维基百科中对于“最长回文子串”介绍如下。
在计算机科学中,最长回文子串或最长对称因子问题是在一个字符串中查找一个最长连续子串,这个子串必须是回文。例如“banana”最长回文子串是“anana”。最长回文子串并不能保证是唯一的,
Given a string s, find the longest palindromic substring in s. You may assume that the maximum length of s is 1000.
LeetCode 第 5 题就是“最长回文子串”的模板题。
LeetCode 第 5 题:最长回文子串
传送门:5. 最长回文子串
给定一个字符串
s,找到s中最长的回文子串。你可以假设s的最大长度为 1000。示例 1:
输入: "babad" 输出: "bab" 注意: "aba" 也是一个有效答案。示例 2:
输入: "cbbd" 输出: "bb"
回文串可分为奇数回文串和偶数回文串。
它们的区别是:奇数回文串关于它的“中点”满足“中心对称”,偶数回文串关于它“中间的两个点”满足“中心对称”。
我们在具体判定一个字符串是否是回文串的时候,常常会不自觉地考虑到它们之间的这个小的差别。
思路1:暴力匹配 Brute Force。
暴力匹配,虽然听起来并不是那么友好,但是我个人认为暴力解法虽然时间复杂度很高,但是它简单粗暴,编写正确的概率其实是很高的,完全可以使用暴力匹配算法检验我们编写的算法的正确性,并且在优化正确的前提下,通过和暴力匹配的比较,也可以体现我们优化算法的性能优势。
当然,“最长回文子串”在 LeetCode 上有标准的问题,我们编写好算法以后,可以提交到 LeetCode 上,运行 LeetCode 的测试用例检验我们实现的算法。
思路2:中心扩散法。想法很简单,就是遍历每一个索引,以这个索引为中心,看看往两边扩散,最多能扩散多长的字符串。具体做法是利用“回文串”中心对称的特点,在枚举子串的过程中进行剪枝,在具体解这个问题的过程中,我们就要对可能产生的回文串是奇数长度和偶数长度进行考量,但是完全可以设计一种方法,兼容两种情况。
设计一个方法:传入两个索引编号参数,传入重合的索引编码,进行中心扩散,得到的最长回文子串就是奇数长度的。传入相邻的索引编码,进行中心扩散,得到的最长回文子串就是偶数长度的。
具体编码细节在代码的注释中已经体现。
Python 代码:
class Solution:
def longestPalindrome(self, s):
"""
最长回文子串,比较容易想到的就是中心扩散法
:type s: str
:rtype: str
"""
size = len(s)
if size == 0:
return ''
# 至少就是 1
longest_palindrome = 1
longest_palindrome_str = s[0]
for i in range(size):
palindrome_odd, odd_len = self.__center_spread(s, size, i, i)
palindrome_even, even_len = self.__center_spread(s, size, i, i + 1)
# 当前找到的最长回文子串
cur_max_sub = palindrome_odd if odd_len >= even_len else palindrome_even
if len(cur_max_sub) > longest_palindrome:
longest_palindrome = len(cur_max_sub)
longest_palindrome_str = cur_max_sub
return longest_palindrome_str
def __center_spread(self, s, size, left, right):
"""
left = right 的时候,表示回文中心是一条线,回文串的长度是奇数
right = left + 1 的时候,表示回文中心是任意一个字符,回文串的长度是偶数
:param s:
:param size:
:param left:
:param right:
:return:
"""
l = left
r = right
while l >= 0 and r < size and s[l] == s[r]:
l -= 1
r += 1
return s[l + 1:r], r - l - 1
Java 代码:
public class Solution {
public String longestPalindrome(String s) {
