1.注册中国大学MOOC
2.选择北京理工大学嵩天老师的《Python网络爬虫与信息提取》MOOC课程
3.学习完成第0周至第4周的课程内容,并完成各周作业
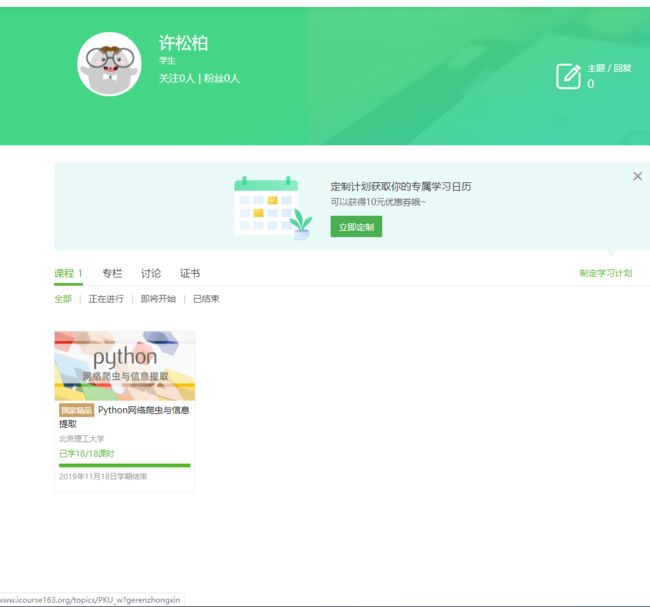
4.提供图片或网站显示的学习进度,证明学习的过程。
5.写一篇不少于1000字的学习笔记,谈一下学习的体会和收获。
Python是一种跨平台的计算机程序设计语言。是一种面向对象的动态类型语言,最初被设计用于编写自动化脚本(shell),随着版本的不断更新和语言新功能的添加,越来越多被用于独立的、大型项目的开发。
在上个学期我就初步的学习到了python。在新学期开始,我们随着新开的课程,逐步深入学习了python。并经由任课老师的推荐,我们在慕课网上学习嵩天老师的《Python网络爬虫与信息提取》,让我们了解学习了python爬虫,增长了我们的知识,提高了我们的能力。
我们通过四周的课程,学习python爬虫的规划、提取、实战和框架。
嵩天老师在第0周的课程中,向我们介绍了python的许多优秀的第三方库和框架,也让我们自行选择一个适合自己的python编译器,我安装使用了pycharm,以便进行接下来的课程学习。
在第一周课程中,我了解到了python的Requests库的七个主要方法:request,get,head,post,put,patch,delete,这是爬取网页的通用代码框架。也知道了网络爬虫的“盗亦有道”,建议遵守Robots协议,如果不遵守会存在法律风险。老师通过5个实例:京东商品页面的爬取、亚马逊商品页面的爬取、百度\360搜索关键字提交、网络图片的爬取和存储、IP地址归属地的自动查询,让我们学会了怎么以爬虫的视角看待网络世界。
在第二周课程中,我学习到了Beautiful Soup库的安装和使用。Beautiful Soup库是解析、遍历、维护“标签树”的功能库,熟练使用Beautiful Soup库能更好进行网络爬虫。关于信息标记与提取方法,老师介绍了信息标记的三种形式,并对这三种信息标记形式比较,让我们知道其中的异同。嵩天老师还通过“中国大学排名定向爬虫”的实例介绍,向我们生动体现了网络爬虫的提取操作,令人受益匪浅。
在第三周的课程中,我们进行了Re(正则表达式)库的入门。正则表达式是用来简洁表达一组字符串的表达式,它的优点就是简洁。在这周我学习到了正则表达式的十四个常用操作符和Re库的主要功能函数的功能以及Re库的贪婪匹配和最小匹配。然后通过淘宝商品比价定向爬虫和股票数据定向爬虫两个实例,让我们更能理解使用Re库。
在第四周的课程中,我学习到了Scrapy爬虫框架结构。所谓爬虫框架就是实现爬虫功能的一个软件结构和功能组件集合。爬虫框架是一个半成品,能够帮助用户实现专业的网络爬虫。比较requests库和Scrapy爬虫来说,选用哪个技术路线开发爬虫更适合呢?自然是要看情况,对于非常小的需求就要使用requests库,不太小的需求就使用Scrapy框架,定制很高的需求,requests库大于Scrapy框架。最后老师用一个实例:股票数据Scrapy爬虫,来使我们融会贯通。
