本文是《Streaming Systems》第二章的输出,这章的内容也基本来自 Streaming 102: The world beyond batch(当时还叫做 DataFlow 模型,现在已经统称为 Beam 模型了),DataFlow 在当时是唯一一个能体现这篇文章理论的引擎,不过在现在,当时的那些概念(观点)在很多系统中都有了相应的体现。
RoadMap
为了更好地理解 Streaming System 的内容,作者提出了五个基本的概念,其中有两个已经在第一章介绍过了:event-time 和 process-time 区分和联系以及 window:
- 对 event-time 的理解非常重要,可以说它是后面的基础,如果你比较关注正确性和 event 实际发生的真实时间,那么分析数据与其 event time 的关系就非常重要,这种情况下 process time 是没有太大意义的;
- window 是处理无限流的通用方法。
除了这两个概念,还有三个重要的概念:
- Trigger:类似于一个控制信号,它灵活地控制一个 window 什么时候进行触发来输出结果;
- Watermark:是关于输入 完整性 定义的一个概念(是针对 event-time 时间域),时间为 X 的 watermark 表示 event time 小于 X 的数据都被接收到了;
- Accumulation:这个比较难解释,针对一个时间段,同一个 window,多次结果输出之间的关系(或者说是:后到的数据如何应影响之前的结果)。
理解上面这些概念之间的关系并不难,这里会通过下面四个问题,把前面这五个概念串一下,这四个问题也是每个 Unbounded data processing system 都会面临的问题:
- What results are calculated?:This question is answered by the types of transformations within the pipeline(这段话我也没有太理解,我个人的理解是:对结果进行计算的操作是什么,答案是 transformation,它是一种抽象,可以是求和、构建直方图或 AI 模型训练等);
- Where in event time are results calculated?:计算什么时间范围内的数据(这个时间指的是 event-time)?解决方法是 event-time window;
- When in processing time are results materialized?:什么时间输出结果(这里的时间指的是 process time)?解决方法是 trigger+watermark;
- How do refinements of results relate?:后到的数据如何影响之前的结果,对于同一个 window,这些输出结果之间的关系是什么样的?这就是 Accumulation 做的事情。
本章下面将对上面的问题做更深入一些探讨。
Batch Foundations:What and Where
先看下 batch processing,batch process engine 就可以回答 what 和 where 的问题。
What: Transformations
本文中所涉及的例子都会以 Beam 伪代码的形式给出,不过它们跟 Flink 和 Spark 都很相似。在 Beam 中有两个基本的概念抽象:
- PCollections:它代表了在并发 transform 中可以处理的数据集(possibly massive ones);
- PTransforms:它是应用到 PCollections 上,来执行的转换操作,会生成新的 PCollections。PTransforms 可以是对元素一个一个操作,也可以是聚集(agg)操作,还可以是包含其他 PTransforms 的聚合操作,如下图所示:

本章会用一个示例做讲解,示例使用的数据源如下:
> SELECT * FROM UserScores ORDER BY EventTime;
------------------------------------------------
| Name | Team | Score | EventTime | ProcTime |
------------------------------------------------
| Julie | TeamX | 5 | 12:00:26 | 12:05:19 |
| Frank | TeamX | 9 | 12:01:26 | 12:08:19 |
| Ed | TeamX | 7 | 12:02:26 | 12:05:39 |
| Julie | TeamX | 8 | 12:03:06 | 12:07:06 |
