在经典的C/S架构的网络模型中,都是通过Socket编程来完成服务器与客户端之间数据的交互。
例如:Python中使用Socket编写客户端
$ vim client.py
#! /usr/bin/python3
# encoding=utf-8
import socket
from time import ctime
HOST = "127.0.01"
PORT = 9000
ADDR = (HOST, PORT)
BUFSIZE = 1024
MAX_CONNECT = 3
# 创建Socket对象
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 将Socket绑定到指定地址的端口上
sock.bind(ADDR)
# 监听客户端连接并设置最大连接数限制
sock.listen(MAX_CONNECT)
# 事件循环
while True:
# 获取新Socket对象和绑定地址
pip, addr = sock.accept()
while True:
# 接收数据
data = pip.recv(BUFSIZE)
# 当不再接收到数据时关闭本次连接
if not data:
break
# 发送数据
pip.send("[%s] %s" % (ctime(), data))
# 关闭连接
pip.close()
# 关闭客户端socket
sock.close()
$ python3 client.py
首先创建客户端Socket对象,并将其绑定到指定地址的端口,注意listen(MAX_CONNECT)中MAX_CONNECT表示最大连接数。在while循环中通过accept()获取新的Socket对象与绑定地址,该Socket对象可以进行数据的收发操作。当不再接收数据时会关闭本次连接。

Socket通讯中存在两个问题
- 连接过程中存在着阻塞
- 当一个连接尚未处理完毕,是无法处理下一个连接的。
为什么会出现这两个问题呢?
- Socket缓冲区和阻塞模式
Socket通信过程中无论是读read()还是写write()都不是直接从网络中读取或是写入网络的。其大致流程是先从网卡到内核,再由内核写入内核缓冲区,最后Socket会从内核缓冲区拷贝到用户进程中读取数据。
什么是缓冲区呢?
每当一个Socket被创建之后都会分配两个缓冲区:输入缓冲区 、输出缓冲区

I/O缓冲区特性
- I/O缓冲区在每个TCP Socket中单独存在
- I/O缓冲区在从创建Socket时自动生成
- 即使关闭Socket也会继续传送输出缓冲区中遗留的数据
- 关闭Socket将会丢失输入缓冲区中的数据
什么是I/O阻塞呢?
当用户进程发起recvform()系统调用时,系统首先会检查是否有准备好的数据,如果发现系统还没有准备好数据,I/O缓冲区没有可以可读的数据,那此时当前线程就会阻塞(Blocking),直到数据拷贝到用户进程中或有错误发生时才会返回。简单来说,I/O阻塞是指recvformI/O系统调用时用户进程主动的等待系统调用返回结果。

