Using Keras and Deep Deterministic Policy Gradient to play TORCS——300行python代码展示DDPG(基于Keras)——视频
可以先看新手向——使用Keras+卷积神经网络玩小鸟

为什么选择TORCS游戏
- 《The Open Racing Car Simulator》(TORCS)是一款开源3D赛车模拟游戏
- 看着AI学会开车是一件很酷的事
- 可视化并考察神经网络的学习过程,而不是仅仅看最终结果
- 容易看出神经网络陷入局部最优
- 帮助理解自动驾驶中的机器学习技术
安装运行
- 基于Ubuntu16.04,python3安装(Python2也可)
- OpenCV安装参看Installing OpenCV 3.0.0 on Ubuntu 14.04,有些包的版本变新了,根据提示改一下名称再apt-get安装就行。国内环境可能还有些问题,参看机器学习小鸟尝鲜 环境配置中的OpenCV部分,没问题就不管。
- 先安装一些包:
sudo apt-get install xautomation
sudo pip3 install numpy
sudo pip3 install gym
- 再下载gym_torcs源码(建议迅雷+download zip,比较快),解压压缩包。
- 然后将
gym_torcs/vtorcs-RL-color/src/modules/simu/simuv2/simu.cpp中第64行替换为if (isnan((float)(car->ctrl->gear)) || isinf(((float)(car->ctrl->gear)))) car->ctrl->gear = 0;,否则新的gcc会报错,Ubuntu14可能不用管。
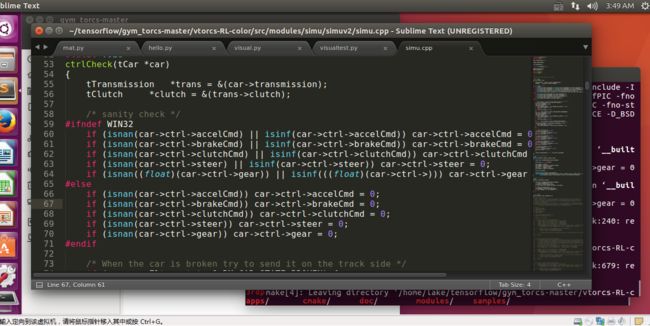 代码修改
代码修改 - 然后
cd进gym_torcs下vtorcs-RL-color目录,执行以下命令:
sudo apt-get install libglib2.0-dev libgl1-mesa-dev libglu1-mesa-dev freeglut3-dev libplib-dev libopenal-dev libalut-dev libxi-dev libxmu-dev libxrender-dev libxrandr-dev libpng12-dev
./configure
make
sudo make install
sudo make datainstall
- 检查TORCS是否正确安装:打开一个终端,输入命令
torcs,然后会出现图形界面,然后依次点击Race –> Practice –> New Race –> 会看到一个蓝屏输出信息“Initializing Driver scr_server1”。此时再打开一个终端,输入命令python3 snakeoil3_gym.py可以立刻看到一个演示,则安装成功。 - 然后
git clone https://github.com/yanpanlau/DDPG-Keras-Torcs.git #建议下载zip
cd DDPG-Keras-Torcs
cp *.* ../gym_torcs
cd ../gym_torcs
python3 ddpg.py
作者使用的是python2,所以他将snakeoil3_gym.py文件做了一些修改。我用的是python3,还需要将snakeoil3_gym.py文件再改回来,应该是在上面cp命令中不要复制覆盖snakeoil3_gym.py文件就对了。如果覆盖了就将snakeoil3_gym.py文件中python2的一些语法改成python3的:如print要加个括号,except要改成except socket.error as emsg,unicode()改成str()。这样就可以成功运行了。
背景
- 在上一篇译文新手向——使用Keras+卷积神经网络玩小鸟中,展示了如何使用深度Q学习神经网络来玩耍FlapyBird。但是,深Q网络的一个很大的局限性在于它的输出(是所有动作的Q值列表)是离散的,也就是对游戏的输入动作是离散的,而像在赛车游戏中的转向动作是一个连续的过程。一个显而易见的使DQN适应连续域的方法就是简单地将连续的动作空间离散化。但是马上我们就会遭遇‘维数灾难’问题。比如说,如果你将转盘从-90度到+90度的转动划分为5度一格,然后将将从0km到300km的加速度每5km一划分,你的输出组合将是36种转盘状态乘以60种速度状态等于2160种可能的组合。当你想让机器人进行一些更为专业化的操作时情况会更糟,比如脑外科手术这样需要精细的行为控制的操作,想要使用离散化来实现需要的操作精度就太naive了。