int len = s.length();
if (len == 0) {
return "";
}
int longestPalindrome = 1;
String longestPalindromeStr = s.substring(0, 1);
for (int i = 0; i < len; i++) {
String palindromeOdd = centerSpread(s, len, i, i);
String palindromeEven = centerSpread(s, len, i, i + 1);
String maxLen = palindromeOdd.length() > palindromeEven.length() ? palindromeOdd : palindromeEven;
if (maxLen.length() > longestPalindrome) {
longestPalindrome = maxLen.length();
longestPalindromeStr = maxLen;
}
}
return longestPalindromeStr;
}
private String centerSpread(String s, int len, int left, int right) {
int l = left;
int r = right;
while (l >= 0 && r < len && s.charAt(l) == s.charAt(r)) {
l--;
r++;
}
// 这里要特别小心,跳出 while 循环的时候,是第 1 个满足 s.charAt(l) != s.charAt(r) 的时候
// 所以,不能取 l,不能取 r
return s.substring(l + 1, r);
}
}
思路3:动态规划。
有了计算机的帮助,解决这类“最优子结构”问题,当然是在“动态规划”的能力范围内。我们只要找准“状态”的定义,找到“状态转移方程”就可以了。当然,在实现的过程中,还有一些小细节。
定义状态:s[i, j] :表示原始字符串的一个子串,i、j分别是索引,使用闭区间表示包括区间左右端点。
dp[i, j]:如果子串 s[i,...,j] 是回文串,那么 dp[i, j] = true。即二维 dp:dp[i, j] 表示子串 s[i, j](包括区间左右端点)是否构成回文串,是一个二维布尔型数组。
状态转移方程:在 dp[i, j] = true 的时候, dp[i + 1, j - 1] = true,因此,如果已知 dp[i + 1, j - 1],就可以通过比较 s[i] 和 s[j] 并且考虑 dp[i + 1, j - 1] 进而得到 dp[i, j]。
如果 s[i, j] 是一个回文串,例如 “abccba”,那么 s[i+1, j-1] 也一定是一个回文串,根据这个递归的性质,我们可以写出状态转移方程。
dp[i, j] = dp[i+1, j-1],当然,此时我们要保证 [i+1, j-1] 能够形成区间,因此有
i+1<=j-1,整理得 i-j <= -2,或者 j-i >=2。
具体编码细节在代码的注释中已经体现。
Python 代码:
class Solution(object):
def longestPalindrome(self, s):
"""
:type s: str
:rtype: str
"""
size = len(s)
if size <= 1:
return s
# 二维 dp 问题
# 状态:dp[i,j]: s[i:j] 包括 i,j ,表示的字符串是不是回文串
dp = [[False for _ in range(size)] for _ in range(size)]
longest_l = 1
res = s[0]
for i in range(size):
for j in range(i):
# 状态转移方程:如果头尾字符相等并且中间也是回文
# 或者中间的长度小于等于 1
if s[j] == s[i] and (j >= i - 2 or dp[j + 1][i - 1]):
dp[j][i] = True
if i - j + 1 > longest_l:
longest_l = i - j + 1
res = s[j:i + 1]
return res
Java 代码:
public class Solution2 {
public String longestPalindrome(String s) {
int len = s.length();
if (len == 0) {
