这一节,讲的是已知样例标签y的分布(比如伯努利分布,高斯分布)是指数族中的一员,怎么利用运用GLM生成假设h(x)的公式(比如h(x)=θx)。
一、伯努利分布,二项分布,多项式分布
受到维基的启发,这里用n(进行实验的次数)和k(实验的结果的个数)来区分伯努利分布,二项分布和多项式分布
1、伯努利分布(n=1,k=2,随机变量X==>事件A发生)
进行1次实验,实验只有2个结果且结果互斥,用X来表示事件A发生,事件A发生的概率为φ,(即分布律为 ; X=1,p = Φ;X=0,p=1-Φ),可以写成
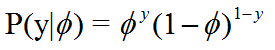
那么就说 随机变量X服从伯努利分布
举个栗子:投一次硬币,X表示“结果为正面”,P(X=1)表示的是结果为正面的概率。
2、二项分布(n>1,k=2,随机变量X==>事件A发生的次数)
进行n次实验,同样每次实验只有2个结果,用X来表示事件A发生的次数,事件A发生的概率为φ,如果
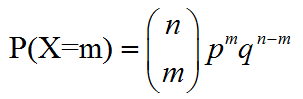
那么就说,随机变量X服从二项分布(即事件A发生m次的概率为P(x=m))
并且X的所有可能情况(X发生m₁,m₂,m₃...次,m和为n)概率之和为1
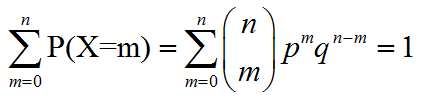
举个栗子:投n次硬币,每次可能出现两种结果,则X代表的是“结果为正面的次数”,P(X=m)表示n次实验中,有m结果为正面的概率。
3、多项式分布(n>1,k>1,随机向量X=(x1=n1,x2 = n2,...xk=nk))
注意改变,实验结果不再是两个而是多个,X不再是一个单值变量而是一个向量,元素xi=ni的意思是,事件xi发生了ni次,并且n1+n2+...+nk = n
进行n次实验,每次实验有k个结果,且结果互斥。则结果x1发生了n1次,且x1发生1次的概率为p1,x2发生了n2次,x2发生1次的概率为p2。。。即若满足

另一种形式为

那么就说,随机向量X=(x1=n1,x2 = n2,...xk=nk)满足多项式分布。
(注意其中每个事件发生m次的分布律可能都不相同)
举个栗子:掷骰子,六个点数出现的概率都不一样。掷n次,每次可能会出现6种不同的结果,用x1代表结果为点数一朝上1,p1代表点数1朝上的概率。依次类推。
此时,如果问有m次都是点数6朝上的概率,那么可以表示为x6=m的概率:
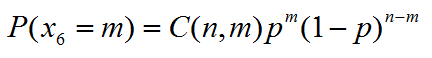
那么也就相当于上面的二项分布,其中p是点数为6的概率,(1-p)是点数不为6的概率。
但是这不是多项式分布的问题,多项式分布的问题是:点数1 ~ 6的出现次数分别为(n1,n2,n3,n4,n5,n6)时的概率是多少(公式里面的结果不再是两个,而是多个)?(其中sum(n1 ~ n6)= n)
此时X=(x1=n1,x2 = n2,...xk=nk)才是服从多项式分布的。
注意,多项式分布中各结果也是互斥的
再举个栗子,
比如邮件分类问题,有一种表示邮件的方法:假设字典中有50000个单词,那么令x为一个50000维的向量,这个邮件中有buy单词,在字典的第k个位置,那么x的第k个元素就为1。单词未出现,则该位置的元素为0。
则不同的邮件,可以表示成x₁=(1,1,0,0,...,1,1,1),x₂=(0,0,0,0,...,1,1,1),所以共有250000个结果。且每个结果互斥。
套到多项式分布上来,也就是,进行n次实验,每次实验可能发生250000个结果,用x₁表示第一种结果,p1 表示第一种结果发生的概率,以此类推, 用随即向量X=(x1=n1,x2 = n2,...xk=nk)表示n次实验中,每个结果出现的次数分别为n1,n2,...的情况,那么随机向量X也服从多项式分布。
二、指数族(The exponential family)
在学习GLMs之前,先定义一种指数族分布:若是有一类分布可以写成下面这种形式的,就说这个分布属于指数族分布。
其中,T(y)一般等于y,η被叫做自然参数(natural parameter)。其余的一些参数理解不深,这里就不介绍了。
一些常见的分布,比如伯努利分布,高斯分布,都可以写成上面的形式,只不过是相应的a,b,T不相同。
比如,我们可以把伯努利分布写成:
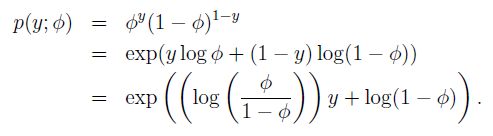
即伯努利分布可以写成指数族形式,可以看出其中对应的T,a,b分别为

