背景:只专注于单个模型可能会忽略一些相关任务中可能提升目标任务的潜在信息,通过进行一定程度的共享不同任务之间的参数,可能会使原任务泛化更好。广义的讲,只要loss有多个就算MTL,一些别名(joint learning,learning to learn,learning with auxiliary task)
目标:通过权衡主任务与辅助的相关任务中的训练信息来提升模型的泛化性与表现。从机器学习的视角来看,MTL可以看作一种inductive transfer(先验知识),通过提供inductive bias(某种对模型的先验假设)来提升模型效果。比如,使用L1正则,我们对模型的假设模型偏向于sparse solution(参数要少)。在MTL中,这种先验是通过auxiliary task来提供,更灵活,告诉模型偏向一些其他任务,最终导致模型会泛化得更好。
MTL Methods for DNN
- hard parameter sharing (此方法已经有26岁了<1993>)
在所有任务中共享一些参数(一般底层),在特定任务层(顶层)使用自己独有参数。这种情况,共享参数得过拟合几率比较低(相对非共享参数),过拟合的几率是O(#tasks). [1]

- soft parameter sharing
每个任务有自己的参数,最后通过对不同任务的参数之间的差异加约束,表达相似性。比如可以使用L2, trace norm等。

优点及使用场景
- implicit data augmentation: 每个任务多少都有样本噪声,不同的任务可能噪声不同,最终多个任务学习会抵消一部分噪声(类似bagging的思想,不同任务噪声存在于各个方向,最终平均就会趋于零)
- 一些噪声很大的任务,或者训练样本不足,维度高,模型可能无法有效学习,甚至无法无法学习到相关特征
- 某些特征可能在主任务不好学习(比如只存在很高阶的相关性,或被其他因素抑制),但在辅助任务上好学习。可以通过辅助任务来学习这些特征,方法比如hints(预测重要特征)[2]
- 通过学习足够大的假设空间,在未来某些新任务中可以有较好的表现(解决冷启动),前提是这些任务都是同源的。
- 作为一种正则方式,约束模型。所谓的inductive bias。缓解过拟合,降低模型的Rademacher complexity(拟合噪声的能力,用于衡量模型的能力)
传统方法中的MTL (linear model, kernel methods, Bayesian algo),其主要关注两点:
- 通过norm regularization使模型在任务之间具有稀疏性
- 对多任务之间关系进行建模
1.1 Block-sparse regularization (mixed l1/lq norm)
目标:强制模型只考虑部分特征,前提为不同任务之间必须相关。
假设K个任务有相同的特征,和相同数量的模型参数。形成一个矩阵A(DxK),D为参数维度,K为任务数,目标为这些任务只使用一些特征,也就是A的某些行也0。(最简单的想法就是使其变为一个low rank的矩阵;或者使用L1正则,因为L1可以约束某些特征到0,如果我们想使某些行为0,则只要先对行聚合操作,再对聚合后的结果使用L1即可,具体可以参考文章 [3]。通常,使用lq norm 先对行(每个特征)进行约束,之后使用L1 norm再约束,就是mixer l1/lq norm。
发展:
- **group lasso [4] **: l1/l2 norm,通过trace norm 解决l1/l2 norm非凸; 之后有人对此提出了upper bound for using group lasso in MTL [5]
- 当多个任务公共特征不多时,l1/lq norm可能没有elment-wise norm效果好。有人提出了结合这两种方法,分解参数矩阵为A = S + B,对S使用lassso,对B使用l1/l_infinite。[6]
- distributed version of group-sparse reguarization [7]
2.1 regularization way for learning task relationship
当任务之间相关性较弱,使用上述方法可能导致negative transfer(也就是负向效果)。在此情景下,我们希望增加的先验知识是,某些任务之间是相关的,但是某些任务之间是相关性较差。可以通过引入任务clustering来约束模型。可以通过penalize 不同任务的parameter vectors 和他们的方差。限制不同模型趋向于不同的各自 cluster mean vector。

类似的,比如SVM中引入bayesian方法,事先指定一些cluster,目标在最大化margin的同时使不同任务趋向于各自的cluster中心;[8]
指定了cluster,可以通过聚类方法(类内,类间,自己的复杂度)对模型进行约束
有些场景下,任务可能不会出现在同一个cluster,但存在潜在的相似结构,比如group-lasso在树结构和图结构的任务。
2.2 other methods for learning task relationship
- KNN methods for task clustering. [9]
- semi-supervised learning for learning common structures of some related tasks. [10]
- 多任务BNN,通过先验控制多任务的相似,模型复杂度大,可以使用sparse approximation贪心选择样本 [11];高斯过程中通过不同任务之间使用相同的covariance matrix和相同的先验(进而也降低复杂度)[12]
- 对每个task-specific layers 使用高斯先验,可以使用一个cluster的混合分布(事先定好)来促使不同任务的相似 [13]
- 进而,通过一个dirichlet process采样分布,使模型任务之间的相似性和cluster的数目。相同cluster的任务使用同一个模型 [14]
- hierarchical Bayesian model,学习一个潜在的任务结构 [15]
- MTL extension of the regularized Perceptron,encodes task relatedness in a matrix. 之后可以通过不同正则对其限制(比如rank)[16]
- 不同tasks属于不同的独立cluster,每个cluster存在于一个低维空间,每个cluster的任务共用同一个模型。通过交替迭代学习不同cluster的分配权重和每个cluster的模型权重。假定任务之间的绝对独立可能不太好 [17]
- 假设两个不同cluster的两个任务之间存在重叠,存在一部分的latent basis tasks。令每个任务的模型参数是latent basis tasks的线性组合,对latent basis tasks限制为稀疏的。重叠部分控制共享程度 [18]
- 学习一小撮shared hypotheses,之后map each task to a single hypothesis [19]
DNN中的MTL
Deep Relation Network [20]
计算机视觉中,一般共享卷积层,之后是任务特定的DNN层。通过对任务层设定先验,使模型学习任务之间的关系。

