感知机是什么?
感知机 (perceptron):感知机是神经网络(深度学习)的起源算法,学习感知机的构造是通向神经网络和深度学习的一种重要思想。
严格讲,应该称为“人工神经元”或“朴素感知机”,但是因为很多基本的处理都是共通的,所以这里就简单地称为“感知机”。
感知机接收多个输入信号,输出一个信号。
这里所说的“信号”可以想 象成电流或河流那样具备“流动性”的东西。
像电流流过导线,向前方输送 电子一样,感知机的信号也会形成流,向前方输送信息。
但是,和实际的电 流不同的是,感知机的信号只有“流/不流”(1/0)两种取值。
0 对应“不传递信号”,1对应“传递信号”。
x 1 、x 2 是输入信号,
y 是输出信号,
w 1 、w 2 是权重 (w 是 weight 的首字母)。
图中的○称为“神 经元”或者“节点”。

输入信号被送往神经元时,会被分别乘以固定的权重(w 1 x 1 、w 2 x 2 )。
神经元会计算传送过来的信号的总和,只有当这个总和超过 了某个界限值时,才会输出1。
这也称为“神经元被激活”。这里将这个界限值称为阈值,用符号θ表示。
公式一:
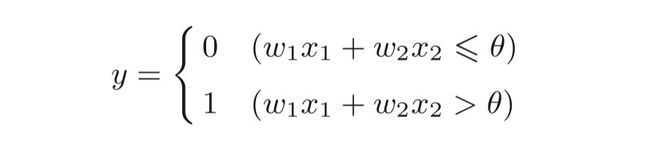
感知机的多个输入信号都有各自固有的权重,这些权重发挥着控制各个 信号的重要性的作用。也就是说,权重越大,对应该权重的信号的重要性就越高。
权重:相当于电流里的电阻。电阻是决定电流流动难度的参数, 电阻越低,通过的电流就越大。
而感知机的权重则是值越大,通过的信号就越大。
不管是电阻还是权重,在控制信号流动难度(或者流 动容易度)这一点上的作用都是一样的。
简单的逻辑电路
与门(and)
与门是有两个输入和一个输出的门电路。
这种输入信号和输出信号的对应表称为“真值表”。与门仅在 两个输入均为1时输出1,其他时候则输出0。

