一、主题式网络爬虫设计方案(15分)
1.主题式网络爬虫名称
爬取瓜子二手车相关信息
2.主题式网络爬虫爬取的内容与数据特征分析
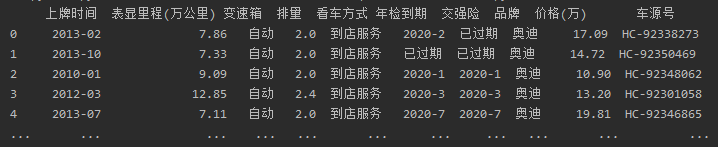
(1)获取'上牌时间', '表显里程', '变速箱', '排量', '看车方式', '年检到期', '交强险', '品牌','价格','车源号'内容
(2)关于品牌、变速箱与价格的透视表,排量、表显里程和价格的透视表及分别的可视化
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
实现思路:
(1)定义一个获取网页的函数get_html()来获取每个网页的内容
(2)使用正则表达式查找所需内容
技术难点:
瓜子二手车有反爬,所有难以获取其网页,只好找遍方法,才破解反爬
二、主题页面的结构特征分析(15分)
1.主题页面的结构特征
解析所有品牌的汽车,每个汽车品牌爬取当前页的数据

2.Htmls页面解析
所需数据在经过反爬后可以通过正则表达式获取

3.节点(标签)查找方法与遍历方法
全部数据通过正则表达式获得
三、网络爬虫程序设计(60分)
爬虫程序主体要包括以下各部分,要附源代码及较详细注释,并在每部分程序后面提供输出结果的截图。
1.数据爬取与采集
import requests import re import execjs from bs4 import BeautifulSoup import pandas as pd def get_html(url): # 定义一个获取网页的函数 try: ''' 因为该网站设置了反爬 所以需要解决该问题才能获取所需要的数据 ''' # 设置head头 header = { "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8", "Accept-Encoding": "gzip, deflate, br", "Accept-Language": "zh-CN,zh;q=0.9", "Connection": "keep-alive", "Host": "www.guazi.com", "Upgrade-Insecure-Requests": "1", "User-Agent": "Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3610.2 Safari/537.36", } response = requests.get(url=url, headers=header) # 设置返回的编码 response.encoding = 'utf-8' # 通过正则表达式获取了相关的字段和值 value_search = re.compile(r"anti\('(.*?)','(.*?)'\);") string = value_search.search(response.text).group(1) key = value_search.search(response.text).group(2) # 读取,我们破解的js文件 with open('guazi.js', 'r') as f: f_read = f.read() # 使用execjs包来封装这段JS,传入的是读取后的js文件 js = execjs.compile(f_read) js_return = js.call('anti', string, key) cookie_value = 'antipas=' + js_return header['Cookie'] = cookie_value response_second = requests.get(url=url, headers=header) return response_second.text except: print('爬取失败') def main(): # 获得全国的汽车品牌接口 url = 'https://www.guazi.com/www/buy/' html = get_html(url) req = r'href="\/www\/(.*?)\/c-1/#bread"\s+>(.*?)' # brand为所有品牌名称 brand = re.findall(req,html) # 匹配品牌链接的正则表达式 brand_url_req = r'filter=brand&brand=\w+?\s+?href="(.+?)"' brand_url = re.findall(brand_url_req,html) # 补全链接 https://www.guazi.com + 获取的网页链接 for i in range(len(brand_url)): brand_url[i] = 'https://www.guazi.com' + brand_url[i] # 使用pandas模块进行存放数据 column = ['上牌时间', '表显里程(万公里)', '变速箱', '排量', '看车方式', '年检到期', '交强险', '品牌','价格(万)','车源号'] s1 = pd.DataFrame(columns=column) num = 0 for each_url in brand_url: ''' 循环获得每个品牌的汽车的相关信息 包括'上牌时间', '表显里程', '变速箱', '排量', '看车方式', '年检到期', '交强险', '品牌','价格','车源号' ''' # 获取每个品牌的页面 each_html = get_html(each_url) each_req = r'href="(.*?)" target="_blank" class="car-a"' each_url = re.findall(each_req,each_html) # 补全url的链接 for i in range(len(each_url)): each_url[i] = 'https://www.guazi.com' + each_url[i] # 列名用了中文的缘故,不能对齐,故设置pandas的参数即可,两个参数默认都为False pd.set_option('display.unicode.ambiguous_as_wide', True) pd.set_option('display.unicode.east_asian_width', True) for car_url in each_url: # 获取每辆汽车的页面 car_html = get_html(car_url) ''' 搜索一些信息对应的数值 包含上牌时间,表显里程(万公里),变速箱,排量,看车方式,年检到期,交强险 ''' car_req0 = r'' car_req1 = r' (.*?).*?' car_req2 = r' (.*?).*?' car_req3 = r' (.*?).*?' car_req4 = r' (.*?).*?' car_req5 = r' (.*?).*?' car_req6 = r' (.*?).