Fully-Adaptive Feature Sharing [21]
从一个简单结构开始,贪心地动态地加宽模型,使相似的模型聚簇。贪心方法可能无法学到全局最优结构;每个分支一个任务无法学习任务之间的复杂关系。

Cross-stitch Networks [22]
soft parameter sharing,通过线性组合学习前一层的输出,允许模型决定不同任务之间的分享程度
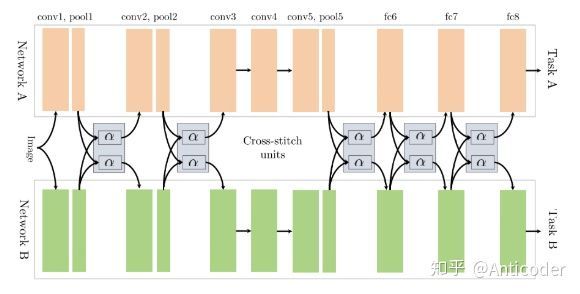
Low supervision [23]
寻找更好的多任务结构,复杂任务的底层应该被低级任务目标来监督(比如NLP前几层学习一个NER或POS辅助任务)
A Joint Many-task Model [24]
对多个NLP任务预先设定层级结构,之后joint learning

Weighting losses with uncertainty [25]
不考虑学习共享的结构,考虑每个任务的不确定性。通过优化loss(Gaussian likelihood with task-dependant uncertainty),调节不同tasks之间的相似性。

Tensor factorisation for MTL [26]
对每层参数进行分解,为shared和task-specific
Sluice Networks [27]
大杂烩(hard parameter sharing + cross stitch networks + block-sparse regularization + task hierarchy(NLP) ),使得模型自己学习哪些层,哪些子空间来共享,在哪层模型找到了inputs的最优表达。