return "";
}
int longestPalindrome = 1;
String longestPalindromeStr = s.substring(0, 1);
boolean[][] dp = new boolean[len][len];
// abcdedcba
// j i
// 如果 dp[j,i] = true 那么 dp[j+1,i-1] 也一定为 true
// [j+1,i-1] 一定要构成至少两个元素额区间( 1 个元素的区间,s.charAt(i)==s.charAt(j) 已经判断过了)
// 即 j+1 < i-1,即 i > j + 2 (不能取等号,取到等号,就退化成 1 个元素的情况了)
// 应该反过来写
for (int i = 0; i < len; i++) {
for (int j = 0; j <= i; j++) {
// 区间应该慢慢放大
if (s.charAt(i) == s.charAt(j) && (i <= j + 2 || dp[j + 1][i - 1])) {
// 写成 dp[j][i] 就大错特错了,不要顺手写习惯了
dp[j][i] = true;
if (i - j + 1 > longestPalindrome) {
longestPalindrome = i - j + 1;
longestPalindromeStr = s.substring(j, i + 1);
}
}
}
}
return longestPalindromeStr;
}
}
思路4:专门解决回文串的一个著名算法 Manacher 算法。
很有意思的一件事情是:Manacher 算法被中国程序员戏称为“马拉车”算法。事实上,“马拉车”算法在思想上和“KMP”字符串匹配算法一样,都避免做了很多重复的工作,“KMP”算法也有一个很有意思的戏称。
Manacher 算法就是专门解决“最长回文子串”的一个算法,它的时间复杂度可以达到 ,虽然是特性的算法,并不具有普遍性,但它的代码量小,处理技巧优雅,是值得我们学习的。
挺有意思的一件事情是,我在学习“树状数组”和“Manacher 算法”的时候,都是看了很多很多资料,但是到最后,代码实现的时候,就只有短短十几行,另外“KMP 算法”也是如此。
Manacher 算法
维基百科中对于 Manacher 算法是这样描述的:
[Manacher(1975)] 发现了一种线性时间算法,可以在列出给定字符串中从字符串头部开始的所有回文。并且,Apostolico, Breslauer & Galil (1995) 发现,同样的算法也可以在任意位置查找全部最大回文子串,并且时间复杂度是线性的。因此,他们提供了一种时间复杂度为线性的最长回文子串解法。替代性的线性时间解决 Jeuring (1994), Gusfield (1997)提供的,基于后缀树(suffix trees)。也存在已知的高效并行算法。
在还没有实现算法之前,我们先要弄清楚算法的运行流程,即给我们一个具体的字符串,我们通过稿纸演算的方式,应该如何得到给定字符串的最长子回文串。
理解 Manacher 算法最好的办法,其实是根据一些关于 Manacher 算法的文章,自己写写画画,最好能产生一些输出,画画图,举一些具体的例子,这样 Manacher 算法就不难搞懂了。
Manacher 算法本质上还是中心扩散法,只不过它使用了类似 KMP 算法的技巧,充分挖掘了已经进行回文判定的子串的特点,使得算法高效。
回文串可分为奇数回文串和偶数回文串,它们的区别是:奇数回文串关于它的“中点”满足“中心对称”,偶数回文串关于它“中间的两个点”满足“中心对称”。我们在具体判定一个字符串是否是回文串的时候,常常会不自觉地考虑到它们之间的这个小的差别。
第 1 步:预处理,添加分隔符
我们先给出具体的例子,看看如何添加分隔符。
例1:给字符串
"bob"添加分隔符"#"。答:
"bob"添加分隔符"#"以后得到:"#b#o#b#"。
再看一个例子:
例2:给
"noon"添加分隔符"#"。答:
"noon"添加分隔符"#"以后得到:"#n#o#o#n#"。
我想你已经看出来分隔符是如何添加的,下面是 2 点说明。
1、分隔符是字符串中没有出现过的字符,这个分隔符的种类只有一个,即你不能同时添加 "#" 和 "?" 作为分隔符;
2、在字符串的首位置、尾位置和每个字符的“中间”都添加 个这个分隔符,可以很容易知道,如果这个字符串的长度是 len,那么添加的分隔符的个数就是 len + 1,得到的新的字符串的长度就是 2len + 1,显然它一定是奇数。
为什么要添加分隔符?