使用感知机来表示这个与门。我们需要做的就是确定能满足真值表的w 1 、w 2 、θ的值。
满足真值表条件的参数的选择方法有无数多个。
比如满足与门的条件如:
(w 1 , w 2 , θ) = (0.5, 0.5, 0.7) # 0.5+ 0.5 超过 0.7 这个界限值(阈值用符号θ表示),满足与门条件。
(w 1 , w 2 , θ) = (0.5, 0.5, 0.8)
(w 1 , w 2 , θ) = (1.0, 1.0, 1.0) # 1 + 1 超过 1 这个界限值(阈值用符号θ表示),满足与门条件。
设定这样的 参数后,仅当x 1 和x 2 同时为1时,信号的加权总和才会超过给定的阈值θ。
与非门(NAND)
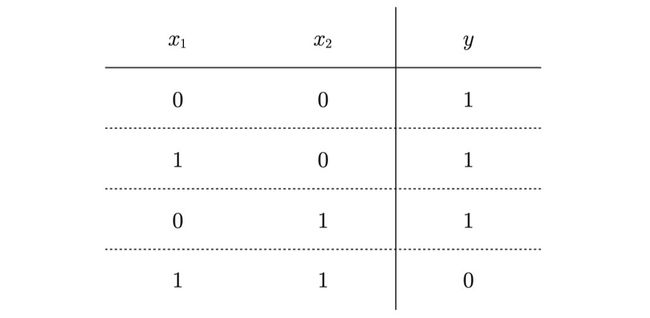
NAND是Not AND的意思,与非门就是颠倒了与门的输出。
用真值表表示的话, 仅当x 1 和x 2 同时为1时输出0,其他时候则输出1。
要表示与非门,可以用 (w 1 , w 2 , θ) = (−0.5, −0.5, −0.7) 这样的组合(其 他的组合也是无限存在的)。
实际上,只要把实现与门的参数值的符号取反, 就可以实现与非门。
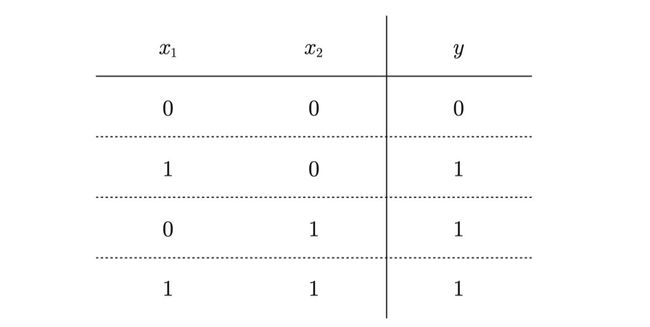
或门(or)
或门是“只要有一个输入信号是1,输 出就为1”的逻辑电路。
感知机可以表示与门、与非门、或门的逻 辑电路。
这里重要的一点是:与门、与非门、或门的感知机构造是一样的。
实际上,3个门电路只有参数的值(权重和阈值)不同。
也就是说,相同构造 的感知机,只需通过适当地调整参数的值,就可以像“变色龙演员”表演不 同的角色一样,变身为与门、与非门、或门。
感知机的实现
与门的代码实现
用Python来实现刚才的逻辑电路。这里,先定义一个接收 参数 x1 和 x2 的 AND 函数。
def AND(x1, x2):
"""
与门
在函数内初始化参数 w1 、 w2 、 theta ,当输入的加权总和超过阈值时返回 1 , 否则返回 0 。
"""
# w:权重,theta:阈值,x:参数
w1, w2, theta = 0.5, 0.5, 0.7
tmp = x1 * w1 + x2 * w2
print(tmp)
if tmp <= theta:
return 0
elif tmp > theta:
return 1
print(AND(0, 0))
print(AND(1, 0))
print(AND(0, 1))
print(AND(0.5, 1))
"""
0.0
0
0.5
0
0.5
0
0.75
1
"""
导入权重和偏置的代码实现
另外一种实现形式。在此之前,首先把公式一的θ换成−b,于 是就可以用式来表示感知机的行为。
公式二:
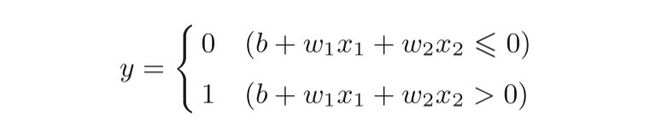
b称为偏置,w 1 和w 2 称为权重。
感知机会计算输入 信号和权重的乘积,然后加上偏置,如果这个值大于0则输出1,否则输出0。
In [1]: import numpy as np
In [2]: x = np.array([0,1]) # 输入
In [3]: w = np.array([0.5,0.5]) # 权重
In [4]: b = -0.7 # 偏置
In [5]: w * x
Out[5]: array([0. , 0.5])
In [6]: np.sum(w * x)
Out[6]: 0.5
In [7]: np.sum(w * x) + b
Out[7]: -0.19999999999999996 # 大约为 0.2(浮点小数造成的位运算误差)
In [8]:
如上例所示,在NumPy数组的乘法运算中,当两个数组的元素个数相同时, 各个元素将分别相乘。
因此 wx 的结果就是它们的各个元素分别相乘( [0, 1] * [0.5, 0.5] => [0, 0.5] )。之后, 再计算相乘后的各个元素的总和。 np.sum(wx)
最后再把偏置加到这个加权总和上,就完成了 公式二 计算。
使用权重和偏置的代码实现
使用权重和偏置,可以像下面这样实现与门。
import numpy as np
def AND(x1, x2):
x = np.array([x1, x2])