当不同的任务相关性大,近似服从相同的分布,共享参数是有益的,如果相关性不大或者不相关的任务呢?
早期工作是预先为每对任务指定哪些层来分享,这种方法扩展性差且模型结构严重有偏;当任务相关性下降或需要不同level推理时,hard parameter sharing就不行了。
目前比较火的是learning what to share(outperform hard parameter sharing);还有就是对任务层级进行学习在任务具有多粒度因素时也是有用的。
Auxiliary task
我们只关注主任务目标,但是希望从其他有效的辅助任务中获利!
目前选择一些辅助任务方法
- Related task:常规思路(自动驾驶+路标识别; query classification+web search;坐标预测+物体识别;duration+frequency)
- Adversarial:在domain adaption,相关的任务可能无法获取,可以使用对抗任务作为negative task(最大化training error),比如辅助任务为预测输入的domain,则导致主任务模型学习的表征不能区分不同的domain。
- Hints:前面提到的某些特征在某些任务不好学,选择辅助任务为predicting features(NLP中主任务为情感预测,辅助任务为inputs是否包含积极或消极的词;主任务name error detection,辅助任务为句子中是否有name)
- Focusing attention:使模型注意到那些在任务中可能不容易被注意到的部分(自动驾驶+路标检测; 面部识别+头部位置识别)
- Quantization smoothing:某些任务中,训练目标是高度离散化的(人为打分,情感打分,疾病风险等级),使用离散程度较小的辅助任务可能是有帮助的,因为目标更平滑使任务更好学
- prediting inputs:有些场景下,可能不会选择某些特征,由于其不利于预估目标,但是这可能这些特征对模型的训练有一定的帮助,这种场景下,这些特征可以作为outputs而不是inputs
- Using the future to predict the presnet:有些特征只有在决策之后才会有,比如自动驾驶时,当车路过一些物体才得到这些物体的数据;医疗中只有使用过药物才知此药物的效果。这些特征不能作为inputs,但是可以用作辅助任务,来给主任务在训练过程中透露信息。
- representation learning:auxiliary task大多都是潜在地学习一些特征表达,且一定程度上都利于主任务。也可以显示地对此学习(使用一个学习迁移特征表达的辅助任务,比如AE)
那么,哪些auxiliary task是有用的呢?
auxiliary task背后的假设是辅助任务应该在一定程度上与主任务相关,利于主任务的学习。
那么如何衡量两个任务是否相关呢?
一些理论研究:
- 使用相同的特征做决策
- 相关的任务共享同一个最优假设空间(having the same inductive bias)
- F-related: 如果两个任务的数据是通过一个固定分布经过一些变换得到 [28]
- 分类边界(parameter vectors)接近
任务是否相似不是非0即1的,越相似的任务,收益越大。learning what to share允许我们暂时忽略理论上的不足,即使相关性不好的任务之间也能有所收益。但是发展任务之间的相似性对我们在选择辅助任务上也是有绝对的帮助的。
MTL learning Tips
- 紧凑分布均匀的label的辅助任务更好(from POS in NLP)[29]
- 主任务训练曲线更快平稳,辅助任务平稳慢(还未平稳)[30]
- 不同任务尺度不一样,任务最优学习率可能不同
- 某个任务的输出可以作为某些任务的输入
- 某些任务的迭代周期不同,可能需要异步训练(后验信息;特征选择,特征衍生任务等)
- 整体loss可能被某些任务主导,需要整个周期对参数进行动态调整(通过引入一些不确定性,每个任务学习一个噪声参数,统一所有损失 [31]
- 某些估计作为特征(交替训练)
总结
20多岁的hard parameter shareing还是很流行,目前热点learning what to learn也很有价值,我们对tasks的理解(similarity, relationship, hierrarchy, benefit for MTL) 还是很有限的,希望以后有重大发展吧。
可研究方向
- learning what to share
- measurement for similarity of tasks
- using task uncertainty
- 引入异步任务(特征学习任务),采用交替迭代训练
- 学习抽象子任务;学习任务结构(类似强化里面的hierarchy learning)
- 参数学习辅助任务
- More...
备注:本文学习资料主要来自 An Overview of Multi-Task Learning in Deep Neural Networkshttps://arxiv.org/abs/1706.05098**
Reference
[1] A Bayesian/information theoretic model of learning to learn via multiple task sampling. http://link.springer.com/article/10.1023/A:1007327622663
[2] Learning from hints in neural networks. Journal of Complexity https://doi.org/10.1016/0885-064X(90)90006-Y
[3] Multi-Task Feature Learning http://doi.org/10.1007/s10994-007-5040-8
[4] Model selection and estimation in regression with grouped variables
[5] Taking Advantage of Sparsity in Multi-Task Learninghttp://arxiv.org/pdf/0903.1468
[6] A Dirty Model for Multi-task Learning. Advances in Neural Information Processing Systems https://papers.nips.cc/paper/4125-a-dirty-model-for-multi-task-learning.pdf
[7] Distributed Multi-task Relationship Learning http://arxiv.org/abs/1612.04022
[8] Regularized multi-task learning https://doi.org/10.1145/1014052.1014067
[9] Discovering Structure in Multiple Learning Tasks: The TC Algorithm http://scholar.google.com/scholar?cluster=956054018507723832&hl=en
[10] A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data
[11] Empirical Bayes for Learning to Learn
[12] Learning to learn with the informative vector machine https://doi.org/10.1145/1015330.1015382
[13] Task Clustering and Gating for Bayesian Multitask Learning https://doi.org/10.1162/153244304322765658
[14] Multi-Task Learning for Classification with Dirichlet Process Priors
[15] Bayesian multitask learning with latent hierarchies http://dl.acm.org.sci-hub.io/citation.cfm?id=1795131
[16] Linear Algorithms for Online Multitask Classification
[17] Learning with whom to share in multi-task feature learning
[18] Learning Task Grouping and Overlap in Multi-task Learning
[19] Learning Multiple Tasks Using Shared Hypotheses
[20] Learning Multiple Tasks with Deep Relationship Networks http://arxiv.org/abs/1506.02117
[21] Fully-adaptive Feature Sharing in Multi-Task Networks with Applications in Person Attribute Classification http://arxiv.org/abs/1611.05377
[22] Cross-stitch Networks for Multi-task Learning https://doi.org/10.1109/CVPR.2016.433
[23] Deep multi-task learning with low level tasks supervised at lower layers
[24] A Joint Many-Task Model: Growing a Neural Network for Multiple NLP Tasks http://arxiv.org/abs/1611.01587
[25] Multi-Task Learning Using Uncertainty to Weigh Losses for Scene Geometry and Semantics http://arxiv.org/abs/1705.07115
[26] Deep Multi-task Representation Learning: A Tensor Factorisation Approach https://doi.org/10.1002/joe.20070
[27] Sluice networks: Learning what to share between loosely related tasks http://arxiv.org/abs/1705.08142
[28] Exploiting task relatedness for multiple task learning. Learning Theory and Kernel Machines https://doi.org/10.1007/978-3-540-45167-9_41
[29] When is multitask learning effective? Multitask learning for semantic sequence prediction under varying data conditions http://arxiv.org/abs/1612.02251
[30] Identifying beneficial task relations for multi-task learning in deep neural networks http://arxiv.org/abs/1702.08303
[31] Multitask learning using uncertainty to weigh losses for scene geometry and senantics