1、首先是正确性:添加了分隔符以后的字符串的回文性质与原始字符串是一样的。
2、其实是避免奇偶数讨论,对于使用“中心扩散法”判定回文串的时候,长度为奇数和偶数的判定是不同的,添加分隔符可以避免对奇偶性的讨论。
第 2 步:得到 p 数组
首先,我们先来看一下如何填表。以字符串 "abbabb" 为例,说明如何手动计算得到 p 数组。假设我们要填的就是下面这张表。
| char | # | a | # | b | # | b | # | a | # | b | # | b | # |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| index | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| p | 1 | 2 | 1 | 2 | 5 | ||||||||
| p-1 |
第 1 行 char 数组:这个数组就是待检测字符串加上分隔符以后的字符构成的数组。
第 2 行 index 数组:这个数组是索引数组,我们后面要利用到它,填写即索引从 0 开始写就好了。
下面我们来看看 p 数组应该如何填写。首先我们定义回文半径。
回文半径:以 char[i] 作为回文中心,同时向左边、向右边进行扩散,直到不能构成回文串或者触碰到边界为止,能扩散的步数 + 1 ,即定义为 p 数组索引的值,也称之为回文半径。
以上面的例子,我们首先填。p[0],以 char[0] = '#'为中心,同时向左边向右扩散,走 1 步就碰到边界了,因此“能扩散的步数”为0,“能扩散的步数 + 1 = 1”,因此 p[0] = 1;
| char | # | a | # | b | # | b | # | a | # | b | # | b | # |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| index | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| p | 1 | ||||||||||||
| p-1 |
下面填写 p[1] ,以 char[1] = 'a' 为中心,同时向左边向右扩散,走 1 步,左右都是 "#",构成回文子串,于是继续同时向左边向右边扩散,左边就碰到边界了,因此“能扩散的步数”为1,“能扩散的步数 + 1 = 2”,因此 p[1] = 2;
| char | # | a | # | b | # | b | # | a | # | b | # | b | # |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| index | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| p | 1 | 2 | |||||||||||
| p-1 |
下面填写 p[2] ,以 char[2] = '#' 为中心,同时向左边向右扩散,走 1 步,左边是 "a",右边是 "b",不匹配,因此“能扩散的步数”为 ,“能扩散的步数 + 1 = 1”,因此 p[2] = 1;
| char | # | a | # | b | # | b | # | a | # | b | # | b | # |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| index | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| p | 1 | 2 | 1 | ||||||||||
| p-1 |
下面填写 p[3],以 char[3] = 'b' 为中心,同时向左边向右扩散,走 1 步,左右两边都是 “#”,构成回文子串,继续同时向左边向右扩散,左边是 "a",右边是 "b",不匹配,因此“能扩散的步数”为1,“能扩散的步数 + 1 = 2”,因此 p[3] = 2;
| char | # | a | # | b | # | b | # | a | # | b | # | b | # |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| index | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| p | 1 | 2 | 1 | 2 | |||||||||
| p-1 |
下面填写 p[4],以 char[4]='#' 为中心,同时向左边向右扩散,可以知道可以同时走 4 步,左边到达边界,因此“能扩散的步数”为4,“能扩散的步数 + 1 = 5”,因此 p[4] = 5。
| char | # | a | # | b | # | b | # | a | # | b | # | b | # |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| index | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| p | 1 | 2 | 1 | 2 | 5 | ||||||||
| p-1 |
分析到这里,后面的数字不难填出,最后写成如下表格:
| char | # | a | # | b | # | b | # | a | # | b | # | b | # |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| index | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| p | 1 | 2 | 1 | 2 | 5 | 2 | 1 | 6 | 1 | 2 | 3 | 2 | 1 |
| p-1 |
p-1 数组很简单了,把 p 数组的数 -1 就行了。实际上直接把能走的步数记录下来就好了。不过就是为了给“回文半径”一个定义而已。
于是我们得到如下表格:
| char | # | a | # | b | # | b | # | a | # | b | # | b | # |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| index | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| p | 1 | 2 | 1 | 2 | 5 | 2 | 1 | 6 | 1 | 2 | 3 | 2 | 1 |
| p-1 | 0 | 1 | 0 | 1 | 4 | 1 | 0 | 5 | 0 | 1 | 2 | 1 | 0 |
于是:数组 p -1 的最大值就是最长的回文子串,可以在得到 p 数组的过程中记录这个最大值,并且记录最长回文子串。
如何编写程序得到 p 数组?
