Redis 过期淘汰策略
redis的过期淘汰策略是非常值得去深入了解以及考究的一个问题。很多使用者往往不能深得其意,往往停留在人云亦云的程度,若生产不出事故便划水就划过去了,但是当生产数据莫名其妙的消失,或者reids服务崩溃的时候,却又束手无策。本文尝试着从浅入深的将redis的过期策略剖析开来,期望帮助作者以及读者站在一个更加系统化的角度去看待过期策略。
redis作为缓存数据库,其底层数据结构主要由dict和expires两个字典构成,其中dict字典负责保存键值对,而expires字典则负责保存键的过期时间。访问磁盘空间的成本是访问缓存的成本高出非常多,所以内存的成本比磁盘空间要大。在实际使用中,缓存的空间往往极为有限,所以为了在为数不多的容量中做到真正的物尽其用,必须要对缓存的容量进行管控。
内存策略
redis通过配置
maxmemory来配置最大容量(阈值),当数据占有空间超过所设定值就会触发内部的内存淘汰策略(内存释放)。那么究竟要淘汰哪些数据,才是最符合业务需求?或者在业务容忍的范围内呢?为了解决这个问题,redis提供了可配置的淘汰策略,让使用者可以配置适合自己业务场景的淘汰策略,不配置的情况下默认是使用volatile-lru。
noeviction:当内存不足以容纳新写入数据时,新写入操作会报错。
allkeys-lru:当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的key。
allkeys-random:当内存不足以容纳新写入数据时,在键空间中,随机移除某个key。
volatile-lru:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,移除最近最少使用的key。
volatile-random:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,随机移除某个key。
volatile-ttl:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,有更早过期时间的key优先移除。
如果redis保存的key-value对数量不多(比如数十对),那么当内存超过阈值后,对整个内存空间的所有key进行检查,也无伤大雅。然而,在实际使用中redis保存的key-value数量远远不止于此,如果使用内存超过阈值就逐个去检查是否符合过期策略吗?随意遍历十万个key?显然不是,否则,redis又何以高性能著称?但是,检查多少key这个问题确实存在。为了解决该问题,redis的设计者们引入一个配置项maxmemory-samples,称之为过期检测样本,默认值是3,通过它来曲线救国。
过期检测样本是如何配合redis来进行数据清理呢?
当mem_used内存已经超过maxmemory的设定,对于所有的读写请求,都会触发redis.c/freeMemoryIfNeeded函数以清理超出的内存。注意这个清理过程是阻塞的,直到清理出足够的内存空间。所以如果在达到maxmemory并且调用方还在不断写入的情况下,可能会反复触发主动清理策略,导致请求会有一定的延迟。
清理时会根据用户配置的maxmemory政策来做适当的清理(一般是LRU或TTL),这里的LRU或TTL策略并不是针对redis的的所有键,而是以配置文件中的maxmemory样本个键作为样本池进行抽样清理。
redis设计者将该值默认为3,如果增加该值,会提高LRU或TTL的精准度,redis的作者测试的结果是当这个配置为10时已经非常接近全量LRU的精准度了,而且增加
maxmemory采样会导致在主动清理时消耗更多的CPU时间,所以在设置该值必须慎重把控,在业务的需求以及性能之间做权衡。建议如下:
尽量不要触发
maxmemory,最好在mem_used内存占用达到maxmemory的一定比例后,需要考虑调大赫兹以加快淘汰,或者进行集群扩容。如果能够控制住内存,则可以不用修改
maxmemory-samples配置。如果redis本身就作为LRU缓存服务(这种服务一般长时间处于maxmemory状态,由redis自动做LRU淘汰),可以适当调大maxmemory样本。
freeMemoryIfNeeded源码解读
int freeMemoryIfNeeded(void) {
size_t mem_used, mem_tofree, mem_freed;
int slaves = listLength(server.slaves);
// 计算占用内存大小时,并不计算slave output buffer和aof buffer,
// 因此maxmemory应该比实际内存小,为这两个buffer留足空间。
mem_used = zmalloc_used_memory();
if (slaves) {
listIter li;
listNode *ln;
listRewind(server.slaves,&li);
while((ln = listNext(&li))) {
redisClient *slave = listNodeValue(ln);
unsigned long obuf_bytes = getClientOutputBufferMemoryUsage(slave);
if (obuf_bytes > mem_used)
mem_used = 0;
else
mem_used -= obuf_bytes;
}
}
if (server.appendonly) {
mem_used -= sdslen(server.aofbuf);
mem_used -= sdslen(server.bgrewritebuf);
}
// 判断已经使用内存是否超过最大使用内存,如果没有超过就返回REDIS_OK,
if (mem_used <= server.maxmemory) return REDIS_OK;
// 当超过了最大使用内存时,就要判断此时redis到底采用何种内存释放策略,根据不同的策略,采取不同的清除算法。
// 首先判断是否是为no-enviction策略,如果是,则返回REDIS_ERR,然后redis就不再接受任何写命令了。
if (server.maxmemory_policy == REDIS_MAXMEMORY_NO_EVICTION)
return REDIS_ERR;
// 计算需要清理内存大小
mem_tofree = mem_used - server.maxmemory;
mem_freed = 0;
while (mem_freed < mem_tofree) {
int j, k, keys_freed = 0;
for (j = 0; j < server.dbnum; j++) {