再写高斯分布,回忆一下,当我们得到线性回归时,方差σ²的值对最终的假设h没有影响,所以为了方便,我们将σ²设置为1. 于是我们可以得到
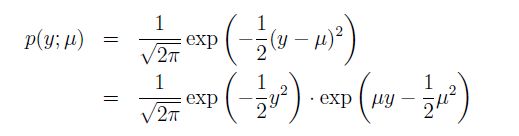
其中,对应的指数族的参数分别为

除了这些,还有很多指数族分布的成员:多项式分布,泊松分布,gamma分布,指数分布,beta分布,dirichlet分布等等。
如果给定x和θ,且已知y服从这些分布中的某一个分布,那么我们就可以根据下面的规则,来为预测y的假设h(x)建模。
目标函数 不等于 预测模型!
目标函数是一个挺复杂的概念,简单地说,就是我们需要去优化的函数,要结合模型复杂度,结构风险最小化等。
而模型就是根据输入x和学习好的参数θ去预测输出y的模型。
比如,已经介绍了的逻辑回归中的目标函数可以理解为最大似然函数L(θ),而预测模型是sigmoid函数g(z)。
而这节主要讲的,就是如何根据y的分布,来建立预测y的等式。
至于目标函数,是和你自己所需要达到的目标来设定的。
三、 建立一般线性模型
1、三个假设
已知y分布,为了得到GLM,假设我们的模型对于给定输入x 情况下y的条件分布即p(y|x)满足下面三个条件:
- 1 y|x;θ~ExponentialFamily(η),即,给定x和θ,在参数η的情况下,y的分布服从于指数族分布中的一个分布。
- 2 h(x) = E[y|x;θ].即,给定x以后我们想要预测T(y)的期望值(不是很理解),而一般情况下T(y) = y,所以二者期望值相等。对于假设h(x),一般情况下,h(x) 即为y的期望即h(x) = E[y|x],所以假设E[T(y)] = E[y|x]=h(x).
- 3 η=θTx,即z自然参数η和输入x线性相关.
2、普通最小二乘法(y服从高斯分布)
直接上假设的推导
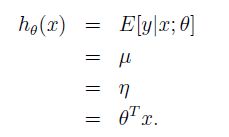
- y服从高斯分布,可以用GLM方法来对预测进行建模
2.假设给定x,y|x;θ~N(μ,σ²),---假设1,解释第二行期望值为μ
3.假设2,得h(x) = E[y|x;θ]
4.由上一节指数族中,已知,把高斯分布写成指数族的形式以后会得到自然参数η=μ
5.假设3,得到η=θTx。
至此,得到y服从高斯分布时的预测模型h(x)的表示。其中比较重要的是第4步,需要把y服从的分布写成指数族的形式。
3、逻辑回归(y服从伯努利分布)
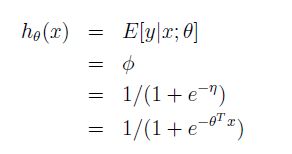
y服从伯努利分布==>
假设1==>y|x;θ~Bernoulli(φ)==>
假设2==>h(x) = E[y|x;θ]==>
E[y|x;θ]=φ==>
伯努利分布的指数族形式得到第三行==>
假设3==>第四行
4、Softmax Regression
在多分类问题中,如果标签y有k个值,即y属于{1,2,3...,k}。我们可以根据多项式分布来对这种问题进行建模。
a、首先,需要解释一下多项式分布也属于指数族。
首先,假设共有k个结果,每个结果对应的概率为φ₁,φ₂,...φk。然而,这k个结果并不是互相独立的(受限制于和为1,多项式分布的性质)。并不清楚为什么非要独立
因此,我们只有k-1个参数来描述多项式分布,即φ₁,φ₂,...φk-1,这里φi = p(y=i;φ),而p(y=k;φ) = 1-sigma(φi)。需要注意的是,φk并此时并不是参数,而是有其余k-1个参数确定的常量。