通过 p 数组我们就可以找到回文串的最大值,就能确定最长回文子串了。那么下面我们就来看如何编码求 p 数组,需要设置两个辅助变量 mx 和 id ,它们的含义分别如下:
id :从开始到现在使用中心扩散法得到的最长回文子串的中心的位置;
mx:从开始到现在使用中心扩散法得到的最长回文子串能延伸到的最右端的位置。
数组 p 的值就与它们两个有关,这个算法的最核心的一行如下:
p[i] = mx > i ? min(p[2 * id - i], mx - i) : 1;
可以这么说,这行要是理解了,那么马拉车算法基本上就没啥问题了,那么这一行代码拆开来看就是:
如果 mx > i, 则 p[i] = min(p[2 * id - i], mx - i),否则, p[i] = 1。
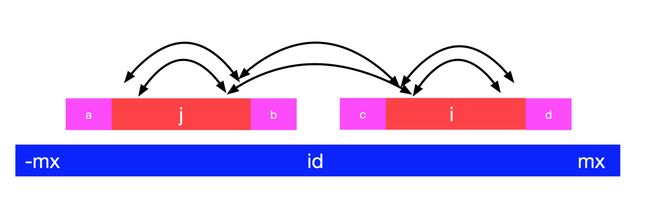
这里 2 * id - i 是 i 关于 id 的对称索引。
我们通过分类讨论,就可以得到这个等式。一开始,我们是不能偷懒的,老老实实使用中心扩散法来逐渐得到 p 数组的值,同时记录 id 和 mx。当我们要考察的索引 i 超过了 mx 的时候,如下图,我们就可以偷点懒了。根据回文串的特点,i 关于 mx 的对称点附近的情况我们已经计算出来了,因此,我们可以分如下两种情况讨论。
讨论从一个中间的情况开始:
1、首先当 i 位于 id 和 mx 之间时,此时 id 之前的 p 值都已经计算出来了,我们利用已经计算出来的 p 值来计算当前考虑的位置的 p 值。
因为是回文串,因此在 mx 的对称点与 id 这个区间内,一定有一个点与 j 相等,这个点的索引就是 2 * id - i。
当 id < i < mx 的时候:
引入 j,如果 j 的回文串很短,在 mx 关于 id 的对称点之前结束。
此时 j = 2 * id - i,
if i < mx:
p[i] = min(p[2 * id - i], mx - i);
当 j 的范围很小的时候,取 p[2 * id - i] ,此时 p[i] = p[j]。
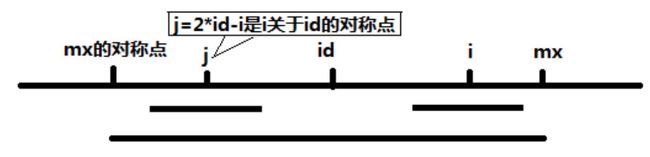
2、当 mx - i > p[j] 的时候,以 s[j] 为中心的回文子串包含在以 s[id] 为中心的回文子串中,由于 i 和 j 对称,以 s[i] 为中心的回文子串必然包含在以 s[id] 为中心的回文子串中,所以必有 p[i] = p[j],见下图。

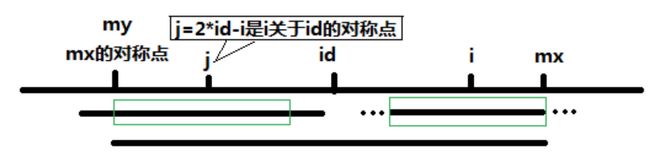
3、当 p[j] >= mx - i 的时候,以 s[j] 为中心的回文子串不一定完全包含于以 s[id] 为中心的回文子串中,但是基于对称性可知,下图中两个绿框所包围的部分是相同的,也就是说以 s[i] 为中心的回文子串,其向右至少会扩张到 mx 的位置,也就是说 p[i] >= mx - i。至于 mx 之后的部分是否对称,就只能老老实实去匹配了。
4、对于 mx <= i 的情况,无法对 p[i] 做更多的假设,只能从 p[i] = 1 开始,然后再去匹配了。
Java 代码:
/**
* 使用 Manacher 算法
*/
public class Solution3 {
/**
* 创建分隔符分割的字符串
*
* @param s 原始字符串
* @param divide 分隔字符
* @return 使用分隔字符处理以后得到的字符串
*/
private String generateSDivided(String s, char divide) {
int len = s.length();
if (len == 0) {
return "";
}
if (s.indexOf(divide) != -1) {
throw new IllegalArgumentException("参数错误,您传递的分割字符,在输入字符串中存在!");
}
StringBuilder sBuilder = new StringBuilder();
sBuilder.append(divide);
for (int i = 0; i < len; i++) {
sBuilder.append(s.charAt(i));
sBuilder.append(divide);
}
return sBuilder.toString();
}
public String longestPalindrome(String s) {
int len = s.length();
if (len == 0) {
return "";
}