*?' car_li0 = re.findall(car_req0, car_html) car_li1 = re.findall(car_req1, car_html) car_li2 = re.findall(car_req2, car_html) car_li3 = re.findall(car_req3, car_html) car_li4 = re.findall(car_req4, car_html) car_li5 = re.findall(car_req5, car_html) car_li6 = re.findall(car_req6, car_html) # 获得价格的信息 price_req = r'¥(.*?)' car_price = re.findall(price_req,car_html) # 后面的空格去除 for i in car_price: new_car_price = i.rstrip() # 获得车源号 num_req = r' (.*?).*?车源号:(.*?)' car_num = re.findall(num_req,car_html) car_num = car_num[0].strip() ''' 每次添加一行数据 car_li = 2014-11 5.38万公里 自动 2.0 到店服务 2020-11 已过期 奥迪 价格 车源号 ''' try: s1 = s1.append({'上牌时间':car_li0[0],'表显里程(万公里)':car_li1[0],'变速箱':car_li2[0],'排量':car_li3[0],'看车方式':car_li4[0],'年检到期':car_li5[0],'交强险':car_li6[0],'品牌':brand[num][1],'价格(万)':new_car_price,'车源号':car_num}, ignore_index=True) except: pass s1.to_excel('guaz.xls') print('{}保存成功'.format(brand[num][1])) num += 1 if num == len(brand): break main()
2.对数据进行清洗和处理
导包及对pandas模块进行设置
import requests import pandas as pd import matplotlib.pyplot as plt # 列名用了中文的缘故,不能对齐,故设置pandas的参数即可,两个参数默认都为False pd.set_option('display.unicode.ambiguous_as_wide', True) pd.set_option('display.unicode.east_asian_width', True) # 显示所有的行和列,设置value的显示长度为1000,默认为50 pd.set_option('display.max_columns', 1000) pd.set_option('display.max_rows', 1000) pd.set_option('max_colwidth',100) # 设置使pandas打印出来不会换行 pd.set_option('display.width',1000) # 可视化时能显示中文 plt.rcParams['font.sans-serif'] = ['SimHei'] plt.rcParams['font.family']='sans-serif'# 读取excel中的内容,并保存到df中 df = pd.read_excel('guaz.xls') df.name='瓜子二手车'# 查看前五行,并显示数据大小 print(df.shape) print(df.head())
''' 查找是否有重复值 把重复值删除 ''' print(df.duplicated()) df = df.drop_duplicates()# 删除无用的列
df = df.drop('Unnamed: 0',axis=1)
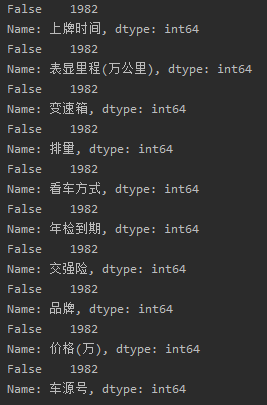
# 逐个查看每个列是否有空值或缺失值 for i in df: print(df[i].isnull().value_counts())
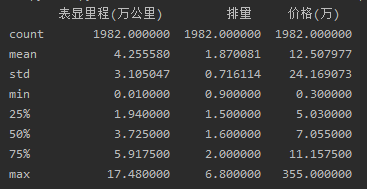
# 查看每栏的统计数据 print(df.describe())
# 查看爬取数据中变速箱的信息 print(df['变速箱'].value_counts())
3.文本分析(可选):jieba分词、wordcloud可视化
4.数据分析与可视化
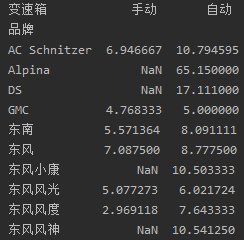
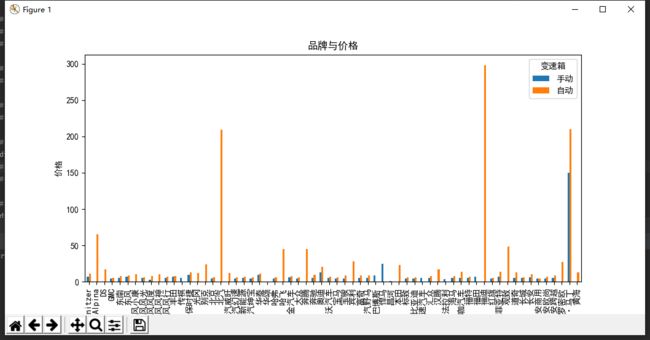
(例如:数据柱形图、直方图、散点图、盒图、分布图、数据回归分析等)# 关于品牌、变速箱与价格的透视表,以便在购车时的更好选择 df_pivot = df.pivot_table(index='品牌',columns='变速箱',values='价格(万)') df_pivot.shape print(df_pivot.head(10))
# 数据可视化 df_pivot.plot(kind='bar',title='品牌与价格') plt.xlabel('品牌') plt.ylabel('价格') plt.show()
# 查看排量最多的前15辆汽车,以作为购车的参考 print(df.sort_values('排量',ascending=False).head(15))
# 查看价格前15的汽车信息 print(df.sort_values('价格(万)',ascending=False).head(15))
# 查看所有汽车的品牌有哪些 a = [] for i in df['品牌']: a.append(i) # 将得到的汽车品牌存放到Series里 a_series = pd.Series(a).drop_duplicates() print(a_series.head(10))
# 查看表显里程和价格的分布情况
plt.scatter(df['表显里程(万公里)'],df['价格(万)']) plt.show()
5.数据持久化
# 将得到的数据保存到excel里
s1.to_excel('guaz000.xls')
6.附完整程序代码
四、结论(10分)
1.经过对主题数据的分析与可视化,可以得到哪些结论?(1)排量前15的大多都是北汽和观致品牌的汽车
(2)随社会发展,汽车越来越多使用自动挡
(3)表显里程对于二手车的出售价格有一定影响
(4)通过价格分析,大多数在网站出售的二手车,售价均少于50万
2.对本次程序设计任务完成的情况做一个简单的小结。关于爬虫,并没有我一开始想的那么简单。一开始我以为,主要知道网页的url,然后requests.get一下就能获取html页面了。没想到针对爬虫,许多网站都做了反爬处理,这着实让我抓瞎。后来通过网上的学习,我才破解了这个阻碍。通过这次学习我不仅将所学知识进行运用,还学习到了新知识,感觉到了自己的进步,期望自己将来能继续进步。