一、Hbase简介
1、什么是Hbase
Hbase的原型是google的BigTable论文,收到了该论文思想的启发,目前作为hadoop的子项目来开发维护,用于支持结构化的数据存储。
Hbase是一个高可靠性(存储在hdfs上,有副本机制),高性能,面向列,非关系型的数据库(类似redis),可伸缩的分布式存储系统(因为是存储在hdfs上),利用hbase技术可在廉价PC server上搭建大规模结构化的数据库存储集群。
Hbase的目标是存储并处理大型的数据,更具体来说仅需使用普通的硬件,就能够处理由成千上万行和列所组成的大型数据。
Hbase是基于hdfs构建的分布式存储框架,但是Hbase在hdfs上实现随机的读写改,解决了hdfs不支持的东西
2、Hbase的特点
A、海量存储
B、列式存储
这里的列式存储其实说的是列族存储,Hbase是根据列族来存储数据的,列族下面可以有非常多的列,列族在创建表的时候必须指定
Hbase中的列和mysql的列不是一个东西,Hbase的列就是他的数据
C、极易扩展
Hbase的扩展性主要体现在两个方面,一个是基于上层的梳理能力的扩展(RegionServer,相当于datanode,处理读写请求),一个是基于存储的扩展(hdfs)
通过横向添加RegionServer的机器,进行水平扩展,提升Hbase上层的处理能力,提升Hbase服务更多的Region的能力。
备注:RegionServer的作用是管理Region)(类似mysql中的表的概念),承接客户端的读写请求的访问,这个后面会详细的介绍通过横向添加datanode的机器,进行存储层的扩容,提升Bhbase的存储能力和提升后端存储的读写能力
D、稀疏
稀疏主要是针对于hbase列的灵活性,在列族中,你可以指定任意多的列,在列数据为空的情况下,是不会占用存储空间的,这里和mysql等数据库不一样,mysql如果每个字段没有值,那这个字段的值为null,不为空,且会占用存储空间
3、Hbase的架构
Hbase的架构示意图如下

Hbase由HMaster和HRegionServer组成,HMaster的高可用也依赖于zk,类似于hdfs中的Namenode;
HRegionServer相当于hdfs中的datanode,实际处理读写请求的节点;
a、Zookeeper
HBase通过zk来做Hmaster的高可用,RegionServer的监控,元数据的入口以及集群配置的维护等工作,具体工作入下
通过zk来保证集群中只有一个master在运行,如果master异常,会通过竞争机制产生新的master提供服务
通过zk来监控RegionServer的状态,当RegionServer有异常的时候,通过回调的形式通知master,RegionServer上下线的信息
通过zk存储元数据的统一入口地址;
b、HMaster
为RegionServer分配Region
维护集群的负载均衡,就是分配Region
维护集群的元数据信息
发现失效的Region,并将失效的Region分配到正常的RegionServer上
当RegionServer失效的时候,协调对应的Hlog和hdfs的block进行数据恢复
C、HRegionServer
HRegionServer直接对接用户的读写请求,是真正的干活的节点,他的功能概括如下
管理master为其分配的Region
处理来自客户端的读写请求
负责和底层hdfs的交互,存储数据到hdfs中
负责Region变大后的拆分
负责Storefile的合并工作
D、HDFS
Hdfs为hbase提供最终的底层数据存储服务
提供元数据和表数据的底层分布式存储服务
数据的多副本,保证高可靠和高可用
E、Hlog
一个HRegionServer中只有一个Hlog,Hlog相当于hdfs中的edits文件,保存Hbase的修改记录,当对Hbase写数据的时候,数据不是直接写进磁盘,他会在内存中保留一段时间(时间i将数据量的阈值可以设定)。但把数据保存在内存中可能有更高的概率引起数据丢失,为了解决这个问题,数据会先写在一个叫做Hlog的文件中,Hlog存储在磁盘上,也位于hdfs上,然后在写入内存,所以在系统出现故障或者内存丢失的时候,数据可以通过这个日志文件进行重建
F、Region
Region相当于mysql中的表,一个HRegionServer可以有多个Region,一个HRegionServer会有多个Region;如果表的数据太大,会进行拆分,按照数据量平均切分,所有HBase中的一张表会对应一个或者多个Region,当表的内容很小,一张表就对应一个Region,如果表很大的话,则这个Region会切分,切分Region会同时拆分这个Region的所有Store。
G、Store
Store相当于列族,通俗的讲就是列的家族,在hbase中,想创建一个列,必须要指定列族,也就是一个列必须属于某个列族。一个表中可以有多个列族,一个store对应一个列族,hbase官方不建议多个列族,一个列族就可以搞上百个列,足够用了。但是如果一个HRegion被切分的话,是切分列族,所以就算一个HRegion只有一个列表,切分后一个Region也会对应多个Store,多个strore会被分配到其他的HRegionServer节点进行存储
H、MemStore
MemStore就是列族中的数据放在内存中,写数据来了,会写到内存中,只要内存写入成功,则就返回。
I、StoreFile
StoreFile,数据放在内存不安全,而且有大小限制,所以需要把内存中的数据写到磁盘中,以Hfile的格式存储在hdfs上。每次memstore刷一次,形成一个storefile,所以storefile会很多,但是很小,因为内存本身就不大,后面storeFile也会合并,但是这个合并也仅仅是一个列族内部的StoreFile进行合并,不会跨列族合并的
J、HFile
这是磁盘上保存的原始数据的实际的物理文件,是实际的存储文件,storefile是以Hfile的形式存储在hdfs中
二、Hbase安装
1、首先要安装zk
2、 然后要安装hdfs
3、 最后在安装hbase
4、 解压,修改配置文件
这里重点说下修改配置文件,前面的就不说了,因为我在实际使用过程中使用ambari工具来进行安装
首先修改hbase-env.sh
配置java的环境变量
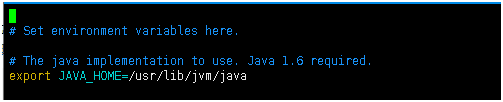
export JAVA_HOME=/usr/lib/jvm/java
配置zk,Hbase也是强依赖于zookeeper的,是否要启用自己的zookeeper。如果用则为true,如果用外部的zookeeper,则为false