- Google Deepmind 已经设计了一种新的算法来解决这种连续动作空间问题,它将3种技术结合在一起构成了Deep Deterministic Policy Gradients (DDPG)算法:
- Deterministic Policy-Gradient Algorithms 确定性策略梯度算法(对于非机器学习研究者来说较难)
- Actor-Critic Methods 演员-评论家方法
- Deep Q-Network 深度Q学习神经网络
策略网络
- 首先,我们将要定义一个策略网络来实现我们的AI-司机。这个网络将接收游戏的状态(例如,赛车的速度,赛车和赛道中轴之间的距离等)并且决定我们该做什么(方向盘向左打向右打,踩油门还是踩刹车)。它被叫做基于策略的强化学习,因为我们直接将策略参数化:
\pi_\theta(s, a) = P [a | s, \theta]
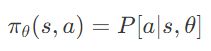
这里,s是状态,a是行为/动作,θ是策略网络的模型参数,π是常见的表示策略的符号。我们可以设想策略是我们行为的代理人,即一个从状态到动作的映射函数。
确定性VS随机策略
- 确定性策略:
a=μ(s)
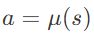
- 随机策略:
π(a∣s)=P[a∣s]
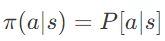
为什么在确定性策略之外我们还需要随机策略呢?理解一个确定性政策是容易的。我看到一个特定的状态输入,然后我采取特定的动作。但有时确定性策略不起作用,当你面对的第一个状态是个类似下面的白板时:
如果你还使用相同的确定性策略,你的网络将总是把棋子放在一个“特别”的位置,这是一个非常不好的行为,它会使你的对手能够预测你。在这种情况下,一个随机策略比确定性策略更合适。
策略目标函数
所以我们怎么找到π_θ(s,a)呢?实际上,我们能够使用增强技术来解决它。例如,假设AI正在努力学习如何左转。在一开始,AI可能根本就不会转方向盘并撞上路边,获得一个负奖励(惩罚),所以神经网络将调整模型参数θ,避免下一次再撞上路边。多次尝试之后,它会发现,“啊哈,如果我把方向盘往更左打一点,我就不会这么早撞到路边了”。用数学语言来说,这就是策略目标函数。
未来的总奖励函数定义为从离散的时间t开始的每一阶段的奖励之和:
R_t = r_t + r_{t+1} + r_{t+2} ... + r_n
上面的函数其实是马后炮函数,因为事情的总奖励在事情结束之前是不会确定的,说不定有转机呢(未来的动作数一般是很多的,也可能是不确定的),所谓俗语:"不到最后一刻绝不罢休"和"盖棺定论"讲得就是这个道理,而且复杂的世界中,同样的决策它的结果也可能是不一样的,总有人运气好,也有人运气差,"一个人的命运,不光要看个人的奋斗,还要考虑历史的行程",也就是说决策的结果可能还受一个不可掌控的未知参数影响。
所以,作为一种提供给当前状态做判断的预期,我们构造一个相对简单的函数,既充分考虑又在一定程度上 弱化未来的奖励(这个未来的奖励其实是基于经验得到,也就是训练的意义所在),得到未来的总折扣奖励(贴现奖励)函数:
R_t = r_t + \gamma r_{t+1} + \gamma^{2} r_{t+2} ... + \gamma^{n-t} r_n——
\gamma即
γ是折扣系数,一般取在(0,1)区间中
一个直观的策略目标函数将是总折扣奖励的期望:
L(\theta) = E[r_1 + \gamma r_2 + \gamma^{2} r_3 + ... | \pi_\theta(s,a)],这里暂时取t为1,总奖励为R
L(\theta) = E_{x\sim p(x|\theta)}[R]
在这里,总奖励R的期望是在 由参数θ调整的某一概率分布
p(x∣θ) 下计算的。
这时,又要用到我们的Q函数了,先回想一下上一篇译文的内容。
由上文的未来总折扣奖励R_t可以看出它能表示为递归的形式:
R_t = r_t + \gamma * R_{t+1},将上文的R_t中的t代换为t+1代入此式即可验证
而我们的Q函数(在s状态下选择动作a的最大贴现奖励)是
Q(s_t, a_t) = max R_{t+1}
这里等式左边的
t和右边的
t+1可能看上去有些错位,因为它是按下面这个图走的,不用太纠结。
但是接下来我们并没有和Q-learning采取同样的Q值更新策略,重点来了:
我们采用了 SARSA —— State-Action-Reward-State-Action代表了状态-动作-奖励-状态-动作。在SARSA中,我们开始于状态1,执行动作1,然后得到奖励1,于是我们到了状态2,在返回并更新在状态1下执行动作1的Q值之前,我们又执行了另一个动作(动作2)然后得到奖励2。相反,在Q-learning中,我们开始于状态1,执行动作1,然后得到奖励1,接着就是查看在状态2中无论做出任一动作的最大可能奖励,并用这个值来更新状态1下执行动作1的Q值。所以不同的是未来奖励被发现的方式。在Q-learning中它只是在状态2下最 可能采取的最有利的动作的最大预期值,而在SARSA中它就是 实际执行的动作的奖励值。
这意味着SARSA考虑到了赛车(游戏代理)移动的控制策略(由控制策略我们连续地执行了两步),并集成到它的动作值的更新中,而Q-learning只是假设一个最优策略被执行。 不考虑所谓的最优而遵循一定的策略有时会是好事。
于是乎,在连续的情况下,我们使用了SARSA,Q值公式去掉了max,它还是递归的,只是去掉了'武断'的max,而包含了控制策略,不过它并没有在这个Q值公式里表现出来,在更新公式的迭代中可以体现出来:
Q(s_t, a_t) = R_{t+1}
Q值的更新公式从Q-learning的
变为
所以,接着我们可以写出确定性策略a=μ(s)的梯度:
\frac{\partial L(\theta)}{\partial \theta} = E_{x\sim~p(x|\theta)}[\frac{\partial Q}{\partial \theta}]

然后应用高数中的链式法则:

它已经被证明(Silver el at. 2014)是策略梯度,即只要你按照上述的梯度公式来更新你的模型参数,你就会得到最大期望奖励。
补充
- Alberta大学课件Sarsa Q-Learning
- 一篇不错的国人博客: 增强学习——时间差分学习(Q learning, Sarsa learning)
- 区别辨析,直观易懂:Reinforcement Learning part 2: SARSA vs Q-learning
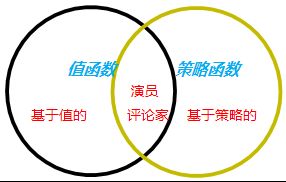
演员-评论家算法
演员-评论家算法本质上是策略梯度算法和值函数方法的混合算法。策略函数被称为演员,而价值函数被称为评论家。本质上,演员在当前环境的给定状态s下产生动作a,而评论家产生一个信号来批评演员做出的动作。这在人类世界中是相当自然的,其中研究生(演员)做实际工作,导师(评论家)批评你的工作来让你下一次做得更好:)。在我们的TORCS例子中,我们使用了SARSA作为我们的评论家模型,并使用策略梯度算法作为我们的演员模型。它们的关系如图:
回到之前的公式,我们将Q做近似代换,其中w是神经网络的权重。所以我们得到深度策略性梯度公式(DDPG):
\frac{\partial L(\theta)}{\partial \theta} = \frac{\partial Q(s,a,w)}{\partial a}\frac{\partial a}{\partial \theta}

其中策略参数θ可以通过随机梯度上升来更新。
此外,还有我们的损失函数,与SARSA的Q函数迭代更新公式一致:
Loss = [r + \gamma Q (s^{'},a^{'}) - Q(s,a)]^{2}
Q值用于估计当前演员策略的值。
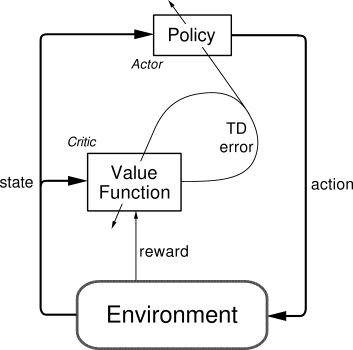
下图是演员-评论家模型的结构图:
Keras代码说明
演员网络
首先我们来看如何在Keras中构建演员网络。这里我们使用了2个隐藏层分别拥有300和600个隐藏单元。输出包括3个连续的动作。
- 转方向盘。是一个单元的输出层,使用
tanh激活函数(输出-1意味着最大右转,+1表示最大左转) - 加速。是一个单元的输出层,使用
sigmoid激活函数(输出0代表不加速,1表示全加速)。 - 刹车。是一个单元的输出层,也使用
