本系列已经写了二十篇了,但推荐系统的东西还有很多值得探索和学习的地方。不过在这之前,我们先静下心来,一起回顾下之前学习到的东西!
由于是总结性质的文章,很多细节不会过多的涉及,有兴趣的同学可以点击文章中给出的链接进行学习。
本文中涉及的大多数算法是计算广告中点击率预估用到的模型,当然也会涉及pair-wise的模型如贝叶斯个性排序以及list-wise的如京东的强化学习推荐模型。
好了,废话不多说,咱们开始吧。先看一下目录:
1、推荐系统中常用评测指标
1.1精确率、召回率、F1值
1.2 AUC
1.3 Hit Ratio(HR)
1.4 Mean Average Precision(MAP)
1.5 Normalized Discounted Cummulative Gain(NDCG)
1.6 Mean Reciprocal Rank (MRR)
1.7 ILS
2、点击率预估问题中的数据
3、传统方法
3.1 线性模型
3.2 FM模型
3.3 FFM模型
3.4 GBDT+LR模型
4、深度学习方法
4.1 并行结构
4.1.1 Wide & Deep模型
4.1.2 DeepFM模型
4.1.3 Deep Cross Network
4.2 串行结构
4.2.1 Product-based Neural Network
4.2.2 Neural factorization machines
4.2.3 Attention-Based factorization machines
5、强化学习方法
6、推荐系统的EE问题
6.1 Bandit算法
6.2 LinUCB算法
7、推荐系统在公司中的实战
7.1 阿里MLR算法
7.2 阿里Deep Interest Network
7.3 阿里ESSM模型
7.4 京东强化学习推荐模型
1、推荐系统中常用评测指标
评测指标并非我们的损失函数,对于CTR预估问题来说,我们可以当作回归问题而选择平方损失函数,也可以当作分类问题而选择对数损失函数。
不过评测指标,是对我们推荐效果的评价,用于评估推荐效果的好坏,不用于指导我们模型的训练。因此在一般的基于深度学习的模型中,常常面临模型训练和评估时指标不一致的问题。好了,我们先来回顾一下常用的评测指标。这些指标有的适用于二分类问题,有的适用于对推荐列表topk的评价。
1.1精确率、召回率、F1值
我们首先来看一下混淆矩阵,对于二分类问题,真实的样本标签有两类,我们学习器预测的类别有两类,那么根据二者的类别组合可以划分为四组,如下表所示:

基于混淆矩阵,我们可以得到如下的评测指标:
精确率/召回率
精确率表示预测结果中,预测为正样本的样本中,正确预测为正样本的概率;
召回率表示在原始样本的正样本中,最后被正确预测为正样本的概率;
二者用混淆矩阵计算如下:
F1值
为了折中精确率和召回率的结果,我们又引入了F-1 Score,计算公式如下:
1.2 AUC
AUC定义为ROC曲线下方的面积:
ROC曲线的横轴为“假正例率”(True Positive Rate,TPR),又称为“假阳率”;纵轴为“真正例率”(False Positive Rate,FPR),又称为“真阳率”,
下图就是我们绘制的一张ROC曲线图,曲线下方的面积即为AUC的值:

AUC还有另一种解释,就是测试任意给一个正类样本和一个负类样本,正类样本的score有多大的概率大于负类样本的score。
1.3 Hit Ratio(HR)
在top-K推荐中,HR是一种常用的衡量召回率的指标,其计算公式如下:
分母是所有的测试集合,分子式每个用户top-K推荐列表中属于测试集合的个数的总和。举个简单的例子,三个用户在测试集中的商品个数分别是10,12,8,模型得到的top-10推荐列表中,分别有6个,5个,4个在测试集中,那么此时HR的值是 (6+5+4)/(10+12+8) = 0.5。
1.4 Mean Average Precision(MAP)
在了解MAP(Mean Average Precision)之前,先来看一下AP(Average Precision), 即为平均准确率。比如对于用户 u, 我们给他推荐一些物品,那么 u 的平均准确率定义为:

用一个例子来解释AP的计算过程:

因此该user的AP为(1 + 0.66 + 0.5) / 3 = 0.72
那么对于MAP(Mean Average Precision),就很容易知道即为所有用户 u 的AP再取均值(mean)而已。那么计算公式如下:
1.5 Normalized Discounted Cummulative Gain(NDCG)
对于NDCG,我们需要一步步揭开其神秘的面纱,先从CG说起:
CG
我们先从CG(Cummulative Gain)说起, 直接翻译的话叫做“累计增益”。 在推荐系统中,CG即将每个推荐结果相关性(relevance)的分值累加后作为整个推荐列表(list)的得分。即
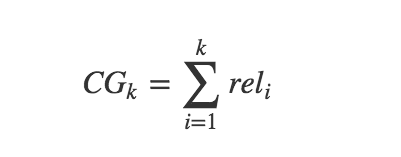
这里, rel-i 表示处于位置 i 的推荐结果的相关性,k 表示所要考察的推荐列表的大小。
DCG
CG的一个缺点是没有考虑每个推荐结果处于不同位置对整个推荐效果的影响,例如我们总是希望相关性高的结果应排在前面。显然,如果相关性低的结果排在靠前的位置会严重影响用户体验, 所以在CG的基础上引入位置影响因素,即DCG(Discounted Cummulative Gain), “Discounted”有打折,折扣的意思,这里指的是对于排名靠后推荐结果的推荐效果进行“打折处理”:
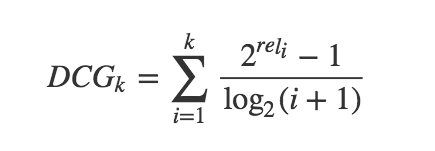
从上面的式子可以得到两个结论:
1)推荐结果的相关性越大,DCG越大。
2)相关性好的排在推荐列表的前面的话,推荐效果越好,DCG越大。
NDCG
DCG仍然有其局限之处,即不同的推荐列表之间,很难进行横向的评估。而我们评估一个推荐系统,不可能仅使用一个用户的推荐列表及相应结果进行评估, 而是对整个测试集中的用户及其推荐列表结果进行评估。 那么不同用户的推荐列表的评估分数就需要进行归一化,也即NDCG(Normalized Discounted Cummulative Gain)。
在介绍NDCG之前,还需要了解一个概念:IDCG. IDCG, 即Ideal DCG, 指推荐系统为某一用户返回的最好推荐结果列表, 即假设返回结果按照相关性排序, 最相关的结果放在最前面, 此序列的DCG为IDCG。因此DCG的值介于 (0,IDCG] ,故NDCG的值介于(0,1],那么用户u的NDCG@K定义为:

因此,平均NDCG计算为:
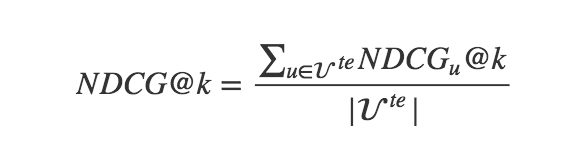
1.6 Mean Reciprocal Rank (MRR)
MRR计算公式如下:

其中|Q|是用户的个数,ranki是对于第i个用户,推荐列表中第一个在ground-truth结果中的item所在的排列位置。
举个例子,有三个用户,推荐列表中正例的最小rank值分别为3,2,1,那么MRR=(1 + 0.5 + 0.33) / 3 = 0.61
1.7 ILS
ILS是衡量推荐列表多样性的指标,计算公式如下:

如果S(bi,bj)计算的是i和j两个物品的相似性,如果推荐列表中物品越不相似,ILS越小,那么推荐结果的多样性越好。
关于推荐系统评价指标更多的知识,可以看之前总结的两篇文章:
推荐系统遇上深度学习(九)--评价指标AUC原理及实践:https://www.jianshu.com/p/4dde15a56d44
推荐系统遇上深度学习(十六)--详解推荐系统中的常用评测指标:https://www.jianshu.com/p/665f9f168eff
相关的代码实现在这里:https://github.com/princewen/tensorflow_practice/tree/master/recommendation/Basic-Evaluation-metrics
2、点击率预估问题中的数据
点击率预估问题中的数据主要分为离散变量和连续变量,对于连续变量,直接带入计算即可,对于离散(类别)变量,我们往往采用one-hot形式,比如对于下面的数据:

将上面的数据进行one-hot编码以后,就变成了下面这样:

过one-hot编码以后,不可避免的样本的数据就变得很稀疏。举个非常简单的例子,假设淘宝或者京东上的item为100万,如果对item这个维度进行one-hot编码,光这一个维度数据的稀疏度就是百万分之一。由此可见,数据的稀疏性,是我们在实际应用场景中面临的一个非常常见的挑战与问题。
3、传统方法
3.1 线性模型
一般的线性模型为:
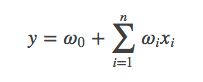
从上面的式子很容易看出,一般的线性模型没有考虑特征间的关联。为了表述特征间的相关性,我们采用多项式模型。在多项式模型中,特征xi与xj的组合用xixj表示。为了简单起见,我们讨论二阶多项式模型。具体的模型表达式如下:
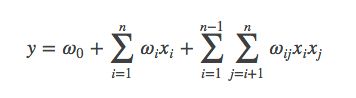
上式中,n表示样本的特征数量,xi表示第i个特征。
但是对于线性模型来说,泛化能力较弱,特别是对于同一个离散特征展开的one-hot特征来说,两两之间的乘积总是为0。
3.2 FM模型
FM为每一个特征引入了一个隐变量,并且用隐变量的乘积来作为特征交叉的权重:
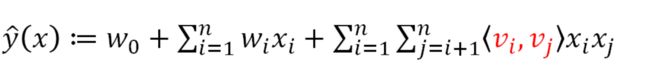

FM的特征交叉部分可以通过化简来简化计算,过程如下;

有关FM的更多细节,参考文章:推荐系统遇上深度学习(一)--FM模型理论和实践:https://www.jianshu.com/p/152ae633fb00
代码地址:https://github.com/princewen/tensorflow_practice/tree/master/recommendation/recommendation-FM-demo
3.3 FFM模型
FFM模型在FM的基础上,中引入了类别的概念,即field。还是拿上一讲中的数据来讲,先看下图:

在上面的广告点击案例中,“Day=26/11/15”、“Day=1/7/14”、“Day=19/2/15”这三个特征都是代表日期的,可以放到同一个field中。同理,Country也可以放到一个field中。简单来说,同一个categorical特征经过One-Hot编码生成的数值特征都可以放到同一个field,包括用户国籍,广告类型,日期等等。
在FFM中,每一维特征 xi,针对其它特征的每一种field fj,都会学习一个隐向量 v_i,fj。因此,隐向量不仅与特征相关,也与field相关。也就是说,“Day=26/11/15”这个特征与“Country”特征和“Ad_type"特征进行关联的时候使用不同的隐向量,这与“Country”和“Ad_type”的内在差异相符,也是FFM中“field-aware”的由来。
假设样本的 n个特征属于 f个field,那么FFM的二次项有 nf个隐向量。而在FM模型中,每一维特征的隐向量只有一个。FM可以看作FFM的特例,是把所有特征都归属到一个field时的FFM模型。根据FFM的field敏感特性,可以导出其模型方程。