export HBASE_MANAGES_ZK=false
配置hbase-site.xml

hbase.rootdir /apps/hbase/data
配置hbase是否启用集群

hbase.cluster.distributed true
设置Hbase的服务的端口号,不是 web的端口号,web的端口号是16010

hbase.master.info.port 16010

hbase.master.port 16000
配置要连接的zk

hbase.zookeeper.quorum abdi1,abdi2,abdi3
Zk存储数据的父目录,主要是为了区分多个hbase集群

zookeeper.znode.parent /hbase-unsecure
配置regionservers文件
指定RegionServer的节点

由于hbase是强依赖于hdfs的,需要拷贝hdfs的配置文件到hbase的conf目录
我们一般情况会这样操作,创建一个软链接,链接到hdfs的core-site.xml和hdfs-site.xml中,就是让hbase知道我要连接哪个hadoop集群
![]()
但是在ambari安装的hbase的配置文件中没有找到相应的配置,但是在hbase启动的时候有加载hdfs的环境变量
![]()
启动hbase,可以看到有Hmaster和HRegionServer的java进程

ambari的web页面显示效果如下

注意:Hbase的Master和RegionServer安装是一样的,只是看我们是否要启动master
Hbase的web页面,采用16010端口

三、Hbase的简单shell操作
1、进入hbase shell
[root@abdi2 bin]# /usr/hdp/current/hbase-client/bin/hbase shell
2、查看当前有哪些表:list
hbase(main):003:0> list TABLE 0 row(s) Took 0.2713 seconds => [] hbase(main):004:0>
3、创建表操作。这里的列族是必须要指定的,就是和mysql的列一样:create "student","info"
hbase(main):004:0> create "student","info" Created table student Took 1.3445 seconds => Hbase::Table - student hbase(main):005:0> hbase(main):006:0> list TABLE student 1 row(s) Took 0.0055 seconds => ["student"]


4、插入数据。Hbase中的数据没有什么类型,比如字符串,hash等,全部是字节:put "student","1001","info:name","laowang"
hbase(main):007:0> put "student","1001","info:name","laowang" Took 0.1217 seconds hbase(main):008:0> put "student","1001","info:age","18" Took 0.0038 seconds hbase(main):009:0> put "student","1001","info:sex","male" Took 0.0049 seconds hbase(main):010:0> put "student","1002","info:name","laoluo" Took 0.0036 seconds hbase(main):011:0> put "student","1002","info:age","20" Took 0.0035 seconds

5、扫描查看数据:scan “student”

6、扫描查看数据,指定起始和截止Rowkey,前闭后开

7、查看指定Rowkey

8、查看指定行的指定列

9、更新数据

10、查看表结构
重点关注列族和版本即可,这里的版本是个数的意思,就一条数据存储几个版本
![]()
11、修改列族的版本信息

多更新几次数据

可以查看到有多个版本,这里的意思查看3个版本的数据,所以有三条,下面的命令是查看2个版本的数据,所以有两条

12、删除操作
删除某个Rowkey的指定列,可以看到其他列的数据还在,删除还可以指定时间戳,该时间戳之前的数据都会被删除

删除Rowkey对应的所有数据

13、统计条数
统计条数,Rowkey有几个,条数就有几条

14、清空表

15、删除表

16、命名空间(namespace)操作
命令空间,相当于数据库中的database
所有的表都是命名空间的成员,如果不指定,则默认在default的命名空间中
命名空间可以设置权限,比如定义访问控制列表,例如创建表,读取表,删除,更新操作,权限用的很少
Shell命令查看namespace、创建namespace

