Textbook:
《计算机组成与设计——硬件/软件接口》 HI
《计算机体系结构——量化研究方法》 QR
超标量
前面讲过超标量的概念。超标量的目的就是实现指令级并行(Instruction Level Parallelism),来解决stall太多的问题。
超标量(Super Scalar) 将一条指令分成若干个周期处理以达到多条指令重叠处理,从而提高cpu部件利用率的技术叫做标量流水技术。 超级标量是指cpu内一般能有多条流水线,借助硬件资源重复(例如有两套译码器和ALU等)来实现空间的并行操作。在单流水线结构中,指令虽然能够重叠执行,但仍然是顺序的,每个周期只能发射(issue)或退休(retire)一条指令。
超级标量结构的cpu支持指令级并行,一个周期可以发射多条指令(2-4条居多,也叫做多发射[multiple issue])。这样可以使得cpu的IPC(Instruction Per Clock)>1 (也就是CPI<1咯),从而提高cpu处理速度。超级标量机能同时对若干条指令进行译码,将可以并行执行的指令送往不同的执行部件(也就是说执行过程可以是乱序的)。我们熟知的pentium系列(可能是p-II开始),还有SUNSPARC系列的较高级型号,以及MIPS若干型号等都采用了超级标量技术。
实现多发射处理器也有两种方式,其区别是将主要工作分给编译器来做还是硬件来做。由千不同的实现方式将导致某些决策是静态进行的(在编译时)还是动态进行的(在执行时),所以这两种方式有时也被称为静态多发射( s tatic mul ti pl e issue) 和动态多发射(dynamic multiple issue) 。
理想情况下我们希望能有这么一个pipeline:

其中IF ID肯定只能是顺序执行(in order)的。MEM WB这部分也要顺序执行,毕竟指令的完成顺序不能乱嘛。
但是中间功能单元执行的环节其实可以乱序执行(out of order execution)。假设依次有指令A、B、C。A和B存在依赖,而C和前面的都没有依赖。因为A和B的依赖关系会导致流水线停顿,进而导致C也不能执行。如果指令可以乱序执行,就可以先执行C(指令在所需数据可用时立即开始执行),提高效率。
scoreboard system
scoreboard是一种古老的方法了...但其实现在在GPU的thread scheduling中仍然在用
......
Tomasulo Algorithm
这是目前的CPU中在广泛使用的方法。 QR P143
Tomasulo的核心思想是通过寄存器重命名来消除冒险,寄存器重命名功能由保留站(Reservation Station)提供。每个功能单元会有一个保留站。
- 每个保留站保存一条已经被发射,正在等待功能单元(EX)执行的指令。如果该指令的操作数值已经被算出了,也放到保留站里,否则保留站先记录这些操作数值对应的保留站名称。
- 保留站在一个操作数可用时马上缓冲一份,这样就可以为等待发射的指令缓冲操作数。
- 待执行的指令也会指定某个保留站作为自己的输入,并在发射指令是将寄存器更名为对应的保留站的名字,而不再依赖寄存器了。
- 在对寄存器进行连续写入时,只会用最后一个操作(也就是最终的值)来更新寄存器。
- 保留站的数量多于寄存器
一个使用了Tomasulo算法的浮点计算单元的结构如下: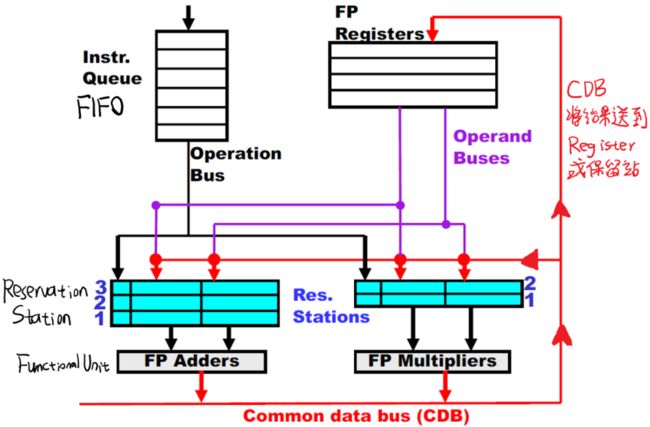
- 保留站相当于“虚拟寄存器”,来make copies of data。用于解决乱序执行时,不同指令公用同一个寄存器带来的冒险。解决Write After Write和Write After Read的依赖。
- Common Data Bus能够将数据同时Forward到多个位置,同时需要数据的保留站也能及时从Common Data Bus上得到自己需要的数据。解决Read After Write的依赖。
每个保留站会记录以下字段:
- Op:要执行的运算
- Qj, Qk:对于还没生成的源操作数,这里记录将生成源操作数的保留站号。
- Vj, Vk:对于已经available的源操作数,这里记录源操作数的值。
- A:记录load/store指令所需的地址
- Busy:表示该保留站在用
另外在每个寄存器中,也要加一个字段来记录 哪个保留站中的指令要修改当前寄存器。
之前提到过有三种数据冒险,我们来分别看看它们是如何被消除的:
1. Read after Write PPT P5-7
假设有这样的指令:
1: R2:=R0*R4 2: R3:=R0+R2 3: R0:=R1*R2
...
2. Write after Read(比如 r4=r1+r0 和 r0=r3+4) PPT P7-10
假设有这样的指令:
1: R3:=R0*R4 2: R4:=R3+R1 3: R1:=R0+R2
...
3. Write after Write(2个指令write the same register) PPT P11-15
假设有这样的指令:
1: R3:=R0*R4 2: R1:=R3+R1 3: R3:=R0+R2 4: R0:=R3*R2
...
Memory System Dependency
[PPT P15]
Tomasulo解决了寄存器中的依赖问题,但有些奇怪的指令(比如Load/Store)还可能造成内存的依赖,比如对同一个内存地址的RAW / WAR / WAW。这种用Tomasulo就搞不定了。因为有些情况下虽然内存地址不同,但实际上落到了同一个block(前面讲过),还是不能同时access。这种用Tomasulo就搞不定了。我们可以定义两个人工规则:
- Load:Proceed only when no prior instruction store to the same address
- Store:Proceed only when no prior instruction load/store to the same location
但是在load/store中也会设计地址的计算(也就是前面的ALU指令了)。因此我们把这个规则套用到tomasulo里面:
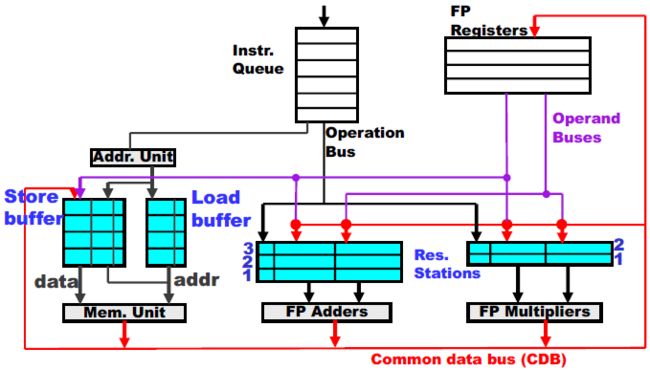
如图,Addr Unit负责计算地址,送入Store buffer和Load buffer。
以一个RAW的例子为例:
i1: R1 := load 0(R0) //write R1 i2: 0(R1) := store R2 //Read R1 when calculating address 0[R1]
...
...