w = np.array([0.5, 0.5])
b = -0.7 # 偏置大于权重
tmp = np.sum(w * x) + b
print(tmp)
if tmp <= 0:
return 0
else:
return 1
print(AND(0, 0))
print(AND(1, 0))
print(AND(0, 1))
print(AND(0.5, 1))
"""
-0.7
0
-0.19999999999999996
0
-0.19999999999999996
0
0.050000000000000044
1
"""
偏置和权重w 1 、w 2 的作用是不 一样的。
w 1 和w 2 是控制输入信号的重要性的参数;
而偏置是调整神经元被激活的容易程度(输出信号为 1 的程度)的参数。
比如,若 b 为 −0.1, 则只要输入信号的加权总和超过0.1,神经元就会被激活。
但是如果b 为−20.0,则输入信号的加权总和必须超过20.0,神经元才会被激活。
像这样, 偏置的值决定了神经元被激活的容易程度。
另外,这里我们将w 1 和w 2 称为权重, 将b称为偏置,但是根据上下文,有时也会将b、w 1 、w 2 这些参数统称为权重。
小知识:偏置这个术语,有“穿木屐” 的效果,即在没有任何输入时(输入为 0时),给输出穿上多高的木屐(加上多大的值)的意思。实际上,在 公式二 的b + w 1 x 1 + w 2 x 2 的计算中,当输入x 1 和x 2 为0时,只输出 偏置的值。
与非门和或门的代码实现
import numpy as np
def NAND(x1, x2):
x = np.array([x1, x2])
w = np.array([-0.5, -0.5]) # 仅权重和偏置 与 AND不同!
b = 0.7 # 偏置设置为正,权重设置为负(与 AND相反)
tmp = np.sum(w * x) + b
print(tmp)
if tmp <= 0:
return 0
else:
return 1
print(NAND(0, 0))
print(NAND(1, 0))
print(NAND(0, 1))
print(NAND(0.5, 1))
"""
0.7
1
0.19999999999999996
1
0.19999999999999996
1
-0.050000000000000044
0
"""
print('-' * 100)
def OR(x1, x2):
x = np.array([x1, x2])
w = np.array([0.5, 0.5]) # 仅权重和偏置 与 AND不同!
b = -0.2 # 偏置小于 权重
tmp = np.sum(w * x) + b
print(tmp)
if tmp <= 0:
return 0
else:
return 1
print(OR(0, 0))
print(OR(1, 0))
print(OR(0, 1))
print(OR(0.5, 1))
"""
-0.2
0
0.3
1
0.3
1
0.55
1
"""
与门、与非门、或门是具有相同构造的感知机, 区别只在于权重参数的值。
因此,在与非门和或门的实现中,仅设置权重和 偏置的值这一点和与门的实现不同。
感知机的局限性
使用感知机可以实现与门、与非门、或门三种逻 辑电路。
现在我们来考虑一下异或门(XOR gate) 。
异或门
异或门也被称为逻辑异或电路。
仅当x 1 或x 2 中的一方为 1时,才会输出1(“异或”是拒绝其他的意思)。
[图片上传失败...(image-b464b8-1545699969488)]
异或门真值表
实际上,用前面介绍的感知机是无法实现这个异或门的。
我们试着将或门的动作形象化。
或门的情况下,当权重参数 (b, w 1 , w 2 ) = (−0.5, 1.0, 1.0)时,可满足 或门 的真值表条件。
此时,感知机 可用下面的式 公式三 表示。
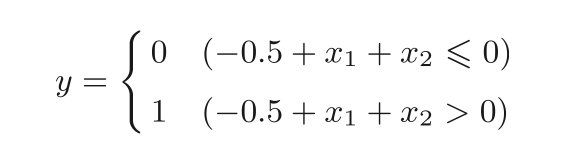
公式三 表示的感知机会生成由直线−0.5 + x 1 + x 2 = 0分割开的两个空 间。
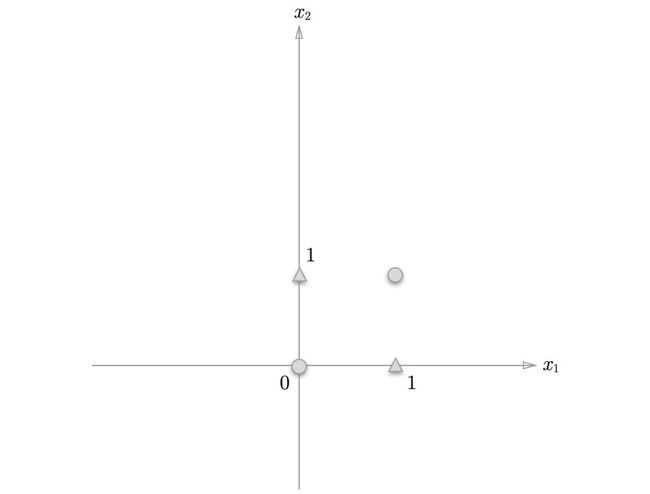
其中一个空间输出1,另一个空间输出0,如下图所示。