Tornado是如何解决I/O阻塞这个问题的呢?
由于I/O阻塞主要发生在从发出系统调用到内核缓冲区准备好数据这段时间内,那么发出系统调用之后,用户进程可不可以不进入睡眠状态呢?
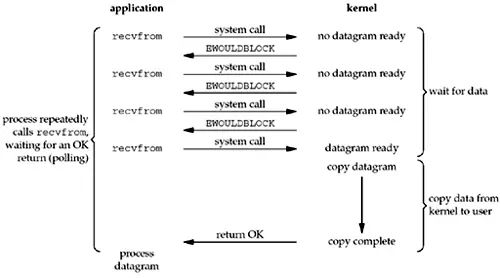
方案1:轮询 - I/O同步非阻塞模型
能不能在发起recvform系统调用之后不阻塞进程,而采用轮询的方式,不断调用recvform系统调用,如果数据还没有准备好就返回一个EWOULDBLOCK错误,直到内核缓存区准备好该有的数据后,再返回一个成功的调用。
这样与之前的阻塞模型相比,用户进程不会被I/O调用所阻塞,每次调用都会立即返回结果,这也就是另外一种I/O模型 - I/O同步非阻塞模型。
I/O同步非阻塞模型的缺点非常明显,它会把CPU浪费在轮询的工作上面。
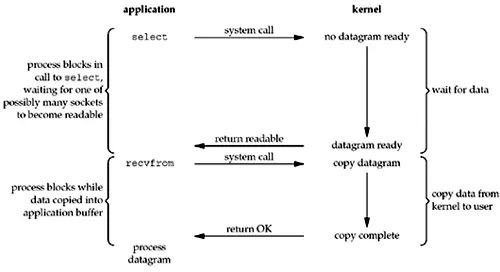
方案2:select、poll、epoll - I/O多路复用模型
select
Select出现于1983年的BSD4.2中,原理是通过调用select函数来监视多个文件描述符fd的数组,当select方法返回之后,数组中就绪的文件描述符会被内核修改标志位,使进程可以 获得文件描述符来进行后续操作。
可以通Select作为代理管理所创建的Socket,当内核缓冲区的数据准备好的时候,再发起recvform系统调用,这样就可以避开I/O调用的阻塞。
Select解决方案对应的I/O模型也就是 - I/O多路复用模型(I/O Multiplexing Model)
虽然Select可以支持几乎所有的平台,但Select的缺点也是显而易见的:
单个进程能够监视的文件描述符
fd的数量存在最大限制,在Linux上一般为1024个,可通过修改宏定义甚至重新编写内核的方式提升这个限制。Select所维护的存储大量文件描述符
fd的数据结构,随着文件描述符数量的增加,复制操作的开销也随着线性增加。同时,由于网络响应时间的延迟使大量TCP连接处于非活跃状态,但是调用select()会对所有Socket进行一次线性扫描,所以这也浪费了一定的开销。
poll
基于以上缺点,在1986年的System V Release 3中诞生了poll,然而poll只是该改进了最大文件描述符的数量限制,从原来的1024放开到理论上的无限个,但对于第二个缺陷仍然没有很好的解决方案。
epoll
epoll在是Linux内核的2.6中提出的,是之前select和poll的增强版本,相对于select和poll来说,epoll更加灵活,没有文件描述符的限制 。epoll使用一个文件内描述符管理多个文件描述符,并将用户关系的文件描述符的事件放入到内核的一个事件表中,这样在用户空间和内核空间的复制copy只需一次。
Tornado的实现参考了epoll,相当于 Tornado的非阻塞的实现就是基于epoll实现的。
select、poll、epoll三者之间对比的异同点
- 支持一个进程所能打开的最大连接数
-
select单个进程所能打开的最大连接数是FD_SETSIZE宏定义,大小是32个整数的大小,在32位及其上大小为32x32,在64位机器上FD_SETSIZE为64x32。可对其进行修改,然后重新编译内核,但性能可能会受到影响。 -
pollpoll本质上和select并没有区别,只是poll没有最大连接数的限制,原因是因为poll是基于链表来存储的。 -
epollepoll虽然连接数有上限但却很大,如1GB内存的机器上可以打开10w左右的连接,2GB内存的 机器可以打开20w左右的连接。
- 文件描述符
fd剧增后带来的I/O效率问题
-
select由于每次调用时都会对连接进行线性遍历,所以随着文件描述符的增减会造成遍历速度慢的线性下降性能问题。 -
poll同select相同 -
epoll由于epoll内核中实现是根据每个文件描述符的回调函数来实现的,只有活跃的Socket才会主动调用回调函数,所以在活跃Socket较少的情况下,使用epoll没有前面两者线性下降的性能问题,但是所有Socket都很活跃的情况下,仍然可能存在性能问题。
- 消息传递方式
-
select内核需要将消息传递到用户空间,都需要内核拷贝动作。 -
poll与select相同 -
epoll通过内核和用户空间共享一块内存来实现
例如:使用Tornado实现简单的Socket TCP服务器
$ vim server.py
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from tornado.options import define, options
from tornado.tcpserver import TCPServer
from tornado.ioloop import IOLoop
define("port", type=int, default=8000)
class Connection(object):
clients = set()
def __init__(self, stream, address):
Connection.clients.add(self)
self._stream = stream
self._address = address
self._stream.set_close_callback(self.on_close)
self.read_message()
def read_message(self):
self._stream.read_until("\n", self.broadcast_messages)
def broadcast_messages(self, message):
print(message)
for conn in Connection.clients:
conn.send_message(message)
self.read_message()
def send_message(self, message):
print(message)
self._stream.write(message)
def on_close(self):
Connection.clients.remove(self)
class Server(TCPServer):
def handle_stream(self, stream, address):
Connection(stream, address)
def main():
server = Server()
server.listen(options.port)
IOLoop.instance().start()
if __name__ == "__main__":
main()
$ vim client.py
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import socket, time
HOST = "127.0.0.1"
PORT = 8000
sdf = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sdf.connect((HOST, PORT))
sdf.sendall(bytes("hello world\n", encoding="utf-8"))
time.sleep(3)
sdf.sendall(bytes("thanks\n", encoding="utf-8"))
data = sdf.recv(1024)
print(data)
message = str(data, encoding="utf-8")
print(message)
sdf.close()
服务器运行错误WARNING:tornado.general:error on read: '>=' not supported between instances of 'int' and 'method'