long bestval = 0;
sds bestkey = NULL;
struct dictEntry *de;
redisDb *db = server.db+j;
dict *dict;
// 1、从哪个字典中剔除数据
// 判断淘汰策略是基于所有的键还是只是基于设置了过期时间的键,
// 如果是针对所有的键,就从server.db[j].dict中取数据,
// 如果是针对设置了过期时间的键,就从server.db[j].expires(记录过期时间)中取数据。
if (server.maxmemory_policy == REDIS_MAXMEMORY_ALLKEYS_LRU ||
server.maxmemory_policy == REDIS_MAXMEMORY_ALLKEYS_RANDOM)
{
dict = server.db[j].dict;
} else {
dict = server.db[j].expires;
}
if (dictSize(dict) == 0) continue;
// 2、从是否为随机策略
// 是不是random策略,包括volatile-random 和allkeys-random,这两种策略是最简单的,就是在上面的数据集中随便去一个键,然后删掉。
if (server.maxmemory_policy == REDIS_MAXMEMORY_ALLKEYS_RANDOM ||
server.maxmemory_policy == REDIS_MAXMEMORY_VOLATILE_RANDOM)
{
de = dictGetRandomKey(dict);// 从方法名猜出是随机获取一个dictEntry
bestkey = dictGetEntryKey(de);// 得到删除的key
}
// 3、判断是否为lru算法
// 是lru策略还是ttl策略,如果是lru策略就采用lru近似算法
// 为了减少运算量,redis的lru算法和expire淘汰算法一样,都是非最优解,
// lru算法是在相应的dict中,选择maxmemory_samples(默认设置是3)份key,挑选其中lru的,进行淘汰
else if (server.maxmemory_policy == REDIS_MAXMEMORY_ALLKEYS_LRU ||
server.maxmemory_policy == REDIS_MAXMEMORY_VOLATILE_LRU)
{
for (k = 0; k < server.maxmemory_samples; k++) {
sds thiskey;
long thisval;
robj *o;
de = dictGetRandomKey(dict);
thiskey = dictGetEntryKey(de);
/* When policy is volatile-lru we need an additonal lookup
* to locate the real key, as dict is set to db->expires. */
if (server.maxmemory_policy == REDIS_MAXMEMORY_VOLATILE_LRU)
de = dictFind(db->dict, thiskey); //因为dict->expires维护的数据结构里并没有记录该key的最后访问时间
o = dictGetEntryVal(de);
thisval = estimateObjectIdleTime(o);
/* Higher idle time is better candidate for deletion */
// 找到那个最合适删除的key
// 类似排序,循环后找到最近最少使用,将其删除
if (bestkey == NULL || thisval > bestval) {
bestkey = thiskey;
bestval = thisval;
}
}
}
// 如果是ttl策略。
// 取maxmemory_samples个键,比较过期时间,
// 从这些键中找到最快过期的那个键,并将其删除
else if (server.maxmemory_policy == REDIS_MAXMEMORY_VOLATILE_TTL) {
for (k = 0; k < server.maxmemory_samples; k++) {
sds thiskey;
long thisval;
de = dictGetRandomKey(dict);
thiskey = dictGetEntryKey(de);
thisval = (long) dictGetEntryVal(de);
/* Expire sooner (minor expire unix timestamp) is better candidate for deletion */
if (bestkey == NULL || thisval < bestval) {
bestkey = thiskey;
bestval = thisval;
}
}
}
// 根据不同策略挑选了即将删除的key之后,进行删除
if (bestkey) {
long long delta;
robj *keyobj = createStringObject(bestkey,sdslen(bestkey));
// 发布数据更新消息,主要是AOF 持久化和从机
propagateExpire(db,keyobj); //将del命令扩散给slaves
// 注意, propagateExpire() 可能会导致内存的分配,
// propagateExpire() 提前执行就是因为redis 只计算
// dbDelete() 释放的内存大小。倘若同时计算dbDelete()
// 释放的内存和propagateExpire() 分配空间的大小,与此
// 同时假设分配空间大于释放空间,就有可能永远退不出这个循环。
// 下面的代码会同时计算dbDelete() 释放的内存和propagateExpire() 分配空间的大小
/* We compute the amount of memory freed by dbDelete() alone.
* It is possible that actually the memory needed to propagate
* the DEL in AOF and replication link is greater than the one
* we are freeing removing the key, but we can't account for
* that otherwise we would never exit the loop.