网络爬虫是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。其实通俗的讲就是通过程序去获取web页面上自己想要的数据,也就是自动抓取数据。在跟随嵩天老师学习了《Python网络爬虫与信息提取》这门课程,可以为后续的大数据分析、挖掘、机器学习等提供重要的数据源,让我们以后能更好处理问题。
Python是一种跨平台的计算机程序设计语言。是一种面向对象的动态类型语言,最初被设计用于编写自动化脚本(shell),随着版本的不断更新和语言新功能的添加,越来越多被用于独立的、大型项目的开发。
在上个学期我就初步的学习到了python。在新学期开始,我们随着新开的课程,逐步深入学习了python。并经由任课老师的推荐,我们在慕课网上学习嵩天老师的《Python网络爬虫与信息提取》,让我们了解学习了python爬虫,增长了我们的知识,提高了我们的能力。
我们通过四周的课程,学习python爬虫的规划、提取、实战和框架。
嵩天老师在第0周的课程中,向我们介绍了python的许多优秀的第三方库和框架,也让我们自行选择一个适合自己的python编译器,我安装使用了pycharm,以便进行接下来的课程学习。
在第一周课程中,我了解到了python的Requests库的七个主要方法:request,get,head,post,put,patch,delete,这是爬取网页的通用代码框架。也知道了网络爬虫的“盗亦有道”,建议遵守Robots协议,如果不遵守会存在法律风险。老师通过5个实例:京东商品页面的爬取、亚马逊商品页面的爬取、百度\360搜索关键字提交、网络图片的爬取和存储、IP地址归属地的自动查询,让我们学会了怎么以爬虫的视角看待网络世界。
在第二周课程中,我学习到了Beautiful Soup库的安装和使用。Beautiful Soup库是解析、遍历、维护“标签树”的功能库,熟练使用Beautiful Soup库能更好进行网络爬虫。关于信息标记与提取方法,老师介绍了信息标记的三种形式,并对这三种信息标记形式比较,让我们知道其中的异同。嵩天老师还通过“中国大学排名定向爬虫”的实例介绍,向我们生动体现了网络爬虫的提取操作,令人受益匪浅。
在第三周的课程中,我们进行了Re(正则表达式)库的入门。正则表达式是用来简洁表达一组字符串的表达式,它的优点就是简洁。在这周我学习到了正则表达式的十四个常用操作符和Re库的主要功能函数的功能以及Re库的贪婪匹配和最小匹配。然后通过淘宝商品比价定向爬虫和股票数据定向爬虫两个实例,让我们更能理解使用Re库。
在第四周的课程中,我学习到了Scrapy爬虫框架结构。所谓爬虫框架就是实现爬虫功能的一个软件结构和功能组件集合。爬虫框架是一个半成品,能够帮助用户实现专业的网络爬虫。比较requests库和Scrapy爬虫来说,选用哪个技术路线开发爬虫更适合呢?自然是要看情况,对于非常小的需求就要使用requests库,不太小的需求就使用Scrapy框架,定制很高的需求,requests库大于Scrapy框架。最后老师用一个实例:股票数据Scrapy爬虫,来使我们融会贯通。
网络爬虫是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。其实通俗的讲就是通过程序去获取web页面上自己想要的数据,也就是自动抓取数据。在跟随嵩天老师学习了《Python网络爬虫与信息提取》这门课程,可以为后续的大数据分析、挖掘、机器学习等提供重要的数据源,让我们以后能更好处理问题。