<< Previous 分布式文件系统 从设计到实现 - 开篇
Next >> 分布式文件系统 从设计到实现 - Replication(二)
Partition与Replication是分布式系统设计中解决问题的主要方法。
Replication系列文章会聚焦:
- 系统为何复制,几种基本的复制方式
- gfs、hdfs在复制上的设计及异同比较
- hdfs复制流程的代码实现细节
为何复制
分布式系统使用复制(replicate)将数据传输到多个节点,以便:
- 某个副本(replica)所在节点失效(failure)时,其他节点的副本可以继续提供服务
- 分散服务访问、计算压力,提升带宽、性能
复制方法的分类
复制可以分为:
- 同步复制(synchronous replication)
- 异步复制(Asynchronous replication)
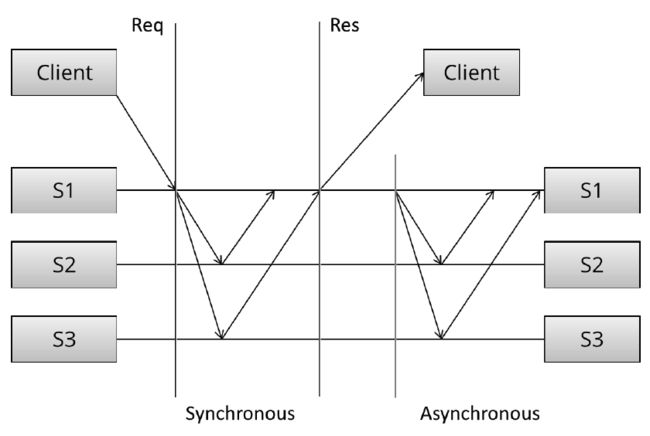
同步复制
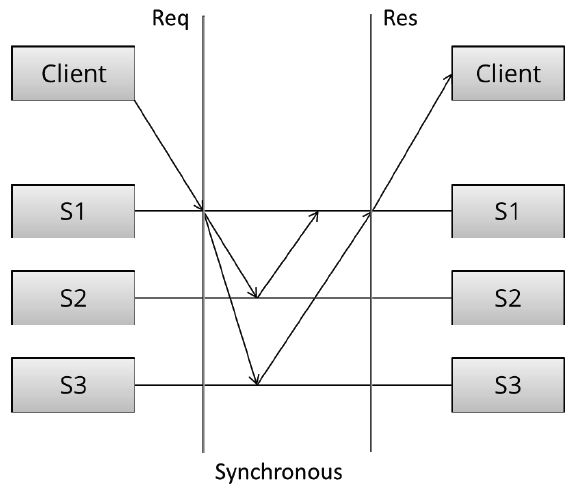
同步复制中,Client向S1写入数据,S1负责将数据复制到S2、S3。只有当S1收到S2、S3的成功回复后,S1才会给Client回复成功消息。
异步复制
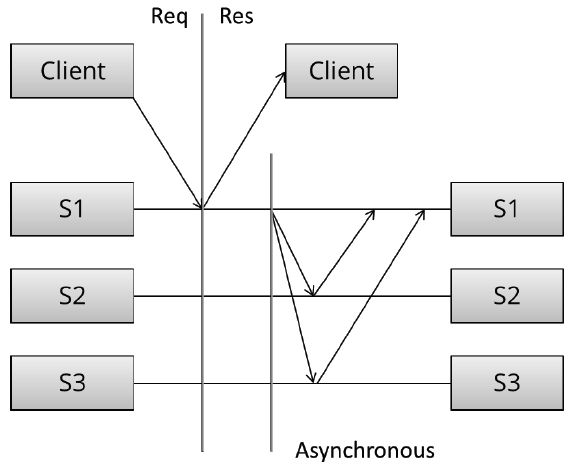
异步复制中, S1写入成功后立刻告知Client,然后才会将数据复制到S2、S3。
同步复制 vs. 异步复制
从数据可靠性(Reliability)、一致性(Consistency)的角度看:
同步复制,一旦Client写入成功,即可以确保系统存在多个数据副本,数据不易丢失[可靠性✔]。此时,无论Client访问S1还是S2、S3都可以读到相同的数据[一致性✔]。
异步复制,当Client得到写入成功消息时并不能确保系统中存在多个数据副本。也就是,如果此时Client立即访问S2或者S3,会存在无法读到刚刚写入数据的可能性[一致性✘]。另外,如果S1在数据复制到其他节点前失效,可能导致数据丢失[可靠性✘]。
从网络通信、写入延时角度看:
同步复制一次写入需要完成3个节点的通信(假设数据副本数为3)才能返回,网络延时叠加,写入速度慢。
而异步复制,因为Client没有等待复制的过程,写入速度快。
总体来看,
同步复制简单、直接,所有副本完成后,写入成功,同时带来写入速度较慢的副作用。
异步复制很暴力,一个副本完成后,即算写入成功,不理会副本在后台是否复制。所以在Client看来写入迅速,不会受到节点间网络延时的影响。但之后节点间副本复制过程会比较复杂,且存在单点失效数据丢失的风险。
介于两者之间
从论文上看[1],某些系统并不追求强一致性(strong consistency),而更看重可用性、性能等因素。它们采用了介于同步复制与异步复制之间的复制方法,实现弱一致性(weak consistency),比如Amazon Dynamo。
与上面两种复制方法一致,Dynamo的典型副本数N也为3。
不同之处在于,用户可根据业务需要自行选择写入/读取的副本数:R=读取副本数,W=写入副本数,且R+W>N。
即,用户可以选择N中的W个节点进行数据写入,W写入成功即返回。同时,读取时从N中指定R个节点读取副本,返回较新副本。
写入节点越多,写入速度下降,但数据可靠性上升。读取节点越多,读到最新数据的概率越大。
其中,要求R+W>N,保证读写节点中必有一个重叠节点。
比如,
R = 1 , W = N : 读快, 写慢(退化为同步复制)
R = N , W = 1 : 写快, 读慢
R = N/2 and W = N/2 + 1 : 读写均衡
类Dynamo系统的默认N-R-W:
Basho's Riak (N = 3, R = 2, W = 2 default)
Linkedin's Voldemort (N = 2 or 3, R = 1, W = 1 default)
Apache's Cassandra (N = 3, R = 1, W = 1 default)
下集预告:
本篇介绍了几种常见的复制方式,下篇开始结合具体的gfs、hdfs实例,看看真实系统中,复制如何进行。
[1]Distributed Systems for Fun and Profit
Next >> 分布式文件系统 从设计到实现 - Replication(二)
<< Previous 分布式文件系统 从设计到实现 - 开篇