#username: "elastic"
#password: "changeme"
#默认的输出到logstash,配置logstash的地址端口和ssl信息
#----------------------------- Logstash output --------------------------------
output.logstash:
# The Logstash hosts
hosts: ["localhost:5044"]
# Optional SSL. By default is off.
# List of root certificates for HTTPS server verifications
#ssl.certificate_authorities: ["/etc/pki/root/ca.pem"]
# Certificate for SSL client authentication
#ssl.certificate: "/etc/pki/client/cert.pem"
# Client Certificate Key
#ssl.key: "/etc/pki/client/cert.key"
#================================ Logging =====================================
# Sets log level. The default log level is info.
# Available log levels are: critical, error, warning, info, debug
logging.level: debug
# At debug level, you can selectively enable logging only for some components.
# To enable all selectors use ["*"]. Examples of other selectors are "beat",
# "publish", "service".
#logging.selectors: ["*"]
logstash 要自己编写配置文件可以覆盖yml
logstash-sample.conf
# stdin{
# add_field => {"key" => "value"} #向事件添加一个字段
# codec => "plain" #默认是line, 可通过这个参数设置编码方式
# tags => ["std"] #添加标记
# type => "std" #添加类型
# id => 1 #添加一个唯一的ID, 如果没有指定ID, 那么将生成一个ID
# enable_metric => true #是否开启记录日志, 默认true
# }
# file{
# path => ["/var/log/nginx/access.log", "/var/log/nginx/error.log"] #处理的文件的路径, 可以定义多个路径
# exclude => "*.zip" #匹配排除
# sincedb_path => "/data/" #sincedb数据文件的路径, 默认/plugins/inputs/file
# codec => "plain" #默认是plain,可通过这个参数设置编码方式
# tags => ["nginx"] #添加标记
# type => "nginx" #添加类型
# discover_interval => 2 #每隔多久去查一次文件, 默认15s
# stat_interval => 1 #每隔多久去查一次文件是否被修改过, 默认1s
# start_position => "beginning" #从什么位置开始读取文件数据, beginning和end,
#默认是结束位置end
# }
# tcp{
# port => 8888 #端口
# mode => "server" #操作模式, server:监听客户端连接, client:连接到服务器
# host => "0.0.0.0" #当mode为server, 指定监听地址, 当mode为client, 指定连接地址,
# 默认0.0.0.0
# ssl_enable => false #是否启用SSL, 默认false
# ssl_cert => "" #SSL证书路径
# ssl_extra_chain_certs => [] #将额外的X509证书添加到证书链中
# ssl_key => "" #SSL密钥路径
# ssl_key_passphrase => "nil" #SSL密钥密码, 默认nil
# ssl_verify => true #核实与CA的SSL连接的另一端的身份
# tcp_keep_alive => false #TCP是否保持alives
# }
# udp{
# buffer_size => 65536 #从网络读取的最大数据包大小, 默认65536
# host => 0.0.0.0 #监听地址
# port => 8888 #端口
# queue_size => 2000 #在内存中保存未处理的UDP数据包的数量, 默认2000
# workers => 2 #处理信息包的数量, 默认2
#}
input{
stdin { }
beats {
port => "5044"
codec => plain
{
charset => "GBK" #处理乱码
}
}
tcp{
host => "localhost"
mode => "server"
port => 1337
}
http{
host => "0.0.0.0"
port => 80
additional_codecs => {"application/json" => "json"}
codec => "plain"
threads => 4
ssl => false
type => "info"
}
}
filter {
if ([message]== "")
{
drop {}
}
}
output{
if [type] == "error" {
elasticsearch {
hosts => [ "127.0.0.1:9200"]
index => "logstash-error"
}}
if [type] == "info" {
elasticsearch {
hosts => [ "127.0.0.1:9200"]
index => "logstash-info"
}}
if [fields][logtype] == "nginx" {
##按照type类型创建多个索引
elasticsearch {
hosts => ["127.0.0.1:9200"]
index => "nginx_%{+YYYY.MM.dd}"