可以看到,如果隐向量的长度为 k,那么FFM的二次参数有 nfk 个,远多于FM模型的 nk个。此外,由于隐向量与field相关,FFM二次项并不能够化简,其预测复杂度是 O(kn^2)。
有关FFM的更多细节,参考文章:推荐系统遇上深度学习(二)--FFM模型理论和实践:https://www.jianshu.com/p/781cde3d5f3d
代码地址:https://github.com/princewen/tensorflow_practice/tree/master/recommendation/recommendation-FFM-Demo
3.4 GBDT+LR模型
Facebook 2014年的文章介绍了通过GBDT解决LR的特征组合问题,随后Kaggle竞赛也有实践此思路,GBDT与LR融合开始引起了业界关注。
GBDT和LR的融合方案,FaceBook的paper中有个例子:
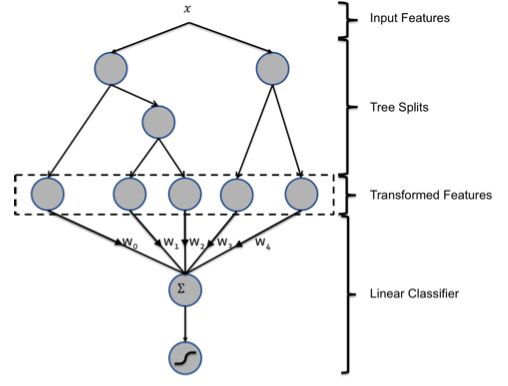
图中共有两棵树,x为一条输入样本,遍历两棵树后,x样本分别落到两颗树的叶子节点上,每个叶子节点对应LR一维特征,那么通过遍历树,就得到了该样本对应的所有LR特征。构造的新特征向量是取值0/1的。举例来说:上图有两棵树,左树有三个叶子节点,右树有两个叶子节点,最终的特征即为五维的向量。对于输入x,假设他落在左树第一个节点,编码[1,0,0],落在右树第二个节点则编码[0,1],所以整体的编码为[1,0,0,0,1],这类编码作为特征,输入到LR中进行分类。
有关GBDT+LR的更多细节,参考文章:推荐系统遇上深度学习(十)--GBDT+LR融合方案实战:https://www.jianshu.com/p/96173f2c2fb4
代码地址:https://github.com/princewen/tensorflow_practice/tree/master/recommendation/GBDT%2BLR-Demo
4、深度学习方法
在CTR预估中,为了解决稀疏特征的问题,学者们提出了FM模型来建模特征之间的交互关系。但是FM模型只能表达特征之间两两组合之间的关系,无法建模两个特征之间深层次的关系或者说多个特征之间的交互关系,因此学者们通过Deep Network来建模更高阶的特征之间的关系。
因此 FM和深度网络DNN的结合也就成为了CTR预估问题中主流的方法。有关FM和DNN的结合有两种主流的方法,并行结构和串行结构。两种结构的理解以及实现如下表所示:
| 结构 | 描述 | 常见模型 |
|---|---|---|
| 并行结构 | FM部分和DNN部分分开计算,只在输出层进行一次融合得到结果 | DeepFM,DCN,Wide&Deep |
| 串行结构 | 将FM的一次项和二次项结果(或其中之一)作为DNN部分的输入,经DNN得到最终结果 | PNN,NFM,AFM |
两类结构的典型网络模型如下图:
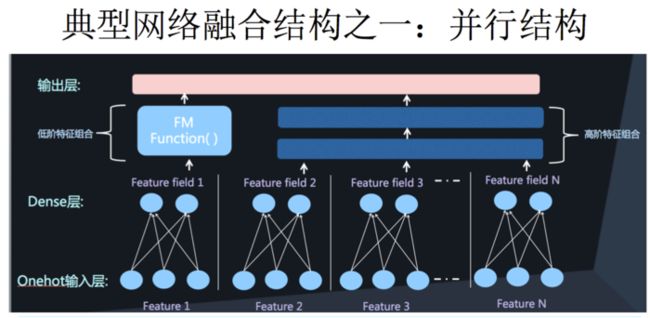
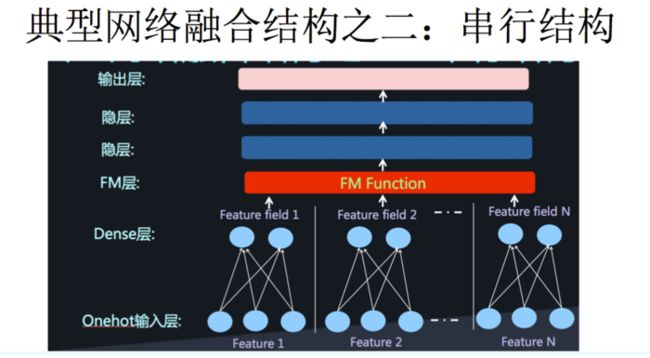
下面,我们回顾一下这两类结构的典型模型。
4.1 并行结构
4.1.1 Wide & Deep模型
Wide & Deep模型本系列还没有整理,不过可以简单介绍一下。Wide & Deep模型结构如下:

Wide部分
wide部分就是一个广义线性模型,输入主要由两部分,一部分是原始特征,另一部分是交互特征,我们可以通过cross-product transformation的形式来构造K组交互特征:
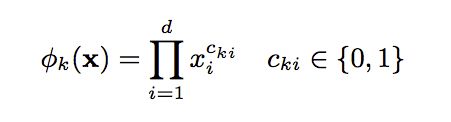
Deep部分
Deep部分就是一个DNN的模型,每一层计算如下:

联合训练
Wide & Deep模型采用的是联合训练的形式,而非集成。二者的区别就是联合训练公用一个损失函数,然后同时更新各个部分的参数,而集成方法是独立训练N个模型,然后进行融合。因此,模型的输出为:
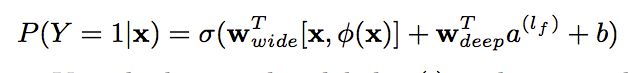
有关Wide&Deep模型更多的细节,大家可以阅读原论文,或者关注本系列后续的文章。
4.1.2 DeepFM模型
我们先来看一下DeepFM的模型结构:
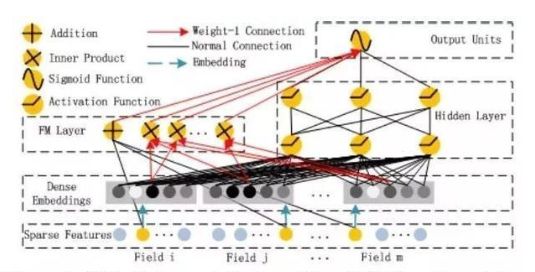
DeepFM包含两部分:神经网络部分与因子分解机部分,分别负责低阶特征的提取和高阶特征的提取。这两部分共享同样的输入。DeepFM的预测结果可以写为:
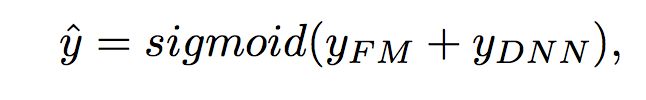
FM部分
FM部分的详细结构如下:

FM部分是一个因子分解机。这里我们不再过多介绍。FM的输出公式为:
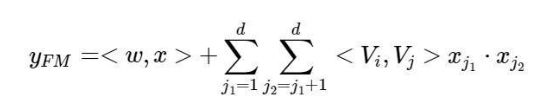
深度部分

深度部分是一个前馈神经网络。与图像或者语音这类输入不同,图像语音的输入一般是连续而且密集的,然而用于CTR的输入一般是及其稀疏的。因此需要重新设计网络结构。具体实现中为,在第一层隐含层之前,引入一个嵌入层来完成将输入向量压缩到低维稠密向量。

