1.用Hive对爬虫大作业产生的文本文件(或者英文词频统计下载的英文长篇小说)进行词频统计。
启动Hive
2.在Hdfs上创建文件夹并查看

2.在Hdfs上创建文件夹并查看
3.把下载的英文小说novers.txt文件上传至hdfs

4.启动Hive
5.创建原始文档表,把文件内容导入到表fiction1中

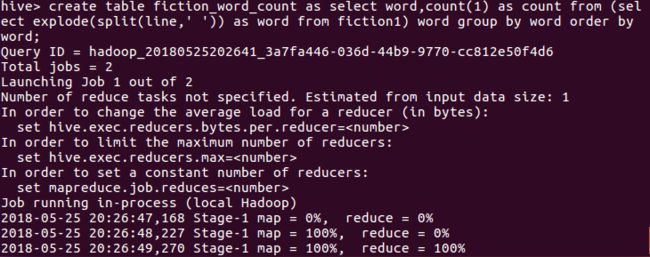
6.进行词频统计,结果放在表fiction_word_count里
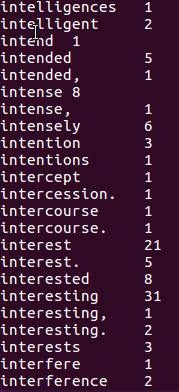
7.查看统计结果
![]()
补交作业:一:hive基本操作与应用
通过hadoop上的hive完成WordCount
启动hadoop
start-all.sh
Hdfs上创建文件夹
hdfs dfs -mkdir wcinput hdfs dfs -ls /user/hadoop
上传文件至hdfs
hdfs dfs -put ./dj.txt wcinput hdfs dfs -ls /user/hadoop/wcinput
启动Hive
hive
创建原始文档表
create table docs(line string);
导入文件内容到表docs并查看
load data inpath '/user/hadoop/wcinput/dj.txt' overwrite into table docs; select * from docs;
用HQL进行词频统计,结果放在表word_count里
create table word_count as select word,count(1) as count from (se
lect explode(split(line,' ')) as word from docs) word group by word order by word;
查看统计结果
show tables; select * from word_count;
二:熟悉常用的HBase操作,编写MapReduce作业
1. 以下关系型数据库中的表和数据,要求将其转换为适合于HBase存储的表并插入数据:
学生表(Student)(不包括最后一列)
| 学号(S_No) |
姓名(S_Name) |
性别(S_Sex) |
年龄(S_Age) |
课程(course) |
| 2015001 |
Zhangsan |
male |
23 |
|
| 2015003 |
Mary |
female |
22 |
|
| 2015003 |
Lisi |
male |
24 |
数学(Math)85 |
create 'Student', ' S_No ','S_Name', 'S_Sex','S_Age' put 'Student','s001','S_No','2015001' put 'Student','s001','S_Name','Zhangsan' put 'Student','s001','S_Sex','male' put 'Student','s001','S_Age','23' put 'Student','s002','S_No','2015003' put 'Student','s002','S_Name','Mary' put 'Student','s002','S_Sex','female' put 'Student','s002','S_Age','22' put 'Student','s003','S_No','2015003' put 'Student','s003','S_Name','Lisi' put 'Student','s003','S_Sex','male' put 'Student','s003','S_Age','24'
2. 用Hadoop提供的HBase Shell命令完成相同任务:
- 列出HBase所有的表的相关信息;list
- 在终端打印出学生表的所有记录数据;
- 向学生表添加课程列族;
- 向课程列族添加数学列并登记成绩为85;
- 删除课程列;
- 统计表的行数;count 's1'
- 清空指定的表的所有记录数据;truncate 's1'
scan 'Student' alter 'Student','NAME'=>'course' put 'Student','3','course:Math','85' dorp 'Student','course' count 's1' truncate 's1'
三:爬虫大作业
1.选一个自己感兴趣的主题。
2.用python 编写爬虫程序,从网络上爬取相关主题的数据。
3.对爬了的数据进行文本分析,生成词云。
4.对文本分析结果进行解释说明。
5.写一篇完整的博客,描述上述实现过程、遇到的问题及解决办法、数据分析思想及结论。
6.最后提交爬取的全部数据、爬虫及数据分析源代码。
from bs4 import BeautifulSoup
import logging
import sys
reload(sys)
sys.setdefaultencoding( "utf-8" )
class Item(object):
title = None #帖子标题
firstAuthor = None #帖子原作者
firstTime = None #帖子创建时间
reNum = None #帖子回复浏览数量
LastTime = None #帖子最后回复时间
LastAuthor = None #帖子最后回复作者
link = None #帖子链接
# 全局方法获取网页内容
def getResponseContent(url):
try:
response = urllib2.urlopen(url.encode('utf8'),timeout=20)
except:
logging.error(u'Python返回URL:{}数据失败'.format(url))
else:
logging.info(u'Python返回URL:{}数据成功'.format(url))
return response.read()
class getHupuInfo(object):
def __init__(self,url):
self.url = url
self.pageSum = 3
self.urls = self.getUrls(self.pageSum)
self.items = self.spider(self.urls)
self.pipelines(self.items)