}
}
stdout{
codec => rubydebug
}
}
elasticsearch.yml
# ======================== Elasticsearch Configuration =========================
#
# NOTE: Elasticsearch comes with reasonable defaults for most settings.
# Before you set out to tweak and tune the configuration, make sure you
# understand what are you trying to accomplish and the consequences.
#
# The primary way of configuring a node is via this file. This template lists
# the most important settings you may want to configure for a production cluster.
#
# Please consult the documentation for further information on configuration options:
# https://www.elastic.co/guide/en/elasticsearch/reference/index.html
#
# ---------------------------------- Cluster -----------------------------------
#
# Use a descriptive name for your cluster:
#
cluster.name: my-application
#
# ------------------------------------ Node ------------------------------------
#
# Use a descriptive name for the node:
#
node.name: node-1
#
# Add custom attributes to the node:
#
#node.attr.rack: r1
#
# ----------------------------------- Paths ------------------------------------
#
# Path to directory where to store the data (separate multiple locations by comma):
#
#path.data: /path/to/data
#
# Path to log files:
#
#path.logs: /path/to/logs
#
# ----------------------------------- Memory -----------------------------------
#
# Lock the memory on startup:
#
#bootstrap.memory_lock: true
#
# Make sure that the heap size is set to about half the memory available
# on the system and that the owner of the process is allowed to use this
# limit.
#
# Elasticsearch performs poorly when the system is swapping the memory.
#
# ---------------------------------- Network -----------------------------------
#
# Set the bind address to a specific IP (IPv4 or IPv6):
#
network.host: 0.0.0.0
#
# Set a custom port for HTTP:
#
http.port: 9200
#
# For more information, consult the network module documentation.
#
# --------------------------------- Discovery ----------------------------------
#
# Pass an initial list of hosts to perform discovery when new node is started:
# The default list of hosts is ["127.0.0.1", "[::1]"]
#
#discovery.zen.ping.unicast.hosts: ["127.0.0.1"]
#
# Prevent the "split brain" by configuring the majority of nodes (total number of master-eligible nodes / 2 + 1):
#
#discovery.zen.minimum_master_nodes: 3
#
# For more information, consult the zen discovery module documentation.
#
# ---------------------------------- Gateway -----------------------------------
#
# Block initial recovery after a full cluster restart until N nodes are started:
#
#gateway.recover_after_nodes: 3
#
# For more information, consult the gateway module documentation.
#
# ---------------------------------- Various -----------------------------------
#
# Require explicit names when deleting indices:
#
#action.destructive_requires_name: true
kibana.yml
# Kibana is served by a back end server. This setting specifies the port to use.
server.port: 5600
# Specifies the address to which the Kibana server will bind. IP addresses and host names are both valid values.
# The default is 'localhost', which usually means remote machines will not be able to connect.
# To allow connections from remote users, set this parameter to a non-loopback address.
server.host: "127.0.0.1"
# Enables you to specify a path to mount Kibana at if you are running behind a proxy. This only affects
# the URLs generated by Kibana, your proxy is expected to remove the basePath value before forwarding requests
# to Kibana. This setting cannot end in a slash.
#server.basePath: ""
# The maximum payload size in bytes for incoming server requests.
#server.maxPayloadBytes: 1048576
# The Kibana server's name. This is used for display purposes.
#server.name: "your-hostname"
# The URL of the Elasticsearch instance to use for all your queries.
elasticsearch.url: "http://127.0.0.1:9200"
# When this setting's value is true Kibana uses the hostname specified in the server.host
# setting. When the value of this setting is false, Kibana uses the hostname of the host
# that connects to this Kibana instance.
#elasticsearch.preserveHost: true
# Kibana uses an index in Elasticsearch to store saved searches, visualizations and
# dashboards. Kibana creates a new index if the index doesn't already exist.
#kibana.index: ".kibana"
# The default application to load.
#kibana.defaultAppId: "discover"
# If your Elasticsearch is protected with basic authentication, these settings provide
# the username and password that the Kibana server uses to perform maintenance on the Kibana
# index at startup. Your Kibana users still need to authenticate with Elasticsearch, which
# is proxied through the Kibana server.
#elasticsearch.username: "user"
#elasticsearch.password: "pass"