嵌入层(embedding layer)的结构如上图所示。当前网络结构有两个有趣的特性,1)尽管不同field的输入长度不同,但是embedding之后向量的长度均为K。2)对同一个特征来说,FM的隐变量和Embedding之后的向量是相同的,这两部分共享同样的输入。
有关DeepFM的更多细节,参考文章:推荐系统遇上深度学习(三)--DeepFM模型理论和实践:https://www.jianshu.com/p/6f1c2643d31b
代码地址:https://github.com/princewen/tensorflow_practice/tree/master/recommendation/Basic-DeepFM-model
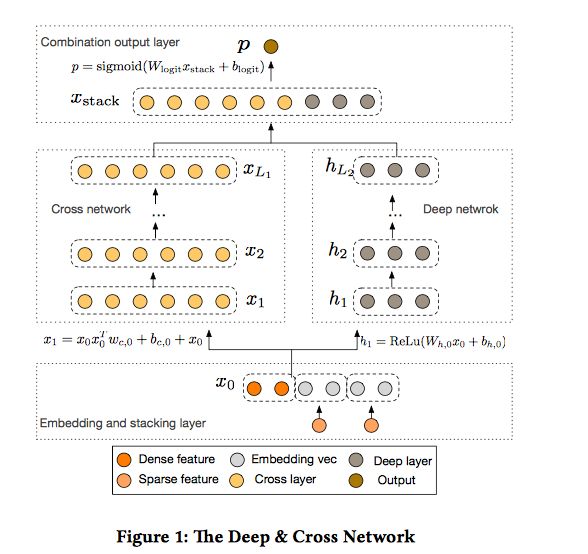
4.1.3 Deep Cross Network
一个DCN模型从嵌入和堆积层开始,接着是一个交叉网络和一个与之平行的深度网络,之后是最后的组合层,它结合了两个网络的输出。完整的网络模型如图:
嵌入和堆叠层
我们考虑具有离散和连续特征的输入数据。在网络规模推荐系统中,如CTR预测,输入主要是分类特征,如“country=usa”。这些特征通常是编码为独热向量如“[ 0,1,0 ]”;然而,这往往导致过度的高维特征空间大的词汇。
为了减少维数,我们采用嵌入过程将这些离散特征转换成实数值的稠密向量(通常称为嵌入向量):
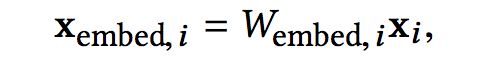
然后,我们将嵌入向量与连续特征向量叠加起来形成一个向量:
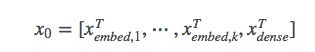
拼接起来的向量X0将作为我们Cross Network和Deep Network的输入
Cross Network
交叉网络的核心思想是以有效的方式应用显式特征交叉。交叉网络由交叉层组成,每个层具有以下公式:
一个交叉层的可视化如图所示:
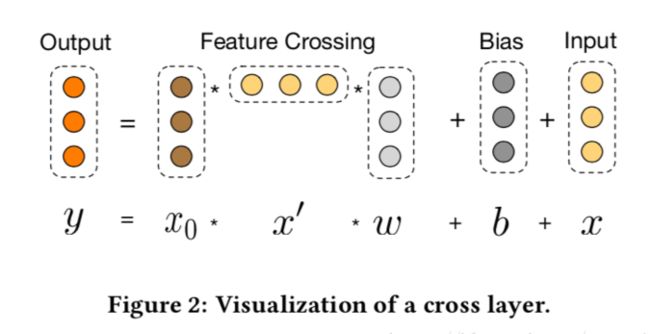
可以看到,交叉网络的特殊结构使交叉特征的程度随着层深度的增加而增大。多项式的最高程度(就输入X0而言)为L层交叉网络L + 1。如果用Lc表示交叉层数,d表示输入维度。然后,参数的数量参与跨网络参数为:d * Lc * 2 (w和b)
交叉网络的少数参数限制了模型容量。为了捕捉高度非线性的相互作用,模型并行地引入了一个深度网络。
Deep Network
深度网络就是一个全连接的前馈神经网络,每个深度层具有如下公式:
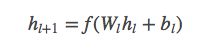
Combination Layer
链接层将两个并行网络的输出连接起来,经过一层全链接层得到输出:

如果采用的是对数损失函数,那么损失函数形式如下:
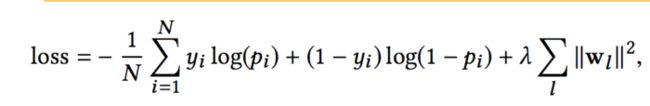
有关DCN的更多细节,参考文章:推荐系统遇上深度学习(五)--Deep&Cross Network模型理论和实践:https://www.jianshu.com/p/77719fc252fa
代码地址:https://github.com/princewen/tensorflow_practice/tree/master/recommendation/Basic-DCN-Demo
4.2 串行结构
4.2.1 Product-based Neural Network
PNN,全称为Product-based Neural Network,认为在embedding输入到MLP之后学习的交叉特征表达并不充分,提出了一种product layer的思想,既基于乘法的运算来体现体征交叉的DNN网络结构,如下图:

我们这里主要来关注一下Product-Layer,product layer可以分成两个部分,一部分是线性部分lz,一部分是非线性部分lp。
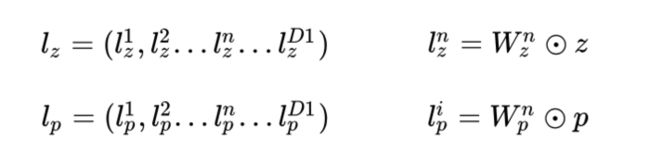
看上面的公式,我们首先需要知道z和p,这都是由我们的embedding层得到的,其中z是线性信号向量,因此我们直接用embedding层得到:

论文中使用的等号加一个三角形,其实就是相等的意思,你可以认为z就是embedding层的复制。
对于p来说,这里需要一个公式进行映射:
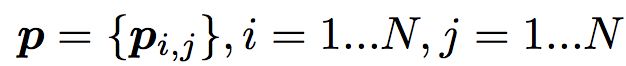
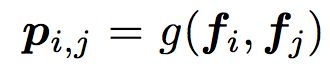
不同的g的选择使得我们有了两种PNN的计算方法,一种叫做Inner PNN,简称IPNN,一种叫做Outer PNN,简称OPNN。
IPNN
IPNN的示意图如下:
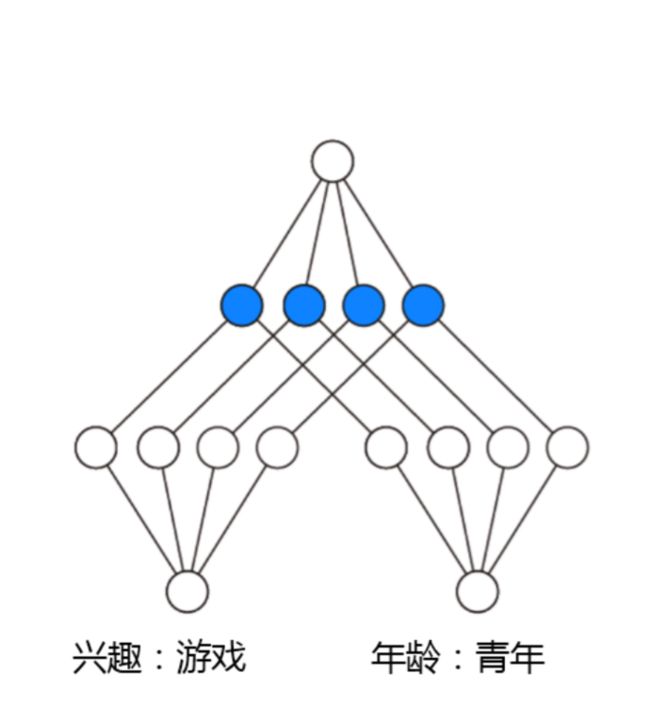
IPNN中p的计算方式如下,即使用内积来代表pij:
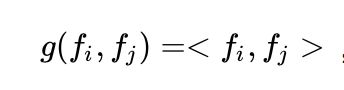
OPNN
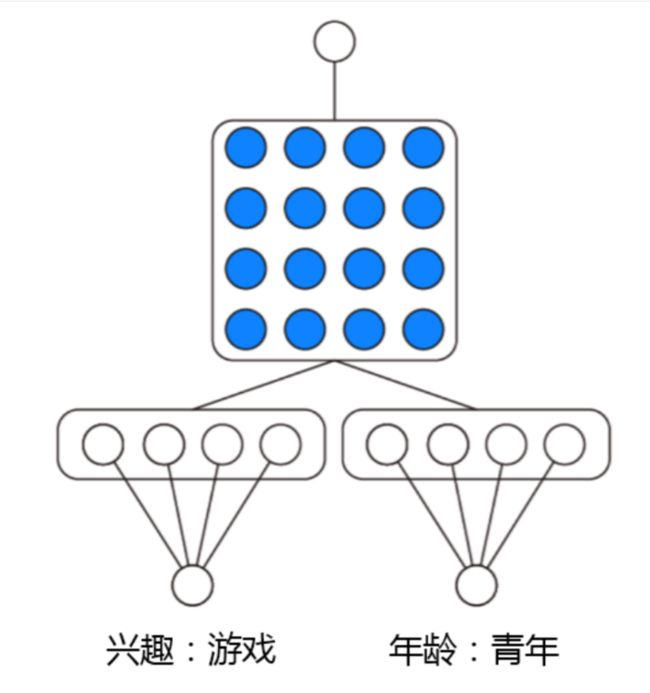
OPNN的示意图如下:
OPNN中p的计算方式如下:
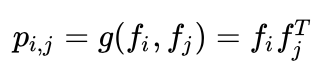
有关PNN的更多细节,参考文章:推荐系统遇上深度学习(六)--PNN模型理论和实践:https://www.jianshu.com/p/be784ab4abc2
代码地址:https://github.com/princewen/tensorflow_practice/tree/master/recommendation/Basic-PNN-Demo
4.2.2 Neural factorization machines
对于NFM模型,目标值的预测公式变为:

其中,f(x)是用来建模特征之间交互关系的多层前馈神经网络模块,架构图如下所示:
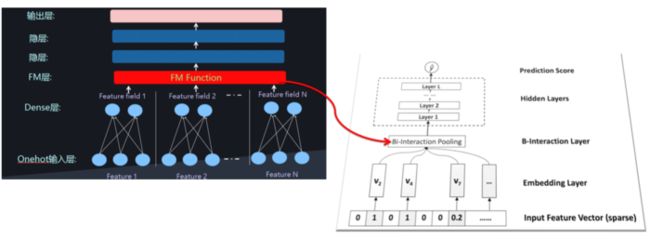
Embedding Layer和我们之间几个网络是一样的,embedding 得到的vector其实就是我们在FM中要学习的隐变量v。
Bi-Interaction Layer名字挺高大上的,其实它就是计算FM中的二次项的过程,因此得到的向量维度就是我们的Embedding的维度。最终的结果是:
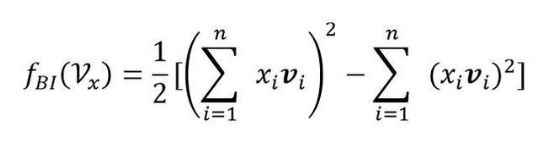
Hidden Layers就是我们的DNN部分,将Bi-Interaction Layer得到的结果接入多层的神经网络进行训练,从而捕捉到特征之间复杂的非线性关系。
在进行多层训练之后,将最后一层的输出求和同时加上一次项和偏置项,就得到了我们的预测输出:
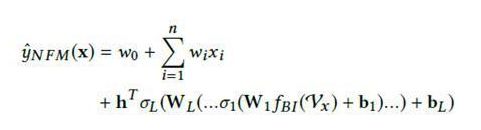
有关NFM的更多细节,参考文章:推荐系统遇上深度学习(七)--NFM模型理论和实践:https://www.jianshu.com/p/4e65723ee632
代码地址:https://github.com/princewen/tensorflow_practice/tree/master/recommendation/Basic-NFM-Demo
4.2.3 Attention-Based factorization machines
在进行预测时,FM会让一个特征固定一个特定的向量,当这个特征与其他特征做交叉时,都是用同样的向量去做计算。这个是很不合理的,因为不同的特征之间的交叉,重要程度是不一样的。如何体现这种重要程度,之前介绍的FFM模型是一个方案。另外,结合了attention机制的AFM模型,也是一种解决方案。
关于什么是attention model?本文不打算详细赘述,我们这里只需要知道的是,attention机制相当于一个加权平均,attention的值就是其中权重,判断不同特征之间交互的重要性。
刚才提到了,attention相等于加权的过程,因此我们的预测公式变为:
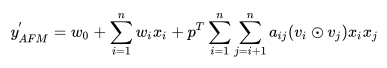
圆圈中有个点的符号代表的含义是element-wise product,即:
因此,我们在求和之后得到的是一个K维的向量,还需要跟一个向量p相乘,得到一个具体的数值。
可以看到,AFM的前两部分和FM相同,后面的一项经由如下的网络得到:

图中的前三部分:sparse iput,embedding layer,pair-wise interaction layer,都和FM是一样的。而后面的两部分,则是AFM的创新所在,也就是我们的Attention net。Attention背后的数学公式如下:

总结一下,不难看出AFM只是在FM的基础上添加了attention的机制,但是实际上,由于最后的加权累加,二次项并没有进行更深的网络去学习非线性交叉特征,所以AFM并没有发挥出DNN的优势,也许结合DNN可以达到更好的结果。
有关AFM的更多细节,参考文章:推荐系统遇上深度学习(八)--AFM模型理论和实践:https://www.jianshu.com/p/83d3b2a1e55d
代码地址:https://github.com/princewen/tensorflow_practice/tree/master/recommendation/Basic-AFM-Demo
5、强化学习方法
在《DRN:A Deep Reinforcement Learning Framework for News Recommendation》提出了一种基于强化学习的新闻推荐模型,一起来回顾一下:
问题及解决方案
本文提出的方法主要针对三个问题:
1、使用DQN来建模用户兴趣的动态变化性
2、推荐算法通常只考虑用户的点击/未点击 或者 用户的评分作为反馈,本文将用户活跃度作为一种反馈信息。
3、目前的推荐系统倾向于推荐用户重复或相似内容的东西,本文使用Dueling Bandit Gradient Descent方法来进行有效的探索。
因此本文的框架如下:

模型整体框架
模型整体框架如下图所示:

有几个关键的环节:
PUSH:在每一个时刻,用户发送请求时,agent根据当前的state产生k篇新闻推荐给用户,这个推荐结果是exploitation和exploration的结合
FEEDBACK:通过用户对推荐新闻的点击行为得到反馈结果。
MINOR UPDATE:在每个时间点过后,根据用户的信息(state)和推荐的新闻(action)及得到的反馈(reward),agent会评估exploitation network Q 和 exploration network Q ̃ 的表现,如果exploitation network Q效果更好,则模型保持不动,如果 exploration network Q ̃ 的表现更好,exploitation network Q的参数将会向exploration network Q ̃变化。
MAJOR UPDATE:在一段时间过后,根据DQN的经验池中存放的历史经验,对exploitation network Q 模型参数进行更新。
强化学习模型
本文的探索模型使用的是Double-Dueling结构,状态由用户特征和上下文特征组成,动作由新闻特征,用户-新闻交互特征组成:
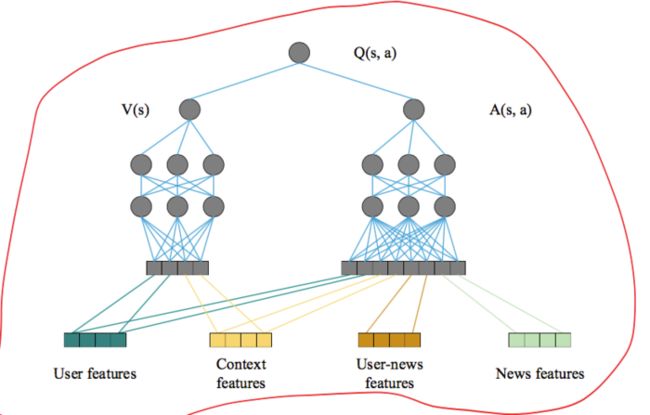
探索模型
本文的探索采取的是Dueling Bandit Gradient Descent 算法,算法的结构如下:
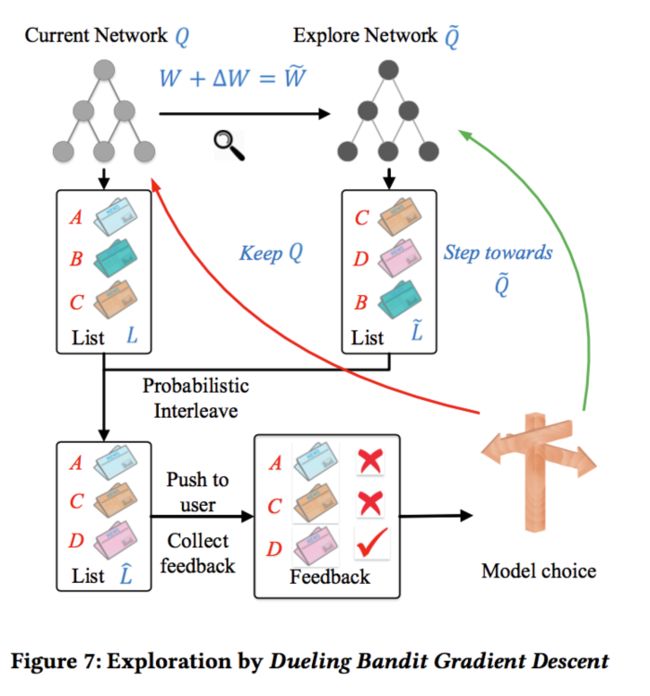
在DQN网络的基础上又多出来一个exploration network Q ̃ ,这个网络的参数是由当前的Q网络参数基础上加入一定的噪声产生的。当一个用户请求到来时,由两个网络同时产生top-K的新闻列表,然后将二者产生的新闻进行一定程度的混合,然后得到用户的反馈。如果exploration network Q ̃的效果好的话,那么当前Q网络的参数向着exploration network Q ̃的参数方向进行更新。
有关本论文的更多细节,参考文章:推荐系统遇上深度学习(十四)--《DRN:A Deep Reinforcement Learning Framework for News Recommendation》:https://www.jianshu.com/p/c0384b213320
6、推荐系统的EE问题
Exploration and Exploitation(EE问题,探索与开发)是计算广告和推荐系统里常见的一个问题,为什么会有EE问题?简单来说,是为了平衡推荐系统的准确性和多样性。
EE问题中的Exploitation就是:对用户比较确定的兴趣,当然要利用开采迎合,好比说已经挣到的钱,当然要花;而exploration就是:光对着用户已知的兴趣使用,用户很快会腻,所以要不断探索用户新的兴趣才行,这就好比虽然有一点钱可以花了,但是还得继续搬砖挣钱,不然花完了就得喝西北风。
6.1 Bandit算法
Bandit算法是解决EE问题的一种有效算法,Bandit算法来源于历史悠久的赌博学,它要解决的问题是这样的:一个赌徒,要去摇老虎机,走进赌场一看,一排老虎机,外表一模一样,但是每个老虎机吐钱的概率可不一样,他不知道每个老虎机吐钱的概率分布是什么,那么每次该选择哪个老虎机可以做到最大化收益呢?这就是多臂赌博机问题(Multi-armed bandit problem, K-armed bandit problem, MAB)。
Bandit算法如何同推荐系统中的EE问题联系起来呢?假设我们已经经过一些试验,得到了当前每个老虎机的吐钱的概率,如果想要获得最大的收益,我们会一直摇哪个吐钱概率最高的老虎机,这就是Exploitation。但是,当前获得的信息并不是老虎机吐钱的真实概率,可能还有更好的老虎机吐钱概率更高,因此还需要进一步探索,这就是Exploration问题。
下面介绍几种经典的Bandit算法:
朴素Bandit算法:先随机试若干次,计算每个臂的平均收益,一直选均值最大那个臂。
Epsilon-Greedy算法:选一个(0,1)之间较小的数epsilon,每次以epsilon的概率在所有臂中随机选一个。以1-epsilon的概率选择截止当前,平均收益最大的那个臂。根据选择臂的回报值来对回报期望进行更新。
Thompson sampling算法:Thompson sampling算法用到了Beta分布,该方法假设每个老虎机都有一个吐钱的概率p,同时该概率p的概率分布符合beta(wins, lose)分布,每个臂都维护一个beta分布的参数,即wins, lose。每次试验后,选中一个臂,摇一下,有收益则该臂的wins增加1,否则该臂的lose增加1。每次选择臂的方式是:用每个臂现有的beta分布产生一个随机数b,选择所有臂产生的随机数中最大的那个臂去摇。
UCB算法:该算法在每次推荐时,总是乐观的认为每个老虎机能够得到的收益是p' + ∆。p' + ∆的计算公式如下:

其中加号前面是第j个老虎机到目前的收益均值,后面的叫做bonus,本质上是均值的标准差,T是目前的试验次数,n是该老虎机被试次数。
有关EE问题的更多细节,参考文章:推荐系统遇上深度学习(十二)--推荐系统中的EE问题及基本Bandit算法:https://www.jianshu.com/p/95b2de50ce44
6.2 LinUCB算法
上面提到的MAB都是context-free,即没有考虑到用户的个性化问题,因此实际中很少应用。现实中我们大都采用考虑上下文的Contextual Bandit算法。LinUCB便是其中之一。
既然是UCB算法的扩展,那我们还是根据p' + ∆来选择合适的老虎机。p'的计算基于有监督的学习方法。我们为每个老虎机维护一个特征向量D,同时上下文特征我们写作θ,然后通过收集的反馈进行有监督学习:

而置信上界基于下面的公式进行计算:

因此LinUCB算法的流程如下:

有关LinUCB的更多细节,参考文章:推荐系统遇上深度学习(十三)--linUCB方法浅析及实现:https://www.jianshu.com/p/e0e843d78e3c
代码地址:https://github.com/princewen/tensorflow_practice/tree/master/recommendation/Basic-Bandit-Demo
7、推荐系统在公司中的实战
7.1 阿里MLR算法
MLR可以看做是对LR的一个自然推广,它采用分而治之的思路,用分片线性的模式来拟合高维空间的非线性分类面,其形式化表达如下:
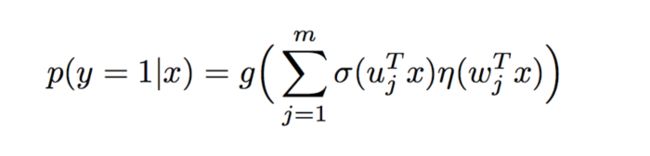
其中u是聚类参数,决定了空间的划分,w是分类参数,决定空间内的预测。这里面超参数分片数m可以较好地平衡模型的拟合与推广能力。当m=1时MLR就退化为普通的LR,m越大模型的拟合能力越强,但是模型参数规模随m线性增长,相应所需的训练样本也随之增长。因此实际应用中m需要根据实际情况进行选择。例如,在阿里的场景中,m一般选择为12。下图中MLR模型用4个分片可以完美地拟合出数据中的菱形分类面。

在实际中,MLR算法常用的形式如下,使用softmax作为分片函数:
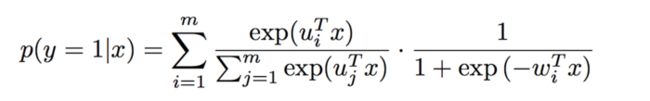
在这种情况下,MLR模型可以看作是一个FOE model:

关于损失函数的设计,阿里采用了 neg-likelihood loss function以及L1,L2正则,形式如下:
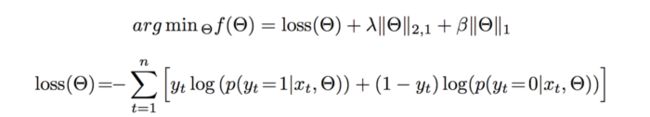
由于加入了正则项,MLR算法变的不再是平滑的凸函数,梯度下降法不再适用,因此模型参数的更新使用LBFGS和OWLQN的结合,具体的优化细节大家可以参考论文https://arxiv.org/pdf/1704.05194.pdf.
有关MLR的更多细节,参考文章:推荐系统遇上深度学习(十七)--探秘阿里之MLR算法浅析及实现:https://www.jianshu.com/p/627fc0d755b2
代码地址:https://github.com/princewen/tensorflow_practice/tree/master/recommendation/Basic-MLR-Demo
7.2 阿里Deep Interest Network
阿里的研究者们通过观察收集到的线上数据,发现了用户行为数据中有两个很重要的特性:
Diversity:用户在浏览电商网站的过程中显示出的兴趣是十分多样性的。
Local activation: 由于用户兴趣的多样性,只有部分历史数据会影响到当次推荐的物品是否被点击,而不是所有的历史记录。
针对上面的两种特性,阿里在推荐网络中增加了一个Attention机制,对用户的历史行为进行加权:
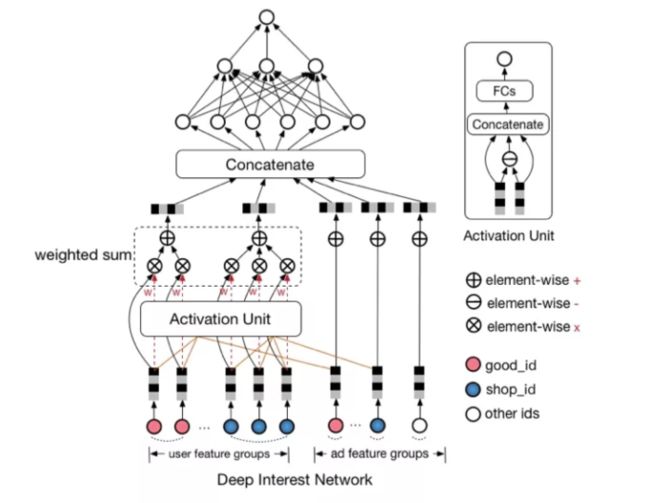
还有两个值得注意的细节:
评价指标GAUC
模型使用的评价指标是GAUC,我们先来看一下GAUC的计算公式:
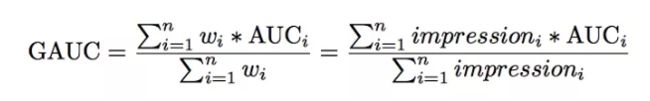
GAUC的计算,不仅将每个用户的AUC分开计算,同时根据用户的展示数或者点击数来对每个用户的AUC进行加权处理。进一步消除了用户偏差对模型的影响。通过实验证明,GAUC确实是一个更加合理的评价指标。
Dice激活函数
使用PRelu作为激活函数时,存在一个问题,即我们认为分割点都是0,但实际上,分割点应该由数据决定,因此文中提出了Dice激活函数。
Dice激活函数的全称是Data Dependent Activation Function,形式如下:
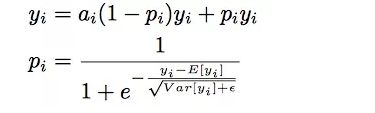
其中,期望和方差的计算如下:

可也看到,每一个yi对应了一个概率值pi。pi的计算主要分为两步:将yi进行标准化和进行sigmoid变换。
自适应正则 Adaptive Regularization
针对用户数据中的长尾情况,阿里提出了自适应正则的做法,即:
1.针对feature id出现的频率,来自适应的调整他们正则化的强度;
2.对于出现频率高的,给与较小的正则化强度;
3.对于出现频率低的,给予较大的正则化强度。
计算公式如下:
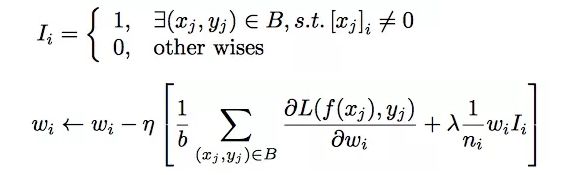
有关DIN的更多细节,参考文章:推荐系统遇上深度学习(十八)--探秘阿里之深度兴趣网络(DIN)浅析及实现:https://www.jianshu.com/p/73b6f5d00f46
7.3 阿里ESSM模型
该模型主要解决的是CVR预估中的两个主要问题:样本选择偏差和稀疏数据。
样本选择偏差:大多数CVR预估问题是在用户点击过的样本空间上进行训练的,而预测的时候却要对整个样本空间的样本进行预测。这种训练样本从整体样本空间的一个较小子集中提取,而训练得到的模型却需要对整个样本空间中的样本做推断预测的现象称之为样本选择偏差。
数据稀疏:用户点击过的物品只占整个样本空间的很小一部分,使得模型训练十分困难。
阿里妈妈的算法同学提出的ESMM模型借鉴了多任务学习的思路,引入了两个辅助的学习任务,分别用来拟合pCTR和pCTCVR,从而同时消除了上文提到的两个挑战。ESMM模型能够充分利用用户行为的顺序性模式,其模型架构下图所示:
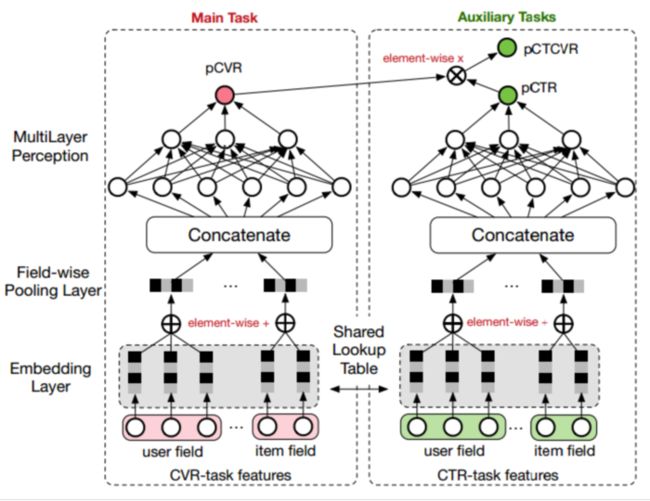
可以看到,ESSM模型由两个子网络组成,左边的子网络用来拟合pCVR,右边的子网络用来拟合pCTR,同时,两个子网络的输出相乘之后可以得到pCTCVR。因此,该网络结构共有三个子任务,分别用于输出pCTR、pCVR和pCTCVR。
假设我们用x表示feature(即impression),y表示点击,z表示转化,那么根据pCTCVR = pCTR * pCVR,可以得到:

将乘法转化为除法,我们可以得到pCVR的计算:
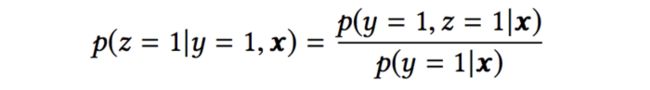
我们将有点击行为的曝光事件作为正样本,没有点击行为的曝光事件作为负样本,来做CTR预估的任务。将同时有点击行为和购买行为的曝光事件作为正样本,其他作为负样本来训练CTCVR的预估部分。
模型具体是怎么做的呢?可以看到,用来训练两个任务的输入x其实是相同的,但是label是不同的。CTR任务预估的是点击y,CTCVR预估的是转化z。因此,我们将(x,y)输入到CTR任务中,得到CTR的预估值,将(x,z)输入到CVR任务中,得到CVR的预估值,CTR和CVR的预估值相乘,便得到了CTCVR的预估值。因此,模型的损失函数可以定义为:
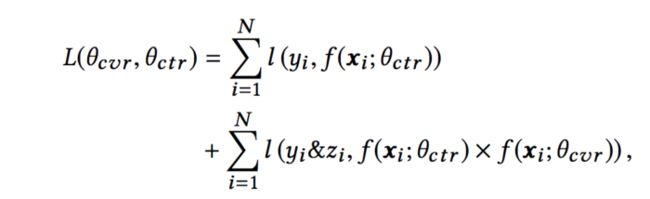
其中,θctr和θcvr分别是CTR网络和CVR网络的参数,l(⋅)是交叉熵损失函数。
同时,还需要提醒的一点是,两个子网络的embedding层共享embedding向量。
有关ESSM模型的更多细节,参考文章:推荐系统遇上深度学习(十九)--探秘阿里之完整空间多任务模型ESSM:https://www.jianshu.com/p/35f00299c059
7.4 京东强化学习推荐模型
京东通过强化学习来进行 List-wise 的推荐。
构建线上环境仿真器
在推荐系统上线之前,需要进行线下的训练和评估,训练和评估主要基于用户的历史行为数据,但是,我们只有ground-truth的数据和相应的反馈。因此,对于整个动作空间来说(也就是所有物品的可能组合),这是非常稀疏的。这会造成两个问题,首先只能拿到部分的state-action对进行训练,无法对所有的情况进行建模(可能造成过拟合),其次会造成线上线下环境的不一致性。因此,需要一个仿真器来仿真没有出现过的state-action的reward值,用于训练和评估线下模型。
仿真器的构建主要基于用户的历史数据,其基本思想是给定一个相似的state和action,不同的用户也会作出相似的feedback。来建模state-action的reward值。
模型结构
该模型通过Actor-Critic方法,结合刚才建立的仿真器,进行训练:

有关该方法的具体细节,参考文章:推荐系统遇上深度学习(十五)--强化学习在京东推荐中的探索:https://www.jianshu.com/p/b9113332e33e
9、论文整理
1、GBDT+LR:http://quinonero.net/Publications/predicting-clicks-facebook.pdf
2、DeepFM:https://arxiv.org/abs/1703.04247
3、Wide&Deep:https://dl.acm.org/citation.cfm?id=2988454
4、DCN:https://arxiv.org/pdf/1708.05123
5、PNN:https://arxiv.org/pdf/1611.00144
6、AFM:https://www.comp.nus.edu.sg/~xiangnan/papers/ijcai17-afm.pdf
7、NFM:https://arxiv.org/abs/1708.05027
8、LinUCB:https://arxiv.org/pdf/1003.0146.pdf
9、MLR:https://arxiv.org/pdf/1704.05194.pdf
10、DIN:https://arxiv.org/abs/1706.06978
11、ESSM:https://arxiv.org/abs/1804.07931
12、京东:https://arxiv.org/abs/1801.00209
欢迎关注个人公众号:小小挖掘机

添加微信sxw2251,可以拉你进入小小挖掘机技术交流群哟!