sigmoid激活函数(输出0表示不制动,1表示紧急制动)。
def create_actor_network(self, state_size,action_dim):
print("Now we build the model")
S = Input(shape=[state_size])
h0 = Dense(HIDDEN1_UNITS, activation='relu')(S)
h1 = Dense(HIDDEN2_UNITS, activation='relu')(h0)
Steering = Dense(1,activation='tanh',init=lambda shape, name: normal(shape, scale=1e-4, name=name))(h1)
Acceleration = Dense(1,activation='sigmoid',init=lambda shape, name: normal(shape, scale=1e-4, name=name))(h1)
Brake = Dense(1,activation='sigmoid',init=lambda shape, name: normal(shape, scale=1e-4, name=name))(h1)
V = merge([Steering,Acceleration,Brake],mode='concat')
model = Model(input=S,output=V)
print("We finished building the model")
return model, model.trainable_weights, S
我们使用了一个Keras函数Merge来合并三个输出层(concat参数是将待合并层输出沿着最后一个维度进行拼接),为什么我们不使用如下的传统的定义方式呢:
V = Dense(3,activation='tanh')(h1)
使用3个不同的Dense()函数允许每个连续动作有不同的激活函数,例如,对加速使用tanh激活函数的话是没有意义的,tanh的输出是[-1,1],而加速的范围是[0,1]。
还要注意的是,在输出层我们使用了μ = 0,σ = 1e-4的正态分布初始化来确保策略的初期输出接近0。
评论家网络
评论家网络的构造和上一篇的小鸟深Q网络非常相似。唯一的区别是我们使用了2个300和600隐藏单元的隐藏层。此外,评论家网络同时接受了状态和动作的输入。根据DDPG的论文,动作输入直到网络的第二个隐藏层才被使用。同样我们使用了Merge函数来合并动作和状态的隐藏层。
def create_critic_network(self, state_size,action_dim):
print("Now we build the model")
S = Input(shape=[state_size])
A = Input(shape=[action_dim],name='action2')
w1 = Dense(HIDDEN1_UNITS, activation='relu')(S)
a1 = Dense(HIDDEN2_UNITS, activation='linear')(A)
h1 = Dense(HIDDEN2_UNITS, activation='linear')(w1)
h2 = merge([h1,a1],mode='sum')
h3 = Dense(HIDDEN2_UNITS, activation='relu')(h2)
V = Dense(action_dim,activation='linear')(h3)
model = Model(input=[S,A],output=V)
adam = Adam(lr=self.LEARNING_RATE)
model.compile(loss='mse', optimizer=adam)
print("We finished building the model")
return model, A, S
目标网络
有一个众所周知的事实,在很多环境(包括TORCS)下,直接利用神经网络来实现Q值函数被证明是不稳定的。Deepmind团队提出了该问题的解决方法——使用一个目标网络,在那里我们分别创建了演员和评论家网络的副本,用来计算目标值。这些目标网络的权重通过 让它们自己慢慢跟踪学习过的网络 来更新:
\theta^{'} \leftarrow \tau \theta + (1 - \tau) \theta^{'}
\tau即
τ
<< 1。这意味着目标值被限制为慢慢地改变,大大地提高了学习的稳定性。
在Keras中实现目标网络时非常简单的:
def target_train(self):
actor_weights = self.model.get_weights()
actor_target_weights = self.target_model.get_weights()
for i in xrange(len(actor_weights)):
actor_target_weights[i] = self.TAU * actor_weights[i] + (1 - self.TAU)* actor_target_weights[i]
self.target_model.set_weights(actor_target_weights)
主要代码
在搭建完神经网络后,我们开始探索ddpg.py主代码文件。
它主要做了三件事:
- 接收数组形式的传感器输入
- 传感器输入将被馈入我们的神经网络,然后网络会输出3个实数(转向,加速和制动的值)
- 网络将被训练很多次,通过DDPG(深度确定性策略梯度算法)来最大化未来预期回报。
传感器输入
在TORCS中有18种不同类型的传感器输入,详细的说明在这篇文章中Simulated Car Racing Championship : Competition Software Manual。在试错后得到了有用的输入:
| 名称 | 范围 (单位) | 描述 |
|---|---|---|
| ob.angle | [-π,+π] (rad) | 汽车方向和道路轴方向之间的夹角 |
| ob.track | (0, 200) (m) | 19个测距仪传感器组成的矢量,每个传感器返回200米范围内的车和道路边缘的距离 |
| ob.trackPos | (-oo, +oo) | 车和道路轴之间的距离,这个值用道路宽度归一化了:0表示车在中轴上,大于1或小于-1表示车已经跑出道路了 |
| ob.speedX | (-oo, +oo) (km/h) | 沿车纵向轴线的车速度(good velocity) |
| ob.speedY | (-oo, +oo) (km/h) | 沿车横向轴线的车速度 |
| ob.speedZ | (-oo, +oo) (km/h) | 沿车的Z-轴线的车速度 |
| ob.wheelSpinVel | (0,+oo) (rad/s) | 4个传感器组成的矢量,表示车轮的旋转速度 |
| ob.rpm | (0,+oo) (rpm) | 汽车发动机的每分钟转速 |
请注意,对于某些值我们归一化后再馈入神经网络,并且有些传感器输入并没有暴露在gym_torcs中。高级用户需要修改gym_torcs.py来改变参数。(查看函数make_observaton())
策略选择
现在我们可以使用上面的输入来馈入神经网络。代码很简单:
for j in range(max_steps):
a_t = actor.model.predict(s_t.reshape(1, s_t.shape[0]))
ob, r_t, done, info = env.step(a_t[0])
然而,我们马上遇到两个问题。首先,我们如何确定奖励?其次,我们如何在连续的动作空间探索?
奖励设计
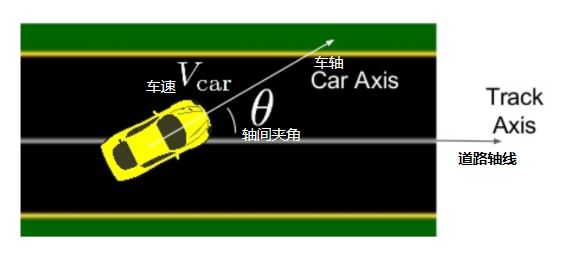
在原始论文中,他们使用的奖励函数,等于投射到道路轴向的汽车速度,即Vx*cos(θ),如图:
但是,我发现训练正如原始论文中说的那样并不是很稳定。有些时候可以学到合理的策略并成功完成任务,有些时候则不然,并不能习得明智的策略。
我相信原因是,在原始的策略中,AI会尝试拼命踩油门油来获得最大的奖励,然后它会撞上路边,这轮非常迅速地结束。因此,神经网络陷入一个非常差的局部最小中。新提出的奖励函数如下:
R_t = V_x cos(\theta) - V_y sin(\theta) - V_x \mid trackPos \mid
简单说来,我们想要最大化轴向速度(第一项),最小化横向速度(第二项),并且我们惩罚AI如果它持续非常偏离道路的中心(第三项)。
这个新的奖励函数大幅提高了稳定性,降低了TORCS学习时间。
探索算法的设计