Hbase就是存储元数据的命名空间,是系统自己用的,不能给用户使用
在指定命名空间下建表


四、Hbase的数据结构
1、Rowkey
Rowkey是用来检索记录的主键,访问Hbase table中的行,只有三种方式
A、 通过单个Rowkey访问
B、 通过Rowkey的range访问
C、 全表扫描
设计Rowkey非常重要也是Hbase里最重要的一门学问,数据会按照Rowkey的字典序排序进行存储,所以设计Rowkey要利用这个特性,把经常一起读取的行存储在一起,学习Hbase,Rowkey设计是学习的重点
2、Column Family
列族,Hbase表中的每个列,都会属于某个列族,列族是表的结构的一部分,列族在建表的时候必须要指定。列名都是以列族做为前缀。
在创建表的时候需要指定列族,列族可以指定多个
3、Cell
由Rowkey,column Family:column,version唯一确定的单元,cell中的数据是没有类型的,全部都是字节的形式存储
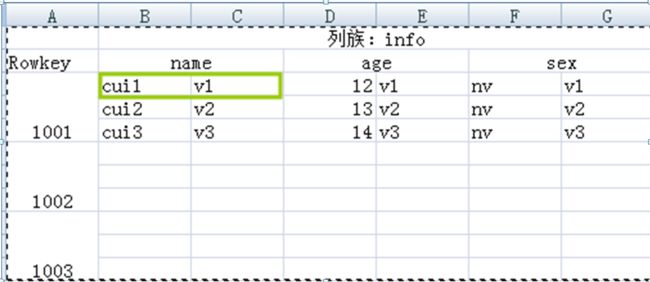
4、Time Stamp
时间戳,每个cell都保存着同一份数据的多个版本,版本通过时间戳来索引。时间戳可以由系统生成,也可以自己指定。每个cell中,不同版本的数据按照时间倒序排列,即最新的数据在最前面
通过时间戳不同来确定版本的
五、Hbase的原理
Hbase的写比读还快
1、读流程,hmaster没有关系,hmaster挂掉后,不影响读流程

a、先获取meta表的位置,也就元数据这张表存储的位置
b、去meta表所在位置获取meta表的信息,meta表存储的内容大致入下
Student 0 ----10000 rs1
Student 100001---20000 rs2
Stff 0---10000 rs3
Stff 10000—200000 rs4
c、然后在去对应的regionserver获取对应的数据
d、获取数据,先去内存中获取,如果内存中没有,到blockcache中获取,如果blockcash没有,则去磁盘获取,这里为什么先去内存获取数据?
e、返回数据的时候,先把数据写到blockcache中,然后在返回给client
Meta表的位置

Zk上查看meta表的存储位置

查看meta表的内容

2、写流程,和Hmaster没有关系
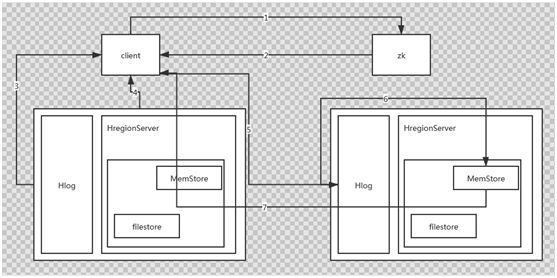
a、client到zk获取meta表的位置
b、Zk返回meta表的位置
c、Zk去regionserver读取meta表的内容
d、Regionserver将meta表的内容返回
e、去对应的regionserver开始执行写操作,先写Hlog文件,然后写到memstore,成功后,立刻返回,写入流程完成
因为先写到内存中,那么什么时候会刷到硬盘中呢
a、Regionserver的使用的总内存达到堆内存的40%

b、满足一个小时的条件,会刷memstore到硬盘中

c、单个region里的所有的Memstore加起来达到128MB,则会刷memstore到硬盘中

这样就会有很多小文件刷到hdfs中,但是hdfs不适合存储很多的小文件
默认是7天做一次合并


超过7天合并storefile文件
超过3个storefile文件,会进行合并
这个是合并一个列族的的storefile,不同列族的storefile文件不会进行合并的
3、高可用
Hmaster是Active和standby模式

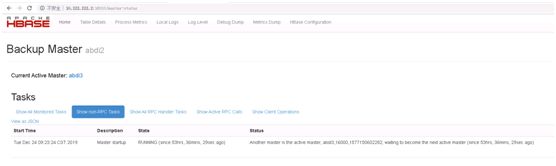
高可用配置

扫描查看数据