1.注册中国大学MOOC
2.选择北京理工大学嵩天老师的《Python网络爬虫与信息提取》MOOC课程
3.学习完成第0周至第4周的课程内容,并完成各周作业
4.提供图片或网站显示的学习进度,证明学习的过程。
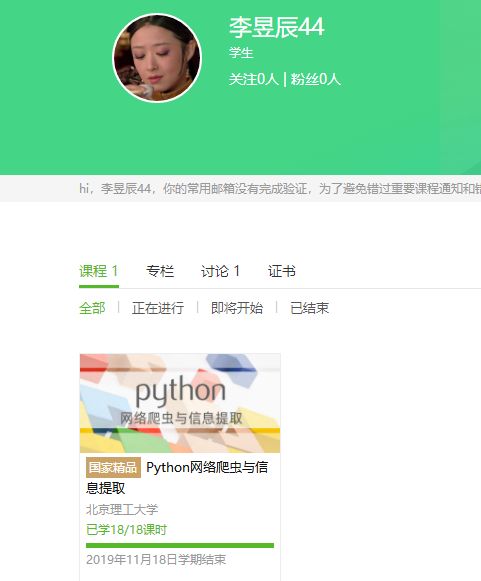
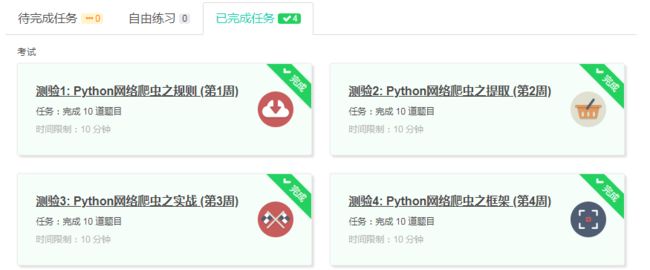
5.写一篇不少于1k字的学习笔记。
《python网络爬虫学习笔记》
第一周学习:resquests库
7个主要方法
requests.request() 构造一个请求头,支持以下各种方法的基础
requests.get() GET请求方式
requests.head() HEAD
requests.post() POST
requests.put() PUT
requests.patch() 向页面提交局部修改请求,PATCH
requests.delete() 向页面提交删除请求
参数
requests.request(method, url, **kwargs)kwargs共13个参数
1. params如果method=GET, params=kv(字典), 实现拼接url地址(params可以字典,字节序列,添加到url中)
2. Data 如果method=POST, data=kv(字典),实现发送form表单(data可以字典,字节序列,文件对象)
3. json,json=kv,JSON格式的数据,作为请求体的一部分
4. headers,字典,HTTP定制头
5. cookies auth,元组,支持HTTP认证功能
7. files,字典类型,传输文件
8. timeout,设定超时时间,秒为单位
9. proxies,字典类型,设定访问代理服务器,可以增加登陆认证
10. allow_redirects,True/False,默认True,重定向开关
11. stream,True/False,默认True,获取内容立即下载开关
12. verify,True/Flase,默认T,认证SSL证书开关
13. cert,本地SSL证书
第二周学习:beautiful soup
导包:from bs4 import BeautifulSoup
指定解析方式:soup = BeautifulSoup(response.text, "lxml")
或者页面写入本地,打开本地文件解析:soup = BeautifulSoup(open("xxxx"), "lxml")
遍历
下行遍历:
.contents返回一个列表
.children返回一个迭代器
.descendants返回子孙级标签
上行遍历:
.parents
平行遍历:
.next_sibling下一个平行标签
.previous_sibling上一个平行标签
.next_siblings后面所有平行标签,返回类型为迭代器
.previous_siblings前面所有平行标签,返回类型为迭代器
find(tag, attrs, recursive, text, keywords)
findAll(tag, attrs, recursive, text, limit, keywords)
区别:除了参数limit外,前者返回第一个符合条件的对象,后者以列表方式返回所有符合条件
针对tag参数
-findAll("a")寻找所有a标签
-findAll({"a", "b", "p"})寻找所有a,b,p标签
针对attrs参数
+findAll("a", {"class":"sister"})寻找标签a且属性class=”sister”
+findAll("a", {"class":{"sister", "brother"})寻找标签a且属性class=”sister”或者brother
+findAll("", {"class":"sister"})不限定标签类型,返回符合属性条件的标签
+以上可以看出,attrs属性不能单独使用
针对text参数
-findAll(text="test")区配文本内容为test的标签,返回该内容的列表
针对keyword参数
+findAll(id="link1")寻找属性id=”link1”的标签
+findAll(class_="sister")寻找属性class=”sister”的标签,由于class是python的关键字,所以为了避免冲突,需要加”_”符号
但可以用前面方法替代:soup.findAll("", {"class":"sister"})
针对参数recursive
默认True,当等于False的时候,只查询文档的一级标签
针对参数limit
+find()就是findAll()的limit参数等于1的时候get_text(),清除标签,即获取标签里的文本信息
第三周学习:re库
使用方法:
1.import re
2.match,正则中最基本的函数,用法:
result = re.match(pattern, 需要区配的字符串)
result.group()取出被区配到的部分
3.演示语法的时候,基本会用match函数演示。match区配的过程是:从左到右区配,直到出现不满足规则的时候停止
总结:这些特殊字符,需要反斜杠转义\ . ^ $ ? + * {} [] () |。建议字符串和正则规则都加上r,减少考虑字符串转义的麻烦
第四周学习:scrapy爬虫框架
爬虫框架
爬虫框架 是实现爬虫功能的一个软件结构和功能组件集合
爬虫框架 是一个半成品,能够帮助用户实现专业网络爬虫
5+2结构
- Scheduler
- 用户不修改
- 对所有爬取请求进行调度管理
- Engine
- 用户不修改
- 控制数据流,根据条件触发事件
- Downloader
- 用户不修改
- 根据请求下载网页
- Spider
- 用户配置代码
- 解析downloader返回的响应Response
- 产生爬取项scrapy item
- 产生额外的爬取请求Request
- Item-Piplines
- 用户配置代码
- 以流水线方式处理Spider产生的爬取项
- 由一组操作顺序组成,类似流水线
- 每个操作是一个Item Pipeline类型
- 操作:清理,检验和查重爬取项中的HTML数据,将数据存储到数据库
- Spider-middleware
- 用户配置代码
- 目的:对请求和爬取项在处理
- 功能:修改,丢弃,新增请求或爬取项
- Downloader-middleware
- 用户配置代码
- 用户可配置的控制,
- 修改,丢弃,新增请求或响应
3个数据流
简单配置,即可完成功能