| Amy | TeamX | 3 | 12:03:39 | 12:06:13 |
| Fred | TeamX | 4 | 12:04:19 | 12:06:39 |
| Naomi | TeamX | 3 | 12:06:39 | 12:07:19 |
| Becky | TeamX | 8 | 12:07:26 | 12:08:39 |
| Naomi | TeamX | 1 | 12:07:46 | 12:09:00 |
------------------------------------------------
该数据源的 event-time 及 process time 的关系如下:

这里我们是希望计算这个球队的总分数。
这里使用了一个名叫 input 的 PCollection 作为输入( input 是由 Team/Integer 作为键/值对组成的,Team 是球队名,Interger 是每人的分数),对于 batch process,其代码实现如下:
PCollection raw = IO.read(...);
PCollection> input = raw.apply(new ParseFn());
PCollection> totals =
input.apply(Sum.integersPerKey());
执行过程可以见:Classic batch processing(gif 动图,可以点击查看)。
因为是 batch pipeline,它直到接收到所有的输入才会输出计算结果,最后输出的结果是48,从上面的图中也可以看到:state 和 output 的矩形覆盖了整个 x 轴。如果我们要处理的数据源是 unbounded data,那么这种模式将无法 work,我们不可能等到所有输入结束,这就是 window 要解决的问题。
Where: Windowing
第一章已经已经介绍了,windowing 是沿着时间边界对数据源进行切片的过程,window 主要有以下三种:

window 在 Beam 中的使用非常简单,这里我们使用一个 2min 的 fixed window,其实现如下:
// Windowed summation code
PCollection> totals = input
.apply(Window.into(FixedWindows.of(TWO_MINUTES)))
.apply(Sum.integersPerKey());
Beam 提供了一个在 batch 和 streaming 上统一的模型,在 batch engine 执行上的代码,其处理过程见:Windowed summation on a batch engine(gif 动图),与前面不同的是,这里切分的四个窗口上都有对应的输出。
Going Streamings: When and How
前面看到了 batch engine 下的 window 操作,但是在理想情况下,我们是希望延迟尽可能的低,并且希望能够处理无限流的情况,这就是需要转向 Streaming Engine,之前需要等待全部输入完成再输出结果的模式将无法接受。但是 Streaming Engine 也有一些问题需要去解决,比如:结果什么时候输出?数据的完整性怎么定义?这就需要 trigger 和 watermark 机制。
When: The Wonderful Thing Abort Triggers Are Wonderful Things!
Trigger declare when output for a window should happen in processing time.
上面这句话需要好好理解,尽管 trigger 本身可能是在 event-time 这个时间域上确定的,但是它最后的表现是:确定何时(指的是 process time)输出一个 window 的结果。虽然 trigger 可能有多种不同的语义,但从概念上讲,通常是只有两种类型的 trigger:
- Repeated update triggers:可以是每接收一条新数据就触发一次,或者按 process time 周期性处理(比如:1min 一次),具体的设置取决于 latency 和 cost 之间的权衡;
- Completeness triggers:它代表一个 window 内的数据接收完成之后做一次触发,比如在批处理中,不过它是把整个批看做一个 window。
Repeated update triggers 是 streaming system 中最常见的使用类型,也是最容易实现和理解的类型,提供的语义是 repeated updates to a materialized dataset(它适合的也是这种场景)。