def getUrls(self,pageSum):
urls = []
urls.append(self.url)
for pn in range(1,pageSum):
tempurl = self.url + '-'+ str(pn+1)
urls.append(tempurl)
logging.info(u'获取URLS成功!\n')
return urls
def spider(self,urls):
items = []
for url in urls:
htmlContent = getResponseContent(url)
soup = BeautifulSoup(htmlContent,'lxml')
tagtable = soup.find('table',attrs={'id':'pl'})
tagstr = tagtable.find_all('tr')
flag = 0
for tag in tagstr:
if flag == 0:
flag +=1
continue
else:
flag += 1
item = Item()
item.link = '/'+ tag.get('mid') + '.html'
item.title = tag.find('td', attrs={'class': 'p_title'}).find('a',href = item.link).get_text()
item.firstAuthor = tag.find('td', attrs={'class': 'p_author'}).a.get_text()
item.firstTime = tag.find('td', attrs={'class': 'p_author'}).get_text()
item.reNum = tag.find('td', attrs={'class': 'p_re'}).get_text()
item.LastAuthor = tag.find('td', attrs={'class': 'p_retime'}).a.get_text()
item.LastTime = tag.find('td', attrs={'class': 'p_retime'}).get_text()
items.append(item)
logging.info(u'获取帖子成功')
return items
def pipelines(self,items):
fileName = u'Hupu_bxj.txt'
with open(fileName,'w') as fp:
for item in items:
#fp.write('{}\t{}\t{}\t{}\t{}\t{}\n{}\n\n'.format(item.title,item.firstAuthor,item.firstTime,item.reNum,item.LastAuthor,item.LastTime,item.link))
fp.write('{}\n '.format(item.title).encode('utf8'))
logging.info(u'写入文本成功')
def getpiclink(self):
piclink = []
for item in self.items:
piclink.append(self.url[0:20] + item.link)
logging.info(u'返回图片帖子链接成功')
return piclink
class picInfo(object):
def __init__(self,links):
self.links = links
self.imgurls = []
self.spider()
self.pipeline()
def spider(self):
if self.links == None:
logging.error('无图片链接')
else:
for link in self.links:
htmlContent = getResponseContent(link)
soup = BeautifulSoup(htmlContent,'lxml')
tagDiv = soup.find('div',attrs={'id':'tpc'})
img = tagDiv.find('div',attrs={'class':'quote-content'}).find_all('img')
if img == None:
continue
else:
for subimg in img:
if subimg.get('data-original') == None:
imgurl = subimg.get('src')
else:
imgurl = subimg.get('data-original')
self.imgurls.append(imgurl)
logging.info(u'获取图片链接成功')
def pipeline(self):
for i in range(len(self.imgurls)):
if self.imgurls[i][-3:] == 'png':
imgname = str(i) + '.png'
elif self.imgurls[i][-3:] == 'jpg':
imgname = str(i) + '.jpg'
elif self.imgurls[i][-4:] == 'jpeg':
imgname = str(i) + '.jpeg'
elif self.imgurls[i][-3:] == 'gif':
imgname = str(i) + '.jpeg'
else:
continue
img = getResponseContent(self.imgurls[i])
with open (imgname, 'ab') as fp:
fp.write(img)
logging.info(u'写入图片成功')
if __name__ == '__main__':
logging.basicConfig(level= logging.INFO)
url = u'https://bbs.hupu.com/bxj'
HUPU = getHupuInfo(url)
picurls = HUPU.getpiclink()
PIC = picInfo(picurls)
四:熟悉常用的HDFS操作
- 在本地Linux文件系统的“/home/hadoop/”目录下创建一个文件txt,里面可以随意输入一些单词.