另一个问题是在连续空间中如何设计一个正确的探索算法。在上一篇文章中,我们使用了ε贪婪策略,即在某些时间片,我们尝试一个随机的动作。但是这个方法在TORCS中并不有效,因为我们有3个动作(转向,加速,制动)。如果我只是从均匀分布的动作中随机选取,会产生一些无聊的组合(例如:制动的值大于加速的值,车子根本就不会动)。所以,我们使用奥恩斯坦 - 乌伦贝克(Ornstein-Uhlenbeck)过程添加噪声来做探索。
Ornstein-Uhlenbeck处理
简单说来,它就是具有均值回归特性的随机过程。
dx_t = \theta (\mu - x_t)dt + \sigma dW_t
这里,θ反应变量回归均值有多快。μ代表平衡或均值。σ是该过程的波动程度。有趣的事,奥恩斯坦 - 乌伦贝克过程是一种很常见的方法,用来随机模拟利率,外汇和大宗商品价格。(也是金融定量面试的常见问题)。下表展示了在代码中使用的建议值。
| Action | θ | μ | σ |
|---|---|---|---|
| steering | 0.6 | 0.0 | 0.30 |
| acceleration | 1.0 | [0.3-0.6] | 0.10 |
| brake | 1.0 | -0.1 | 0.05 |
基本上,最重要的参数是加速度μ,你想要让汽车有一定的初始速度,而不要陷入局部最小(此时汽车一直踩刹车,不再踩油门)。你可以随意更改参数来实验AI在不同组合下的行为。奥恩斯坦的 - 乌伦贝克过程的代码保存在OU.py中。
AI如果使用合理的探索策略和修订的奖励函数,它能在一个简单的赛道上在200回合左右学习到一个合理的策略。
经验回放
类似于深Q小鸟,我们也使用了经验回放来保存所有的阶段(s, a, r, s')在一个回放存储器中。当训练神经网络时,从其中随机小批量抽取阶段情景,而不是使用最近的,这将大大提高系统的稳定性。
buff.add(s_t, a_t[0], r_t, s_t1, done)
# 从存储回放器中随机小批量抽取N个变换阶段 (si, ai, ri, si+1)
batch = buff.getBatch(BATCH_SIZE)
states = np.asarray([e[0] for e in batch])
actions = np.asarray([e[1] for e in batch])
rewards = np.asarray([e[2] for e in batch])
new_states = np.asarray([e[3] for e in batch])
dones = np.asarray([e[4] for e in batch])
y_t = np.asarray([e[1] for e in batch])
target_q_values = critic.target_model.predict([new_states, actor.target_model.predict(new_states)]) #Still using tf
for k in range(len(batch)):
if dones[k]:
y_t[k] = rewards[k]
else:
y_t[k] = rewards[k] + GAMMA*target_q_values[k]
请注意,当计算了target_q_values时我们使用的是目标网络的输出,而不是模型自身。使用缓变的目标网络将减少Q值估测的振荡,从而大幅提高学习的稳定性。
训练
神经网络的实际训练非常简单,只包含了6行代码:
loss += critic.model.train_on_batch([states,actions], y_t)
a_for_grad = actor.model.predict(states)
grads = critic.gradients(states, a_for_grad)
actor.train(states, grads)
actor.target_train()
critic.target_train()
首先,我们最小化损失函数来更新评论家。
L = \frac{1}{N} \displaystyle\sum_{i} (y_i - Q(s_i,a_i | \theta^{Q}))^{2}
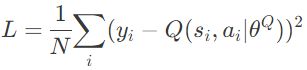
然后演员策略使用一定样本的策略梯度来更新