Completeness triggers 使用得比较少,提供了一个跟典型批处理场景一致的 streaming 语义,它们也提供了一个工具处理晚到或丢失的数据,这个在后面的 watermark 中间介绍。
首先看一个 repeated update trigger 的例子,这里跟之前的代码比添加的内容是:每接收一条新的 record 就做一次 trigger,示例如下:
// Triggering repeatedly with every record
PCollection> totals = input
.apply(Window.into(FixedWindows.of(TWO_MINUTES))
.triggering(Repeatedly(AfterCount(1))));
.apply(Sum.integersPerKey());
执行过程见:Per-record triggering on a streaming engine,如果下游只是获取最新的数据,那么这种类型的 trigger 是可以满足需求(它会把最新的结果写到结果表中,下游每次获取时拿到的都是最新的数据),而且随着时间的推移结果将会变得更加准确。
上面这种模式在应对大规模的数据集时,是非常消耗资源的,而根据 process-time 周期性地输出结果是更加适合大数据量场景,比如:按分钟输出。在 Beam 中这又分为两种情况:
- aligned delays:delay 的时间点完全是根据 process-time 切分的;
- unaligned delays:delay 是跟该窗口观察到数据的 process-time 相关的。
这里看下第一种情况,代码实现如下:
// Triggering on aligned two-minute processing-time boundaries
PCollection> totals = input
.apply(Window.into(FixedWindows.of(TWO_MINUTES))
.triggering(Repeatedly(AlignedDelay(TWO_MINUTES)))
.apply(Sum.integersPerKey());
它的执行过程见:Two-minute aligned delay triggers (i.e., microbatching)(动图),最后的结果如下图(从动图中截取的):

按照 process-time 每 2min 就触发一次结果输出,这种 aligned delays 的优点是:有点像 spark streaming,它的输出时间点是可预测的,我们会同时得到所有 window 的更新。但是缺点也很明显,所有的更新同时触发,这会导致负载不均衡,峰值的负载非常高。
因此,有了另一个可替代的方案:unaligned delays,示例如下:
PCollection> totals = input
.apply(Window.into(FixedWindows.of(TWO_MINUTES))
.triggering(Repeatedly(UnalignedDelay(TWO_MINUTES))
.apply(Sum.integersPerKey());
其执行过程见:Two-minute unaligned delay triggers(动图),截取了动图中最后的一个结果,如下图所示:
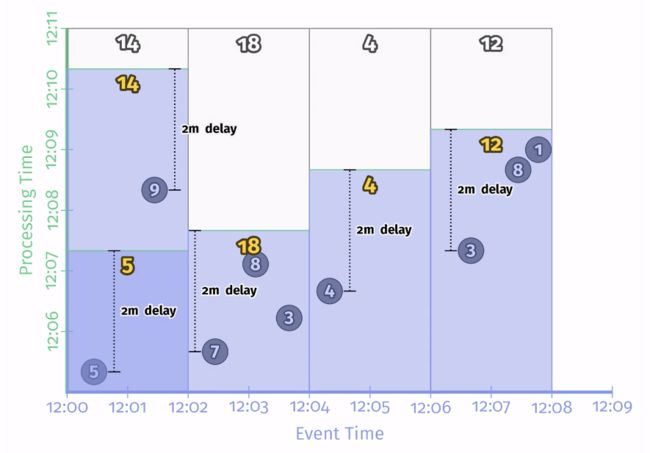
这里也是每 2min 就触发一次结果输出,但它初始时间是由该 window 接收的第一条数据的时间决定,因为输入数据在时间分布上是打散的,最后会使得触发的时间点相对来说比较均衡。关于延迟的话,这两者延迟的差异可能为正也可能为负,最后平均下来应该是差不多的。对于大规模数据集场景,这种模式显然是更加适合的。
最后,总结一下,repeated update trigger 适合这样的场景:只是简单地、周期性地随时间更新结果输出;对【最终会不断接近准确性,但什么时间达到准确性是不知道的】这种特性是可以接受的。由于分布式系统的一些特性,这会导致 process-time 和 event-time 之间的延迟无法预测,我们也很难推理出什么时候当前的输出是由一个完整的、正确的输入计算得到的,我们需要有一种方法去推理【完整性】而不是盲目相信输出的结果。
When: Watermarks
Watermarks are a supporting aspect of the answer to the question: “When in processing time are results materialized?” Watermarks are temporal notions of input completeness in the event-time domain.