# Enables SSL and paths to the PEM-format SSL certificate and SSL key files, respectively.
# These settings enable SSL for outgoing requests from the Kibana server to the browser.
#server.ssl.enabled: false
#server.ssl.certificate: /path/to/your/server.crt
#server.ssl.key: /path/to/your/server.key
# Optional settings that provide the paths to the PEM-format SSL certificate and key files.
# These files validate that your Elasticsearch backend uses the same key files.
#elasticsearch.ssl.certificate: /path/to/your/client.crt
#elasticsearch.ssl.key: /path/to/your/client.key
# Optional setting that enables you to specify a path to the PEM file for the certificate
# authority for your Elasticsearch instance.
#elasticsearch.ssl.certificateAuthorities: [ "/path/to/your/CA.pem" ]
# To disregard the validity of SSL certificates, change this setting's value to 'none'.
#elasticsearch.ssl.verificationMode: full
# Time in milliseconds to wait for Elasticsearch to respond to pings. Defaults to the value of
# the elasticsearch.requestTimeout setting.
#elasticsearch.pingTimeout: 1500
# Time in milliseconds to wait for responses from the back end or Elasticsearch. This value
# must be a positive integer.
#elasticsearch.requestTimeout: 30000
# List of Kibana client-side headers to send to Elasticsearch. To send *no* client-side
# headers, set this value to [] (an empty list).
#elasticsearch.requestHeadersWhitelist: [ authorization ]
# Header names and values that are sent to Elasticsearch. Any custom headers cannot be overwritten
# by client-side headers, regardless of the elasticsearch.requestHeadersWhitelist configuration.
#elasticsearch.customHeaders: {}
# Time in milliseconds for Elasticsearch to wait for responses from shards. Set to 0 to disable.
#elasticsearch.shardTimeout: 0
# Time in milliseconds to wait for Elasticsearch at Kibana startup before retrying.
#elasticsearch.startupTimeout: 5000
# Specifies the path where Kibana creates the process ID file.
#pid.file: /var/run/kibana.pid
# Enables you specify a file where Kibana stores log output.
#logging.dest: stdout
# Set the value of this setting to true to suppress all logging output.
#logging.silent: false
# Set the value of this setting to true to suppress all logging output other than error messages.
#logging.quiet: false
# Set the value of this setting to true to log all events, including system usage information
# and all requests.
#logging.verbose: false
# Set the interval in milliseconds to sample system and process performance
# metrics. Minimum is 100ms. Defaults to 5000.
#ops.interval: 5000
# The default locale. This locale can be used in certain circumstances to substitute any missing
# translations.
#i18n.defaultLocale: "en"
上面只是一些配置文件的梳理,实际上我们要启动这些 并不需要所有的配置
elasticsearch.yml
$vim /etc/elasticsearch/elasticsearch.yml
path.data: /data/elasticsearch #日志存储目录
path.logs: /data/elasticsearch/log #elasticsearch启动日志路径
network.host: elk1 #这里是主机IP,我写了hosts
node.name: "node-2" #节点名字,不同节点名字要改为不一样
http.port: 9200 #api接口url
node.master: true #主节点
node.data: true #是否存储数据
#手动发现节点,多个节点配置
#discovery.zen.ping.unicast.hosts: [elk1, elk2]
kibana.yml
vim /opt/kibana/config/kibana.yml
server.port: 5601
#server.host: "localhost"
server.host: "0.0.0.0"
elasticsearch.url: "http://elk1:9200"
logstash-sample.conf
input{
beats {
port => "5044"
codec => plain
{
charset => "GBK" #处理乱码
}
}
filter {
}
output{
if [type] == "error" {
elasticsearch {
hosts => [ "127.0.0.1:9200"]
index => "logstash-error"
}}
if [type] == "info" {
elasticsearch {
hosts => [ "127.0.0.1:9200"]
index => "logstash-info"
}}
stdout{
codec => rubydebug
}
}
filebeat自带了很多moudle,mysql,apache,nginx等,在filebeat.full.yml中。
filebeat.yml
filebeat.prospectors:
# 指定要监控的日志,可以指定具体得文件或者目录
- input_type: log #输入filebeat的类型,包括log(具体路径的日志)和stdin(键盘输入)两种。
paths:
- /var/log/* #(这是默认的)(自行可以修改)
type: "info"
fields:
logtype: info
multiline.pattern: ^\[
multiline.negate: true
multiline.match: after
output.logstash:
hosts: ["localhost:5044"]
欢迎关注公众号:麻雀唯伊 , 不定时更新资源文章,生活优惠,或许有你想看的

image