*
* AOF and Output buffer memory will be freed eventually so
* we only care about memory used by the key space. */
// 只计算dbDelete() 释放内存的大小
delta = (long long) zmalloc_used_memory();
dbDelete(db,keyobj);
delta -= (long long) zmalloc_used_memory();
mem_freed += delta;
server.stat_evictedkeys++;
decrRefCount(keyobj);
keys_freed++;
/* When the memory to free starts to be big enough, we may
* start spending so much time here that is impossible to
* deliver data to the slaves fast enough, so we force the
* transmission here inside the loop. */
// 将从机回复空间中的数据及时发送给从机
if (slaves) flushSlavesOutputBuffers();
}
}//在所有的db中遍历一遍,然后判断删除的key释放的空间是否足够,未能释放空间,且此时redis 使用的内存大小依旧超额,失败返回
if (!keys_freed) return REDIS_ERR; /* nothing to free... */
}
return REDIS_OK;
}
从源码分析中可以看到redis在使用内存中超过设定的阈值时是如何将清理key-value进行内管管理,其中涉及到redis的存储结构。开篇就说到redis底层数据结构是由dict以及expires两个字典构成,通过一张图可以非常清晰了解到redis中带过期时间的key-value的存储结构,可以更加深刻认识到redis的内存管理机制。
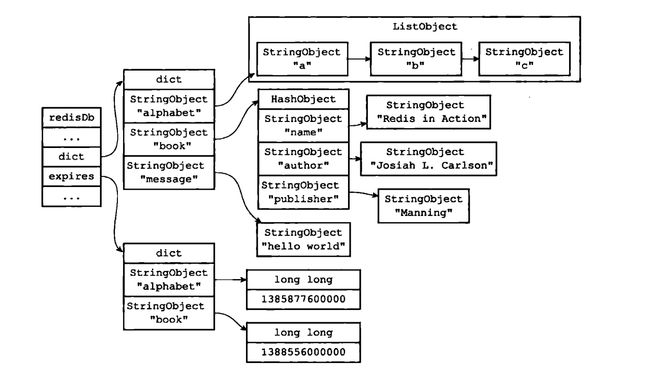
从redis的内存管理机制中我们可以看到,当使用的内存超过设定的阈值,就会触发内存清理。那么一定要等到内存超过阈值才进行内存清理吗?非要亡羊补牢?redis的设计者显然是考虑到了这个问题,当redis在使用过程中,自行去删除一些过期key,尽量保证不要触发超过内存阈值而发生的清理事件。
有效时间
expire/pexpire key time(以秒/毫秒为单位)--这是最常用的方式(Time To Live 称为TTL)
setex(String key, int seconds, String value)--字符串独有的方式
在使用过期时间时,必要注意如下三点:
除了字符串自己独有设置过期时间的方法外,其他方法都需要依靠expire方法来设置时间
如果没有设置时间,那缓存就是永不过期
如果设置了过期时间,之后又想让缓存永不过期,使用persist key
过期键自动删除策略
1、定时删除(主动删除策略):通过使用定时器(时间事件,采用无序链表实现,),定时删除数据。定时删除策略可以保证过期的键会尽可能快的被删除了,并释放过期键锁占用的内存。
好处:对内存是最友好的。
坏处:它对CPU时间不友好,在过期键比较多的情况下,删除过期键这一行为会占用相当一部分CPU时间,在内存不紧张但是CPU非常紧张的情况下,将CPU应用于删除和当前任务无关的过期键上,无疑会对服务器的响应时间和吞吐量造成影响。
2、惰性删除(被动删除策略):程序在每次使用到键的时候去检查是否过期,如果过期则删除并返回空。
好处:对CPU时间友好,永远只在操作与当前任务有关的键。
坏处:可能会在内存中遗留大量的过期键而不删除,造成内存泄漏。
3、定期删除(主动删除):定期每隔一段时间执行一段删除过期键操作,通过限制删除操作的执行时长与频率来减少删除操作对CPU时间的影响。除此之外,定期执行也可以减少过期键长期驻留内存的影响,减少内存泄漏的可能。
好处:可以控制过期删除的执行频率
坏处:服务器必须合理设置过期键删除的操作时间以及执行的频率。
redis的过期键删除策略
redis服务器实际上使用的惰性删除和定期删除两种策略:通过配合使用两种删除策略,服务器可以很好地合理使用CPU时间和避免浪费内存空间之间取得平衡。
惰性删除策略的实现
redis提供一个
expireIfNeeded函数,所以读写数据库的命令在执行之前都必须调用expireIfNeeded函数。(键是否存在)
如果过期 --> 删除
如果非过期 --> 执行命令(expireIfNeeded函数不做动作)
定期删除策略的实现
定期删除有函数
activeExpireCycle函数实现,每当redis服务器调用serverCorn函数时执行定期删除函数。它会在规定时间内,分多次遍历服务器中的各个数据库,并在数据库的expire字典中随机检查一部分键的过期时间,并删除过期键。
遍历数据库(就是redis.conf中配置的"database"数量,默认为16)
检查当前库中的指定个数个key(默认是每个库检查20个key,注意相当于该循环执行20次)
如果当前库中没有一个key设置了过期时间,直接执行下一个库的遍历
随机获取一个设置了过期时间的key,检查该key是否过期,如果过期,删除key
判断定期删除操作是否已经达到指定时长,若已经达到,直接退出定期删除。
参考资料:
《Redis设计与实现》
深入理解Redis数据淘汰策略:https://blog.csdn.net/wtyvhreal/article/details/46390065