Watermark 要解决的问题如上面的引用所示,这也是关于 watermark 的解释。
我们可以把 watermark 当作一个函数:输入一个 process time,它返回一个 event time。假设输出的 event-time 是 E,它表示所有 event time 小于 E 的输入都已经接收到了,也就是说,event time 小于 E 的数据将会被认为不会再接收到。根据 watermark 的类型,分为以下两种:
- perfect watermark: 在这种情况下,我们知道所有输入数据的情况,因此也就不会有任何的数据延迟;
- heuristic watermark:对于分布式的数据源,了解所有输入数据的情况是不现实的,heuristic watermark 利用数据源的已有情况(partition、ordering、文章增长率等)尽可能地估计其进度,它也意味着有时候输出的结果是错误的,因为会有 late data。
Watermark 提供了一个与输入相关的 Completeness 概念,watermark 也成为构建了前面介绍的 completeness trigger 的基础。这里有一个示例:
// Watermark completeness trigger
PCollection> totals = input
.apply(Window.into(FixedWindows.of(TWO_MINUTES))
.triggering(AfterWatermark()))
.apply(Sum.integersPerKey());
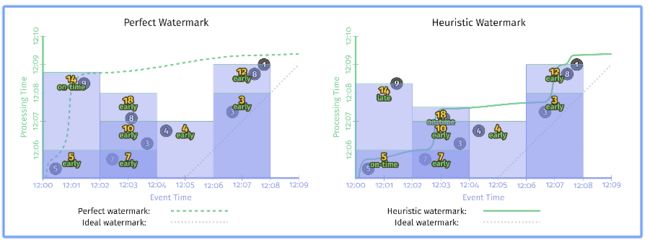
Perfect watermark 是一个理想情况,在现实中,达到 perfect watermark 的代价是非常大的,所以我们一般会选择一个 heuristic watermark。当然,无论哪种情况,当 watermark 到达 window 的结尾时,当前 window 的结果就可以输出了(认为该窗口的所有数据都已经接收到了,可以做进一步的处理),正如上面的例子所示,但是两种类型的 watermark 最后的计算结果是不一样的(执行过程见:Windowed summation on a streaming engine with perfect (left) and heuristic (right) watermarks,动图),程序执行结束时的情况如下图所示:

在右边的结果中,9 成了 late data,被丢弃掉,也导致了最后的结果是不准确的。而且在实际中,基于 event-time 的 watermark 的选择本来就是一个难题,如果按照 process-time 去 delay 一段时间,也同样会导致这个问题。关于 watermark 有两个典型的问题:
- Too Slow:如上面图中左边所示,watermark 需要等待的时间会非常长,如果 watermark 由于未到的数据而延迟,那么它会导致最后输出结果的延迟;
- Too Fast:如果 watermark 发出的比较早,可能会导致 event-time 小于 watermark 的数据(输入时有延迟)成为 late data,从而导致结果的不准确性,如上面图中右边所示,对于比较关心正确性场景,仅仅依赖 watermark 来确定什么时候输出远远是不够的(也就是用户需要按照自己的策略处理 late data)。
这里对完整性的概念做了进一步的讲述,但是对于无限、无序的数据源来说,仅仅做到完整性是不够的,因为不可能仅仅依赖完整性就能达到低延迟和完整性输出的目标。如果想要同时做到两者应该怎么做呢?到这里我们清楚的是:
- repeated update trigger:提供低延迟的 update,但无法解决完整性的问题;
- watermark:提供完整性的概念,但通常伴随着高延迟。
为什么不把两者结合起来呢?
When: Early/On-Time/Late Triggers FTW
前面已经介绍了两种类型的 trigger:repeated update triggers 和 completeness/watermark triggers,在实际中,两者单独使用是不够的,通常是结合在一起使用的。Beam 提供了一个标准 watermark trigger 的扩展,它可以在 watermark 的任何一边支持 repeated update watermark。这里把这种复杂的 trigger 分为了以下三种情况:
| 类型 | 说明 | 解释 | 特点 |
|---|---|---|---|
| Zero or more early panes | which are the result of a repeated update trigger that periodically fires up until the watermark passes the end of the window | 在 watermark 达到 window 的结尾处(end)前会不断触发(repeated update trigger),它意味着在这之后将不会再触发,所以是【early pane】 | 弥补了 watermark too slow 的问题 |
| A single on-time pane | which is the result of the completeness/watermark trigger firing after the watermark passes the end of the window | 在 watermark 到达 window 结尾处进行触发(它是 Completeness/watermark trigger 触发的结果) | 这个触发是比较特殊的,因为它做了假定:系统现在认为这个 window的输入是已经完成的 |
