目录
- http并发
- 并发访问模型
- 响应流程
- 从IO的角度看待响应
- 从函数的角度看待响应
- 日志处理
我叫张贺,贪财好色。一名合格的LINUX运维工程师,专注于LINUX的学习和研究,曾负责某中型企业的网站运维工作,爱好佛学和跑步。
个人博客:传送阵
笔者微信:zhanghe15069028807,非诚勿扰。
http并发
内容概括
本文主要介绍了三种并发访问模型:单线程、多线程、利用的IO是如何工作的。
http的响应流程:IO角度、函数角度
应用进程处理日志的方式
并发访问模型
在讨论HTTP面对并发连接之前我们先讨论一下银行工作人员面对大量客户时的工作机制,其实银行的工作机制与HTTP的工作面对并发时的工作机制是类似的。
如果一个银行在刚开业只有一个柜台,假设接待一个客户需要5分钟的话,那么如果同时来10个客户,只能先接待接待一个,让另外的9个人先等着排列,如果队列很多,很多人连大厅都坐不下,保安就不让排队了。
银行的人员越来越多,然后开了10个柜台,同时来了100个用户,还有90个等待,为什么不能开100个柜台呢?你不考虑成本的吗!!又出现了队列很长,很多人连大厅都坐不下,保安就不让排队了。
开10个柜台就已经是极限了,那么怎样才能加快工作的效率呢?我们可以做一些优化,原本一个柜台只有一个工作人员,服务一个客户需要2分种,现在每个柜台多个工作人员,第一个工作人员只负责接待,第两个工作人员负责打印票据,第三人工作人员负责处理文档……,当第两个工作人员打印票据的时候,第一个工作人员又可以为第二个客户服务,从客户的角度因为隔着窗户,只能看清最外面的负责接待的工作人员,其实里面有很多工作人员工作,这话的话一个服务一个客户可能仅需要几秒的时间。

WEB服务器的IO结构
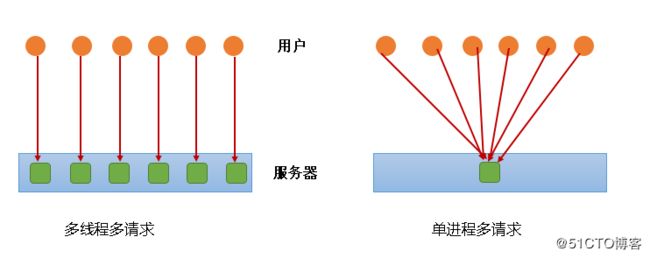
单线程结构:一次只能接收一个请求,余下的排队,也可以称做是单线程结构,因为在linux当中线程与进程的区别没什么差别,一般来讲linux一个进程里面也通常只有一个线程。
多线程多请求结构:每个用户都创建一个进程对应,但是创建的进程数是有限的
请注意是多请求结构而不是多用户结构,为什么?因为一个用户可以发起多个请求,有100个请求并不意味着有100个用户,多请求的是这样的,HTTP的主程序侦听到TCP80端口,一旦有有连接的话就把自己复制一份(生成一个子进程)到内存当中去处理连接的请求,而自己继续侦听TCP的80,当这个子进程处理完请求,构建好响应报文之后就会由其父进程将其销毁,也就是说必须有一个进程(父进程)做分配管理才行。
复用的IO结构:也叫做单进程多请求模型,一个进程可以响应多个请求,它是怎样做到的呢?向外看来是一个进程服务了多个请求,但是对内看来是这样的:服务于多个请求的进程是并不是单纯的一个进程,而是一个团队,这个进程里面有很多的“人”只是外人看起来是一个进程在响应多个请求。
既然有三种模型那么哪个占用的资源更少而且用户体验较好呢?
在讲明白这个问题之前,首先理解一点:在进程的角度看内存,整个内存都由自己占用。
CPU进程的切换,切换本身就会浪费时间
单进程的坏处有:崩溃,机制复杂,稳定性来说多线程多请求更好,资源节约来讲单进程多请求最好。
响应流程