\nabla_\theta J = \frac{\partial Q^{\theta}(s,a)}{\partial a}\frac{\partial a}{\partial \theta}
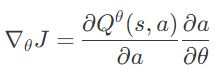
回想一下,a是确定性策略:
a=μ(s∣θ)
因此,它能被写作:
\nabla_\theta J = \frac{\partial Q^{\theta}(s,a)}{\partial a}\frac{\partial \mu(s|\theta)}{\partial \theta}

最后两行代码更新了目标网络
\theta^{Q^{'}} \leftarrow \tau \theta^{Q} + (1 - \tau) \theta^{Q^{'}} \theta^{\mu^{'}} \leftarrow \tau \theta^{\mu} + (1 - \tau) \theta^{\mu^{'}}
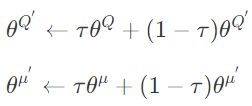
结果
为了测试策略,选择一个名为Aalborg的稍微困难的赛道,如下图:
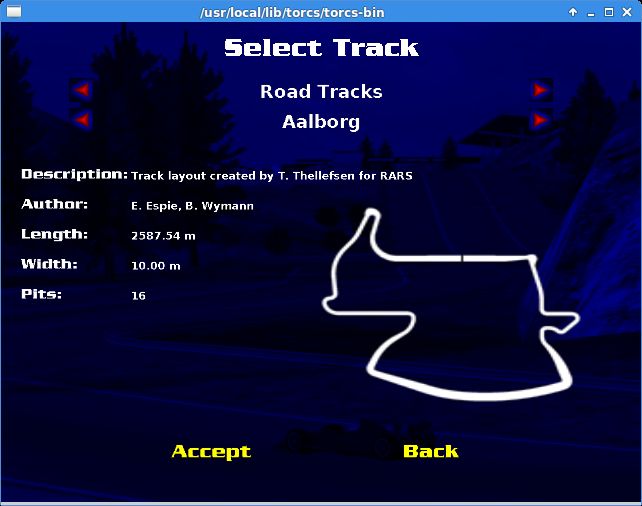
神经网络被训练了2000个回合,并且令奥恩斯坦 - 乌伦贝克过程在100000帧中线性衰变。(即没有更多的开发在100000帧后被应用)。然后测试一个新的赛道(3倍长)来验证我们的神经网络。在其它赛道上测试是很重要的,这可以确认AI是否只是简单地记忆住了赛道(过拟合),而非学习到通用的策略。

测试结果视频,赛道: Aalborg 与 Alpine。
结果还不错,但是还不理想,因为它还没太学会使用刹车。
学习如何刹车
事实证明,要求AI学会如何刹车比转弯和加速难多了。原因在于当刹车的时候车速降低,因此,奖励也会下降,AI根本就不会热心于踩刹车。另外, 如果允许AI在勘探阶段同时踩刹车和加速,AI会经常急刹,我们会陷入糟糕的局部最小解(汽车不动,不会受到任何奖励)。
所以如何去解决这个问题呢?不要急刹车,而是试着感觉刹车。我们在TORCS中添加随机刹车的机制:在勘探阶段,10%的时间刹车(感觉刹车),90%的时间不刹车。因为只在10%的时间里刹车,汽车会有一定的速度,因此它不会陷入局部最小(汽车不动),而同时,它又能学习到如何去刹车。
“随机刹车”使得AI在直道上加速很快,在快拐弯时适当地刹车。这样的行为更接近人类的做法。
总结和进一步的工作
我们成功地使用 Keras和DDPG来玩赛车游戏。尽管DDPG能学习到一个合理的策略,但和人学会开车的复杂机制还是有很大区别的,而且如果是开飞机这种有更多动作组合的问题,事情会复杂得多。
不过,这个算法还是相当给力的,因为我们有了一个对于连续控制的无模型算法,这对于机器人是很有意义的。
杂项
- 要更换赛道,需要命令行输入 sudo torcs –> Race –> Practice –> Configure Race。
- 关闭声音,需要命令行输入sudo torcs –> Options –> Sound –> Disable sound。
-
snakeoil3_gym.py是与TORCS服务器沟通的脚本。
参考
[1] Lillicrap, et al. Continuous control with Deep Reinforcement Learning
[2] @karpathy的Deep Reinforcement Learning: Pong from Pixels——理解策略梯度
其它
- Deep Learning Episode 3: Supercomputer vs Pong
作者的致谢
I thank to Naoto Yoshida, the author of the gym_torcs and his prompt reply on various TORCS setup issue. I also thank to @karpathy his great post Deep Reinforcement Learning: Pong from Pixels which really helps me to understand policy gradient. I thank to @hardmaru and @flyyufelix for their comments and suggestions.