| Zero or more late panes | which are the result of another (possibly different) repeated update trigger that periodically fires any time late data arrive after the watermark has passed the end of the window | 它是另一种类型的 repeated update trigger,在 watermark 到达 window 结尾处再触发,对于 perfect watermark,它触发0次;但是对于 heuristic watermark,任何晚到的数据都会导致一个 late firing。 | 它弥补了 watermark too fast 的不足。 |
这里以一个示例来说明,下面的示例添加两种类型的 trigger:一个是每分钟周期性的 early firing,另一个是每条数据来就触发的 late firing,实现如下所示:
// Early, on-time, and late firings via the early/on-time/late API
PCollection> totals = input
.apply(Window.into(FixedWindows.of(TWO_MINUTES))
.triggering(AfterWatermark()
.withEarlyFirings(AlignedDelay(ONE_MINUTE))
.withLateFirings(AfterCount(1))))
.apply(Sum.integersPerKey());
执行过程见:Windowed summation on a streaming engine with early, on-time, and late firings(动图),在动图中最后截取的一张图如下所示:
无论是哪种的 watermark,随着时间推移都有了很大的改进,相对来说,也减少了相应的延迟。但这里还有一个问题——window 的生命周期,每个 window 都是维护一定状态信息的,这是需要占用一定资源,在很多情况下,该窗口是不能一直存活的,对于 perfect watermark 是没有问题,但是对于 heuristic watermark 就不是那么容易了,到现在为止,我们还没有一个很好的方法去评估一个窗口应该保留的周期。
When: Allowed Lateness
Any real-world out-of-order processing system needs to provide some way to bound the lifetimes of the windows it’s processing. A clean and concise way of doing this is by defining a horizon on the allowed lateness within the system; that is, placing a bound on how late any given record may be (relative to the watermark) for the system to bother processing it; any data that arrives after this horizon are simply dropped.
需要给 window 设置生命周期的原因在前面已经讲述过了,每个 window 的 state 是不可能无限期保留的,一个是存储资源不允许,另一个是旧的数据随着时间其价值也会下降。
任何处理真实、乱序数据的处理系统,都需要提供一个方法来定义处理 window 的生命周期边界,一个简单的方法是:对于这个系允许延迟的时间点上定义一个界限(horizon)。超过这个界限的数据将会被丢弃,这相当于也限制了 window 状态的保留时间(watermark 超过 the end of window 后再超过自定义的时间后,window 就可以彻底关闭了,相关状态也会被清除),有了这个之后,系统就不会
为不关心的数据(延迟太多,以及没有意义的数据)浪费资源。
在 event-time 时间域上指定一个 horizon 虽然看起来有些奇怪,但它却是目前可行方案中最好的一个,它可以降低 window 错过处理晚到数据的机会。如果使用 process-time,中间出现了 crash(导致延迟了几分钟),可能会导致这些应该处理的数据变成了 late data 而没有及时去处理。
这里的 watermark,指的是 low watermark,它试图找到系统中已知的、最老的未处理 record 的 event-time。不管 event-time skew 如何变化,low watermark 总是去寻找系统中已知的、最旧的未处理 event 的 event-time。
关于 low watermark,可以通过这个例子理解:对于 event-time 为 12:00 的那批数据,可能分布在 process-time 上的多个位置,假设 process-time 是在 12:00~12:10之间,假设现在 process-time 为12:10,当前已知的最旧的数据的 event-time 为 12:00,那么这个时间点的 low watermark 就是 12:00;
并不是所有系统的 watermark 都是 low watermark,比如 structured streaming 里的 watermark 指的是 high watermark,它表示系统已知的最新 record 的 event time。在处理延迟时,系统可以回收那些比 high watermark 老得超过一个自定义阈值的 window。它确定了 event-time skew 的最大值,超过这个 skew window 的数据都会被丢弃。
关于high watermark,这里也通过一个例子来理解:假设现在 process-time 为12:10,当前已知的最新的数据的 event-time 为 12:10,那么这个时间点的 high watermark 就是 12:10(可能 low watermark 是 12:00,如前面 low watermark 中的例子)。
「allowed lateness」和「watermark」之间的关系有些微妙,这里让我们再看一个示例,与前面相比,这里又增加了一个 1min 的 lateness horizon:
// Early/on-time/late firings with allowed lateness
PCollection> totals = input
.apply(Window.into(FixedWindows.of(TWO_MINUTES))
.triggering(
AfterWatermark()
.withEarlyFirings(AlignedDelay(ONE_MINUTE))
.withLateFirings(AfterCount(1)))
.withAllowedLateness(ONE_MINUTE))
.apply(Sum.integersPerKey());
处理过程见:Allowed lateness with early/on-time/late firings(动图),下面是最后面得一张截图:

当 watermark 到达一个 window 的 lateness horizon 时,比如:对于 event-time 为 [12:00~12:02] 的 window,其 lateness horizon 的 even-time 为12:03(图中的虚线),也就是说,当 event-time 超过 12:03 时,这个 window 就彻底关闭了,该 window 的状态将不会再维护了。
- 如果 watermark 是 perfect watermark,那么这里将 lateness horizon 设置为0就是最佳的;
- 在指定 lateness horizon 的规则时,有一个需要注意的是:对于那种需要在随着时间统计全局数据的例子(比如:统计网站随着时间变化的总访问次数),这种情况下这个 window 是跟键值绑定在一起的,只要这个键值的数量控制在一定范围内,就没有必要通过 lateness horizon 去限制 window 的生命周期。
How: Accumulation
When triggers are used to produce multiple panes for a single window over time, we find ourselves confronted with the last question: “How do refinements of results relate?”
在前面的例子中,每个 pane 的新数据都建立在紧邻的前一个 pane 的数据之上。但是,实际上是有三种不同的更新模式:
| 类型 | 说明 | 适用场景 |
|---|---|---|
| Discarding | 一旦一个 pane 是物化之后,那么存储的 state 将会被丢弃,会生成一个新的 pane,它是不依赖之前的 state | 它适用这种场景,比如:如果下游 consumer 是自己做一些聚合操作,由下游自己去做相应的处理,比如:求和操作 |
| Accumulating | 之前的 state 会持续保留,未来的输入会反映到已经存在的 state 上,比如:最后结果更新到 k/v 存储上,像 HBase 或 Bigtable | 适合这种场景:使用新值直接覆盖之前的结果,新值是包含目前看到的所有数据 |
| Accumulating and retracting | 不但会 accumulate,还会修改之前错误的结果(之前的错误结果可能已经对下游产生了影响,比如 group 操作修改前后可能去到不同的分组、对于动态窗口,旧值可能会涉及多个 window) | 这种机制最复杂,但功能也是最强大的 |
这里来看一个使用 Discarding 的示例,这种模式下,没有一个 window 是重叠的,如果当前的 window 有新的数据来,即使这个 window 之前已经关闭了,这里还会再新建一个窗口,将新到来的数据放到这个窗口里,发送到下游,对于这个时间点的 window 来说,它们都是独立存在的。
// Discarding mode version of early/on-time/late firings
PCollection> totals = input
.apply(Window.into(FixedWindows.of(TWO_MINUTES))
.triggering(
AfterWatermark()
.withEarlyFirings(AlignedDelay(ONE_MINUTE))
.withLateFirings(AtCount(1)))
.discardingFiredPanes())
.apply(Sum.integersPerKey());
处理过程见:Discarding mode version of early/on-time/late firings on a streaming engine。
这里看下 Accumulating and retracting 模式,其处理过程见:Accumulating and retracting mode version of early/late firings on a streaming engine。
// Accumulating and retracting mode version of early/on-time/late firings
PCollection> totals = input
.apply(Window.into(FixedWindows.of(TWO_MINUTES))
.triggering(
AfterWatermark()
.withEarlyFirings(AlignedDelay(ONE_MINUTE))
.withLateFirings(AtCount(1)))
.accumulatingAndRetractingFiredPanes())
.apply(Sum.integersPerKey());
这种把这三种模式列出来做一个对比,如下图所示,它们三者按顺序其存储和计算成本是逐渐变高的。具体应该选择哪种模式,是需要在正确性、latency 和 cost 之间做一个 trade-off。

Summary

参考:
- 《Streaming Systems》,本文的图片和内容都来自这本书的第二章。