其中,T(y)和y的关系是。(T(y))i = 1{y=i}。于是有 p(y=i;φ) = φi = E[(T(y))i]。
一旦y等于1,那么y就不再为别的数。比如,y被判为垃圾邮件,那么绝不是公司邮件或者私人信件。
这么表达是为了方便理解,在把多项式分布转化为指数族时,T(y)是一个向量,元素为(T(y))i = 1{y=i}。提前将多项式分布和指数族连接了起来。
上面这个公式的意思,是y=1时, p(y=1;φ) = φ1,也就是y的分布律,y服从这个分布(但我认为,这并不是精确的多项式分布的公式,毕竟此时只有k-1个参数)。
将此时y的分布推导出指数族的形式

于是可以知道
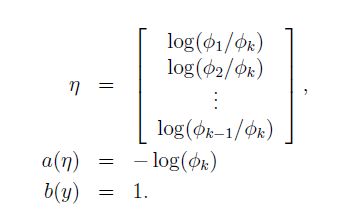
这样也算推出了,多项式分布也是 指数族分布的一员。
连接二者(用φ和η连接多项式分布与指数族分布)的函数为
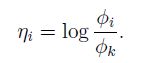
通过上面式子的转化,可以得到下面
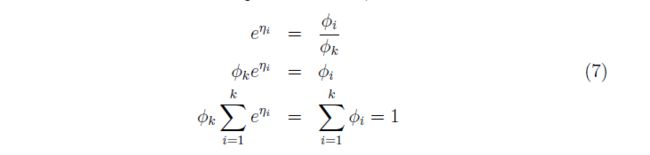
通过公式7,我们可以得到用η表示φ的公式
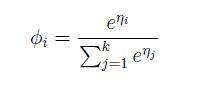
于是,一般情况下,在我们并不知道φi的情况下,可以用GLM假设中的第3个假设,推出预测y=i的概率

这也就是平时经常见到的,预测概率的公式。
此时,我们的模型可以根据GLM得到
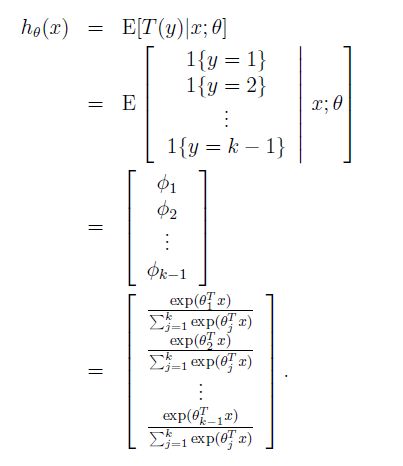
也就是说,我们的假设,就是输出对每个结果预测的概率。
这就是softmax regression中的假设模型了。
最后,类似于在线性最小二乘和逻辑回归里的目标函数,我们用log-似然函数来作为目标函数,用来学习参数θ。
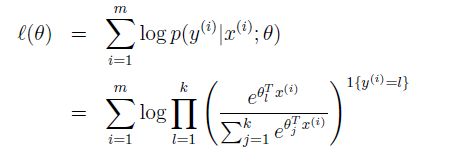
再通过优化方法,得到最终需要学习的参数。以上就是softmax regression的由来的介绍。
大致梳理一下就是,y服从多项式分布,于是用GLM来建模,得到假设的模型。
而因为模型输出的是概率,所以采用极大似然的方法来学习参数。
介绍的并不清楚,因为我有一些不懂得地方。。。