。1.注册中国大学MOOC
2.选择北京理工大学嵩天老师的《Python网络爬虫与信息提取》MOOC课程
3.学习完成第0周至第4周的课程内容,并完成各周作业
4.提供图片或网站显示的学习进度,证明学习的过程。
5.写一篇不少于1000字的学习笔记,谈一下学习的体会和收获。
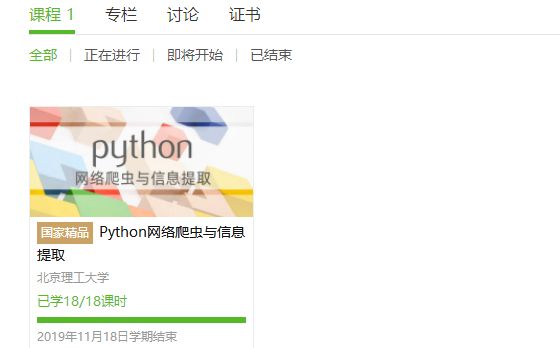
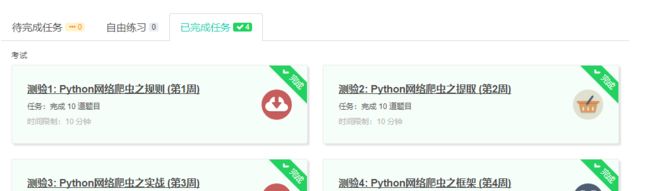
学习笔记:
Python在编程语言中的重要性不言而喻,这次跟随慕课学习《Python网络爬虫与信息提取》,对Python有了新的认识。
网络爬虫可以做到分析教务系统网络接口,用程序在网上抢最热门的课;爬取网络公开的用户信息,并汇总出售;持续关注某个人的微博或朋友圈,自动为新发布的内容点赞等。而
个人电脑中数据没有联网且没有通过Web服务器以URL形式被网络访问,则不能用爬虫获取。切记,及时能爬取数据,数据的知识产权仍然受保护,商业获利(出售)将涉嫌违法。
Requests库共有7个主要方法:request()、get()、head()、post()、put()、patch()、delete(),名字基本与HTTP的操作相同。
URL格式错误,一般指URL格式不符合规范导致无法建立连接,通常会产生URLRequired错误。如果URL格式正确,可能触发Timeout类错误。
数据推送(push model)一般指将数据发送出去的行为。在Requests库中,post()、put()、patch()都体现这种行为模式。
request()是其他所有函数的基础函数,完成所有功能,其它函数只是它的一种封装形式。
Requests库中,检查Response对象返回是否成功的状态属性是r.status_code,200表示连接成功,404表示失败。
.encoding是从HTTP header中猜测获得的响应内容编码方式
.apparent_encoding是从内容中分析出的编码方式,一般作为备选编码方式
DNS失败将造成网络连接错误,因此产生连接错误异常。
get()方法最常用的原因在于服务器端对push()、post()、patch()等数据推送的限制,试想,如果允许大家向服务器提交数据,将带来无穷无尽的安全隐患。因此,通过get()获取数据,服务器作为数据提供方而不是接收方,更为安全。
Beautiful Soup库也叫bs4库,能够对HTML和XML等格式进行解析,是解析、遍历、维护标签树的功能库;属于bs4库遍历标签树方法的是:平行遍历;上行遍历;下行遍历。在bs4中,标签树上除了标签外,节点还可能是字符串(NavigableString)类型;一个HTML文档与BeautifulSoup对象等价;一个HTML文档与一个标签树等价。
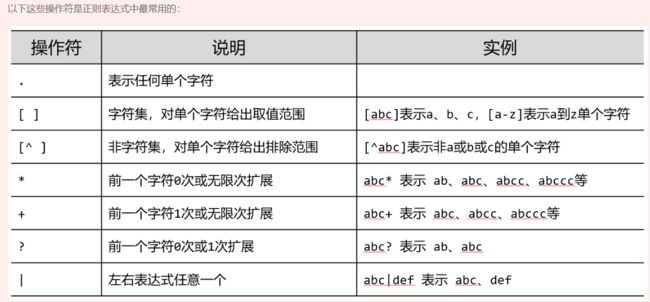
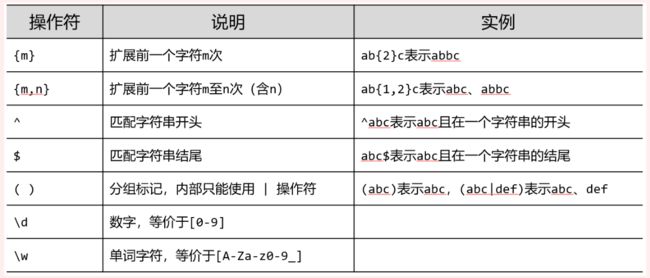
Re正则表达式,是用来提取页面的关键信息的,是用来简洁表达一组字符串的表达式,正则表达式语法由字符和操作符构成和re库主要功能函数。它的优势是简洁,一行胜千言,特征表达。
Scrapy是爬虫框架,是网站级爬虫,并且是一个框架,并发性好,性能较高,requests重点在页面下载,而Scrapy重点在于爬虫结构,一般定制灵活,深度定制困难。 Scrapy具有5+2结构,其中,5个模块分别是:Engine、Spiders、Scheduler、Downloader和Item Pipelines。Spiders模块给出了Scrapy爬虫最初始的请求,Spider->Engine->Scheduler,注意,Spider请求不直接到Downloader模块。
一个学科知识的学习是无止境的,目前还都是皮毛,只有不断学习,不断实践,才会记得深刻,用起来得心应手。