String sDivided = generateSDivided(s, '#');
int slen = sDivided.length();
int[] p = new int[slen];
int mx = 0;
// id 是由 mx 决定的,所以不用初始化,只要声明就可以了
int id = 0;
int longestPalindrome = 1;
String longestPalindromeStr = s.substring(0, 1);
for (int i = 0; i < slen; i++) {
if (i < mx) {
// 这一步是 Manacher 算法的关键所在,一定要结合图形来理解
// 这一行代码是关键,可以把两种分类讨论的情况合并
p[i] = Integer.min(p[2 * id - i], mx - i);
} else {
// 走到这里,只可能是因为 i = mx
if (i > mx) {
throw new IllegalArgumentException("程序出错!");
}
p[i] = 1;
}
// 老老实实去匹配,看新的字符
while (i - p[i] >= 0 && i + p[i] < slen && sDivided.charAt(i - p[i]) == sDivided.charAt(i + p[i])) {
p[i]++;
}
// 我们想象 mx 的定义,它是遍历过的 i 的 i + p[i] 的最大者
// 写到这里,我们发现,如果 mx 的值越大,
// 进入上面 i < mx 的判断的可能性就越大,这样就可以重复利用之前判断过的回文信息了
if (i + p[i] > mx) {
mx = i + p[i];
id = i;
}
if (p[i] - 1 > longestPalindrome) {
longestPalindrome = p[i] - 1;
longestPalindromeStr = sDivided.substring(i - p[i] + 1, i + p[i]).replace("#", "");
}
}
return longestPalindromeStr;
}
}
参考资料
Manacher's Algorithm 马拉车算法 - Grandyang - 博客园
https://www.cnblogs.com/grandyang/p/4475985.html
【看这篇文章就可以看懂】
Manacher算法总结 - CSDN博客 https://blog.csdn.net/dyx404514/article/details/42061017
最长回文子串——Manacher 算法 - 曾会玩 - SegmentFault 思否 https://segmentfault.com/a/1190000003914228#articleHeader7
Manacher算法及其Java实现 - CSDN博客 https://blog.csdn.net/simaxiaochen/article/details/62043408
参考资料:https://blog.csdn.net/hk2291976/article/details/51107886
1、https://subetter.com/articles/2018/03/manacher-algorithm.html(这篇文章的图最好了,把关键的部分和 代码都给出来了)
2、https://blog.csdn.net/xingyeyongheng/article/details/9310555
3、https://zhuhongcheng.wordpress.com/2009/08/02/a-simple-linear-time-algorithm-for-finding-longest-palindrome-sub-string/
4、https://blog.csdn.net/xingyeyongheng/article/details/9310555
介绍算法有图。
5、动态规划的做法:
https://www.geeksforgeeks.org/longest-palindrome-substring-set-1/
6、也有图和 Python 代码
https://segmentfault.com/a/1190000003914228
https://segmentfault.com/a/1190000003914228
https://zh.wikipedia.org/wiki/%E6%9C%80%E9%95%BF%E5%9B%9E%E6%96%87%E5%AD%90%E4%B8%B2
(本节完)