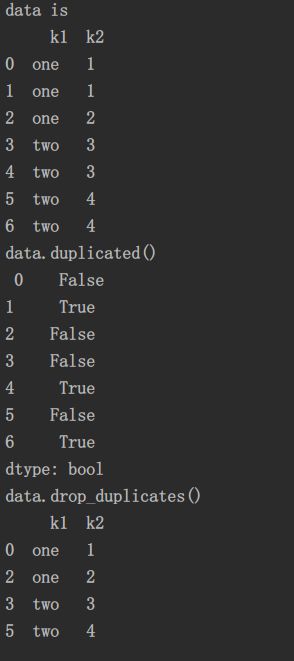
1.去重 data.drop_duplicates()
默认保留第一个值,take_last=True 返回最后一个值。
data.drop_duplicates(['k1','k2'],take_last=True)
2. 替换 ,data.replace()

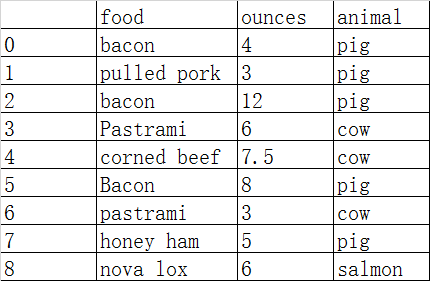
数据表:data=DataFrame({'food':['bacon','pulled pork','bacon','Pastrami','corned beef','Bacon','pastrami','honey ham','nova lox'],'ounces':[4,3,12,6,7.5,8,3,5,6]})

另一个是维表
meat_to_animal = {
'bacon':'pig',
'pulled pork':'pig',
'pastrami':'cow',
'corned beef':'cow',
'honey ham':'pig',
'nova lox':'salmon'
}
3.将这两个表关联起来,.map可以将data frame中的column,作用一些函数,或者map一个维表
data['animal']=data['food'].map(str.lower).map(meat_to_animal)
food列都变成了小写,且animal列也映射成功
4,下一个函数跟index相关,我们先把food列变成index
data1=data.set_index('food')
将index首字母大写,columns名称大写
data2=data1.rename(index=str.title,columns=str.upper)
Index和column改名,Index 的Bacon 改为 little Bacon, column的OUNCES 改为weight
data3=data2.rename(index={'Bacon':'Little Bacon'},columns={'OUNCES':'weight'})

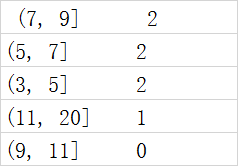
5.区间数据统计,用bins框定几个区间,然后将一个数组data3的weight列,按照这几个区间设定level,看看都属于哪个level. pd.cut,左开右闭的形式,pd.value_counts(cats),可以最终统计各个分布
bins=[3,5,7,9,11,20]
W1=data3['weight']
cats=pd.cut(W1,bins)

pd.value_counts(cats)
左边的区间,可以定义其他名称,据目前观察,labels竟然是按照字母顺序排列的,所以只能想到加序号这个笨办法了
group_names = ['1S','2S-M','3M','4M-L','5L']
cats_group=pd.cut(W1,bins,labels=group_names)