- 在本地查看文件位置(ls)
- 在本地显示文件内容
cd /usr/local/hadoop touch test1.txt cat test1.txt - 使用命令把本地文件系统中的“txt”上传到HDFS中的当前用户目录的input目录下。
./sbin/start-dfs.sh ./bin/hdfs dfs -mkdir -p /user/hadoop ./bin/hdfs dfs -mkdir input ./bin/hdfs dfs -put ./test1.txt input - 查看hdfs中的文件(-ls)
./bin/hdfs dfs -ls /input
- 显示hdfs中该的文件内容
./bin/hdfs dfs -cat input/test1.txt
- 删除本地的txt文件并查看目录
./bin/hdfs dfs -rm -ls input/test1.txt
- 从hdfs中将txt下载地本地原来的位置。
./bin/hdfs dfs -get input/test.txt ~/test1.txt
- 从hdfs中删除txt并查看目录
./bin/hdfs dfs -rm -ls input/test1.txt
向HDFS中上传任意文本文件,如果指定的文件在HDFS中已经存在,由用户指定是追加到原有文件末尾还是覆盖原有的文件;
if $(hdfs dfs -test -e text.txt); then $(hdfs dfs -appendToFile local.txt text.txt); else $(hdfs dfs -copyFromLocal -f local.txt text.txt); fi
从HDFS中下载指定文件,如果本地文件与要下载的文件名称相同,则自动对下载的文件重命名;
if $(hdfs dfs -test -e file:///home/hadoop/text.txt); then $(hdfs dfs -copyToLocal text.txt ./text2.txt); else $(hdfs dfs -copyToLocal text.txt ./text.txt); fi
将HDFS中指定文件的内容输出到终端中;
hdfs dfs -cat text.txt
显示HDFS中指定的文件的读写权限、大小、创建时间、路径等信息;
hdfs dfs -ls -h text.txt
给定HDFS中某一个目录,输出该目录下的所有文件的读写权限、大小、创建时间、路径等信息,如果该文件是目录,则递归输出该目录下所有文件相关信息;
hdfs dfs -ls -R -h /user/hadoop
提供一个HDFS内的文件的路径,对该文件进行创建和删除操作。如果文件所在目录不存在,则自动创建目录;
if $(hdfs dfs -test -d dir1/dir2); then $(hdfs dfs -touchz dir1/dir2/filename); else $(hdfs dfs -mkdir -p dir1/dir2 && hdfs dfs -touchz dir1/dir2/filename); fi 删除文件:hdfs dfs -rm dir1/dir2/filename
提供一个HDFS的目录的路径,对该目录进行创建和删除操作。创建目录时,如果目录文件所在目录不存在则自动创建相应目录;删除目录时,由用户指定当该目录不为空时是否还删除该目录;
创建目录:hdfs dfs -mkdir -p dir1/dir2 删除目录(如果目录非空则会提示not empty,不执行删除):hdfs dfs -rmdir dir1/dir2 强制删除目录:hdfs dfs -rm -R dir1/dir2
向HDFS中指定的文件追加内容,由用户指定内容追加到原有文件的开头或结尾;

追加到文件末尾:hdfs dfs -appendToFile local.txt text.txt 追加到文件开头: (由于没有直接的命令可以操作,方法之一是先移动到本地进行操作,再进行上传覆盖): hdfs dfs -get text.txt cat text.txt >> local.txt hdfs dfs -copyFromLocal -f text.txt text.txt
删除HDFS中指定的文件;
hdfs dfs -rm text.txt
删除HDFS中指定的目录,由用户指定目录中如果存在文件时是否删除目录;
删除目录(如果目录非空则会提示not empty,不执行删除):hdfs dfs -rmdir dir1/dir2 强制删除目录:hdfs dfs -rm -R dir1/dir2
在HDFS中,将文件从源路径移动到目的路径。
hdfs dfs -mv text.txt text2.txt
-
从HDFS中下载指定文件,如果本地文件与要下载的文件名称相同,则自动对下载的文件重命名;
if $(hdfs dfs -test -e file:///home/hadoop/text.txt); then $(hdfs dfs -copyToLocal text.txt ./text2.txt); else $(hdfs dfs -copyToLocal text.txt ./text.txt); fi
将HDFS中指定文件的内容输出到终端中;
hdfs dfs -cat text.txt
显示HDFS中指定的文件的读写权限、大小、创建时间、路径等信息;
hdfs dfs -ls -h text.txt
给定HDFS中某一个目录,输出该目录下的所有文件的读写权限、大小、创建时间、路径等信息,如果该文件是目录,则递归输出该目录下所有文件相关信息;
hdfs dfs -ls -R -h /user/hadoop
提供一个HDFS内的文件的路径,对该文件进行创建和删除操作。如果文件所在目录不存在,则自动创建目录;
if $(hdfs dfs -test -d dir1/dir2); then $(hdfs dfs -touchz dir1/dir2/filename); else $(hdfs dfs -mkdir -p dir1/dir2 && hdfs dfs -touchz dir1/dir2/filename); fi 删除文件:hdfs dfs -rm dir1/dir2/filename
提供一个HDFS的目录的路径,对该目录进行创建和删除操作。创建目录时,如果目录文件所在目录不存在则自动创建相应目录;删除目录时,由用户指定当该目录不为空时是否还删除该目录;