感知机的可视化图:灰色区域是感知机输出0的区域,这个区域与或门的性质一致
或门在 (x 1 , x 2 ) = (0, 0) 时输出 0,在 (x 1 , x 2 ) 为 (0, 1)、(1, 0)、(1, 1) 时输 出1。感知机的可视化图中,○表示0,△表示1。
现在需要用直线将上图中的○和△分开。实际上,刚才的那条直线就将这4个点正确地分开了(归类)。
如果我们换成异或门的话,能否像或门那样,用一条直线作出分 割 下图中的○和△的空间呢?
想要用一条直线将 上图 中的○和△分开,无论如何都做不到。事实上, 用一条直线是无法将○和△分开的。
但是如果将 “直线” 这个限制去掉,就可以实现了。
线性 和 非线性
感知机的局限性就在于它只能表示由一条直线分割的空间。

上图中 这样弯曲的曲线是无法用感知机表示的。
由曲线分割 而成的空间称为 非线性空间;
由直线分割 而成的空间称为 线性空间。
线性、非线性这两个术语在机器学习领域很常见,可以将其想象成上图所示的直线和曲线分割而成的空间。
多层感知机
“单层感知机无法表示异或门”或者“单层感知机无法分离非线性空间”。
但感知机 的绝妙之处在于它可以“叠加层”(通过叠加层来表示异或门)。
我们暂且不考虑叠加层具体是指什么,先从其他视角来思考一下异或 门的问题。
已有门电路的组合
异或门的制作方法有很多,其中之一就是组合我们前面做好的与门、与 非门、或门进行配置。
代码实现
import numpy as np
def AND(x1, x2):
x = np.array([x1, x2])
w = np.array([0.5, 0.5])
b = -0.7 # 偏置大于权重
tmp = np.sum(w * x) + b
print(tmp)
if tmp <= 0:
return 0
else:
return 1
print(AND(0, 0))
print(AND(1, 0))
print(AND(0, 1))
print(AND(0.5, 1))
"""
-0.7
0
-0.19999999999999996
0
-0.19999999999999996
0
0.050000000000000044
1
"""
print('-' * 100)
def NAND(x1, x2):
x = np.array([x1, x2])
w = np.array([-0.5, -0.5]) # 仅权重和偏置 与 AND不同!
b = 0.7
tmp = np.sum(w * x) + b
print(tmp)
if tmp <= 0:
return 0
else:
return 1
print(NAND(0, 0))
print(NAND(1, 0))
print(NAND(0, 1))
print(NAND(0.5, 1))
"""
0.7
1
0.19999999999999996
1
0.19999999999999996
1
-0.050000000000000044
0
"""
print('-' * 100)
def OR(x1, x2):
x = np.array([x1, x2])
w = np.array([0.5, 0.5]) # 仅权重和偏置 与 AND不同!
b = -0.2
tmp = np.sum(w * x) + b
print(tmp)
if tmp <= 0:
return 0
else:
return 1
print(OR(0, 0))
print(OR(1, 0))
print(OR(0, 1))
print(OR(0.5, 1))
"""
-0.2
0
0.3
1
0.3
1
0.55
1
"""
print('-' * 100)
def XOR(x1, x2):
s1 = NAND(x1, x2) # 与 AND 相反 有0 就行
s2 = OR(x1, x2) # 只要有一个既返回 1 # 有 1就行
y = AND(s1, s2) # 必须两个都是1
return y
print(XOR(0, 0))
print(XOR(1, 0))
print(XOR(0, 1))
print(XOR(1, 1))
与门、与非门、或门的符号

通过组合与门、与非门、或门实现异或门
这里,把s1 作为 与非门 的输出,把s 2 作为或门的输出,填入真值表中。
结果如图所示,观察x1、x 2 、y,可以发现确实符合异或门的输出。

异或门的真值表
异或门是一种多层结构的神经网络。
与门、或门是单层感知机,而异或门是2层感知机。叠加了多 层的感知机也称为多层感知机(multi-layered perceptron) 。

用感知机表示异或门
上图中的感知机总共由3层构成,但是因为拥有权重的层实质 上只有2层(第0层和第1层之间,第1层和第2层之间),所以称 为“2层感知机”。不过,有的文献认为上图的感知机是由3层 构成的,因而将其称为“3层感知机”。
1.第0层的两个神经元接收输入信号,并将信号发送至第1层的神经元。
2.第1层的神经元将信号发送至第2层的神经元,第2层的神经元输出y。
这种2层感知机的运行过程可以比作流水线的组装作业。
第1段(第1层) 的工人对传送过来的零件进行加工,完成后再传送给第2段(第2层)的工人。
第2层的工人对第1层的工人传过来的零件进行加工,完成这个零件后出货 (输出)。
小结
感知机是具有输入和输出的算法。给定一个输入后,将输出一个既 定的值。
感知机将权重和偏置设定为参数。
使用感知机可以表示与门和或门等逻辑电路。
异或门无法通过单层感知机来表示。
使用2层感知机可以表示异或门。
单层感知机只能表示线性空间,而多层感知机可以表示非线性空间。
多层感知机(在理论上)可以表示计算机。
(完)