上图中的虚线指的是内核空间与用户空间的分隔.
其实上图中的七步就基本的描述了客户端访问站点的过程。下面用文字解释一下
1) 建立连接,当然是客户端先发起请求,与服务器完成三次握手之后建立连接
2) 接收请求,当服务器接收了请求之后,内核根据套节字把客户端要请求的请求资源交给应用程序
3) 处理请求,应用程序不能调用硬盘当中的资源肯定是找内核调用
4) 访问资源,内核去硬盘调用资源
5) 构建响应,应用程序要构建响应报文
6) 发送响应,通过套节字发送给客户端
7) 记录事务的处理过程,这一步也要IO
从IO的角度看待响应
第一步:客户端与服务器建立连接时,服务器的通信子网(内核)首先判断是不是给自己的数据,然后取出此数据访问的套节字,然后把数据的内容给侦听到此套节字的进程。
第二步:客户端的请求无非也就是请求资源,而资源一般都放在磁盘上,而应用无权限访问磁盘,这时程序会发起系统调用,代码的执行由用户空间切换到了内核空间,然后内核去磁盘调用加载磁盘当中数据,那么问题来了?内核把数据调用到哪里去了?是直接把数据放在进程的内存空间了吗?
第三步:虽然内核有这个能力,但是没有那么做,内核通常把从磁盘调用的数据放在自己的内核空间的当中了,而这部分空间被我们称之为cache,然后再给进程多分配一些页框,最后把cache当中的数据复制一份到进程的页框当中,注意,进程没有权限访问内核空间的数据。
第四步:数据进入用户空间进程构建响应报文,提交给内核,内核再通过套字将响应发送给用户。

让我们总结一下:上文当中的数据流向是这样的:内核用户-----用户空间------内核空间--------用户空间------内核空间
通过上文我们可以知道被客户端请求的文件被调用了2次,,事实上所有的IO都是这样.
那么我们可不可以让内核调用完数据后不用交给内核直接给客户端响应呢?可能你会问,如果不交给应用层的应用的话怎样构建响应报文呢?事实上,内核是可以构建响应报文的,也就是说内核调用完资源之后直接给客户端回应不用经过用户空间构建响应报文,它是怎样做到的呢?在一个系统调用 sed-file可以帮助我们把构建响应报文,我们可以在httpd的配置文件当中,直接就调用它,这样的话,用户的访问的速度会加快很多,服务器本身的资源也会节省很多,就变成了下面这样:

从函数的角度看待响应

某个服务想要侦听到某个套接字上“坐诊”,必须要调用四个函数(如果是C语言):socket(),bind(),.listen(),accept(),首先,服务先调用socket()API用来申请一个套接字,当然只申请完一个套接字是远远不够的,申请了之后要把自己(服务绑定(bind())到申请的套接字上,仅仅绑定还是不够,还要调用listen()API侦听在此套接字上,当申请、绑定、侦听完成之后接下来就可以“接客”了,会调用一个accept()API等待接收别人的访问,会处于一直阻塞的状态等待客户端的连接。
做为客户端同样也是需要申请套接字的socket(),申请完成之后就是下一步主动连接(connetct)服务端,建立连接有四个元素,源IP端口,目标IP端口,这也就是为什么客户端也要申请套接字的原因了,建立连接当然是通过三次握手建立 ,三次握手完成之间意味着从客户端到服务器的虚链路建立完成,虚链路建立完成之后就会把此虚链路保存成一个套接字文件(当然服务器也会这么做了),一切皆文件嘛!当然这个文件当中主要也就是有四个元素:本地的IP端口,服务器端的IP端口。下一步是客户端要向服务器发出一个申请,怎样发的呢?因为客户端有了虚链路的套接字文件以此来标识与服务器之间的连接,客户端发起请求时可以直接调用write()函数直接把请求的信息写入到套接字文件当中,然后客户端会通过此套接字连接起来的虚链路把请求发给服务器那边的套接字文件(当建立完成三次握手,服务器和客户端各自维护一个套接字),服务器端的套接字接收到请求之后,服务器端就要从套接字文件当中读出(read())一些信息出来,这里面就是服务器端的请求信息,请求的资源无非也就是服务器端磁盘的资源,很有可能是html文件,然后就处理请求,怎样处理呢?处理就非常的简单了,http通过内核去存储器当中读取数据,读取完之后构建响应报文,把响应报文写入到服务器自己维护的套接字文件当中,这下论到客户端方接收信息了,客户端就会去套节字文件当中读取资源,发现此资源并不完整,里面包含很多的图片,客户端会再向服务器端请求,服务器端会再次响应,循环下去直到资源完成。
当资源传输完成之后,客户端会终止此连接并且会向套节字当中发起close()终止信号,当服务器收到之后同样还是先读取,读取一看是是终止信息,于是自己也处于终止状态。客户端是主动关闭的,而服务器是被动关闭的。
日志处理
日志也会产生IO,每处理一份事务HTTP都会产生IO,那么这个IO如果每次都要写入到磁盘当中的话,IO次数太过频繁,影响服务器的性能,还好我们可以自己规定多长时间IO一次,比如我们规定1分钟IO一次,1分钟中所有的日志先暂时放入到内存里面,到了规定的时候,一块打包放入磁盘里面.这样的话能够减少一部分的IO.
如果规定的时间过长,一旦断电就都丢失的数据比较多,但是IO次数减少了
如果规定的时间过短,一旦断电丢失的数据比较少,但是IO次数要多一些.至于多少时间,自己选.