创建目录:hdfs dfs -mkdir -p dir1/dir2 删除目录(如果目录非空则会提示not empty,不执行删除):hdfs dfs -rmdir dir1/dir2 强制删除目录:hdfs dfs -rm -R dir1/dir2
向HDFS中指定的文件追加内容,由用户指定内容追加到原有文件的开头或结尾;
追加到文件末尾:hdfs dfs -appendToFile local.txt text.txt 追加到文件开头: (由于没有直接的命令可以操作,方法之一是先移动到本地进行操作,再进行上传覆盖): hdfs dfs -get text.txt cat text.txt >> local.txt hdfs dfs -copyFromLocal -f text.txt text.txt
- 删除HDFS中指定的文件;
hdfs dfs -rm text.txt
- 删除HDFS中指定的目录,由用户指定目录中如果存在文件时是否删除目录;
删除目录(如果目录非空则会提示not empty,不执行删除):hdfs dfs -rmdir dir1/dir2 强制删除目录:hdfs dfs -rm -R dir1/dir2
- 在HDFS中,将文件从源路径移动到目的路径。
hdfs dfs -mv text.txt text2.txt
- 删除HDFS中指定的文件;
-
四:数据结构化
import requests
from bs4 import BeautifulSoup
from datetime import datetime
import re
import pandas
#获取点击次数
def getClickCount(newsUrl):
newId=re.search('\_(.*).html',newsUrl).group(1).split('/')[1]
clickUrl="http://oa.gzcc.cn/api.php?op=count&id={}&modelid=80".format(newId)
clickStr = requests.get(clickUrl).text
count = re.search("hits'\).html\('(.*)'\);", clickStr).group(1)
return count
#获取新闻详情
def getNewsDetail(newsurl):
resd=requests.get(newsurl)
resd.encoding='utf-8'
soupd=BeautifulSoup(resd.text,'html.parser')
news={}
news['title']=soupd.select('.show-title')[0].text
# news['newsurl']=newsurl
info=soupd.select('.show-info')[0].text
news['dt']=datetime.strptime(info.lstrip('发布时间:')[0:19],'%Y-%m-%d %H:%M:%S')
news['click'] = int(getClickCount(newsurl))
if info.find('来源')>0:
news['source'] =info[info.find('来源:'):].split()[0].lstrip('来源:')
else:
news['source']='none'
if info.find('作者:') > 0:
news['author'] = info[info.find('作者:'):].split()[0].lstrip('作者:')
else:
news['author'] = 'none'
# news['content']=soupd.select('.show-content')[0].text.strip()
#获取文章内容并写入到文件中
content=soupd.select('.show-content')[0].text.strip()
writeNewsContent(content)
return news
def getListPage(listPageUrl):
res=requests.get(listPageUrl)
res.encoding='utf-8'
soup=BeautifulSoup(res.text,'html.parser')
newsList=[]
for news in soup.select('li'):
if len(news.select('.news-list-title'))>0:
a=news.select('a')[0].attrs['href']
newsList.append(getNewsDetail(a))
return (newsList)
#数据写入文件
def writeNewsContent(content):
f=open('gzccNews.txt','a',encoding='utf-8')
f.write(content)
f.close()
def getPageNumber():
ListPageUrl="http://news.gzcc.cn/html/xiaoyuanxinwen/"
res=requests.get(ListPageUrl)
res.encoding='utf-8'
soup=BeautifulSoup(res.text,'html.parser')
n = int(soup.select('.a1')[0].text.rstrip('条'))//10+1
return n
newsTotal=[]
firstPage='http://news.gzcc.cn/html/xiaoyuanxinwen/'
newsTotal.extend(getListPage(firstPage))
n=getPageNumber()
for i in range(n,n+1):
listUrl= 'http://news.gzcc.cn/html/xiaoyuanxinwen/{}.html'.format(i)
newsTotal.extend(getListPage(listUrl))
df=pandas.DataFrame(newsTotal)
# df.to_excel("news.xlsx")
# print(df.head(6))
# print(df[['author','click','source']])
# print(df[df['click']>3000])
sou=['国际学院','学生工作处']
print(df[df['source'].isin(sou)])