1.概述
最近有很多同学给笔者留言,说在安装Kafka Eagle的时候,会遇到一些问题,请教如何解决?今天笔者就在这里总结一下安装步骤,和一些安装的注意事项,以及解决方式。
2.内容
在安装Kafka Eagle之前,可能新接触的同学对Kafka Eagle不太了解,那我们现在简要介绍一下Kafka Eagle。
源代码地址:https://github.com/smartloli/kafka-eagle (感兴趣的同学可以关注一波)
2.1 Kafka Eagle是什么?
Kafka Eagle是一款用于监控和管理Apache Kafka的完全开源系统,目前托管在Github,由笔者和一些开源爱好者共同维护。它提供了完善的管理页面,很方面的去管理和可视化Kafka集群的一些信息,例如Broker详情、性能指标趋势、Topic集合、消费者信息等。
同时,兼容若干Kafka版本,例如0.8,0.9,...,以及截止到2019-12-16最新发布的2.4.0版本。
2.2 Kafka Eagle包含哪些功能?
Kafka Eagle监控管理系统,提供了一个可视化页面,使用者可以拥有不同的角色,例如管理员、开发者、游客等。不同的角色对应不同的使用权限。在知道了Kafka Eagle的作用之后,那么它包含哪些功能呢?核心功能如下所示:
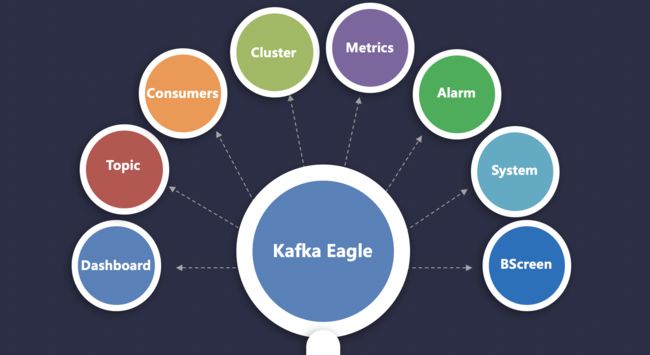
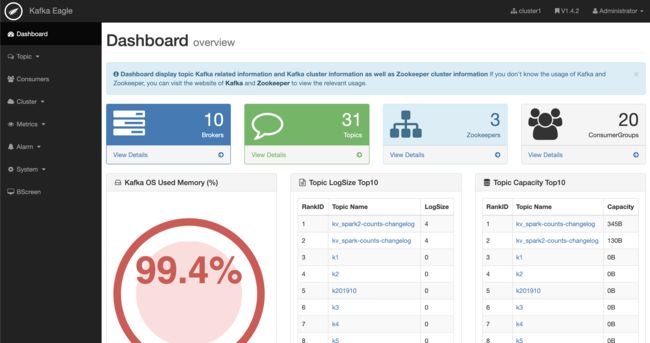
2.2.1 数据面板
负责展示Kafka集群的Broker数、Topic数、Consumer数、以及Topic LogSize Top10和Topic Capacity Top10数据。
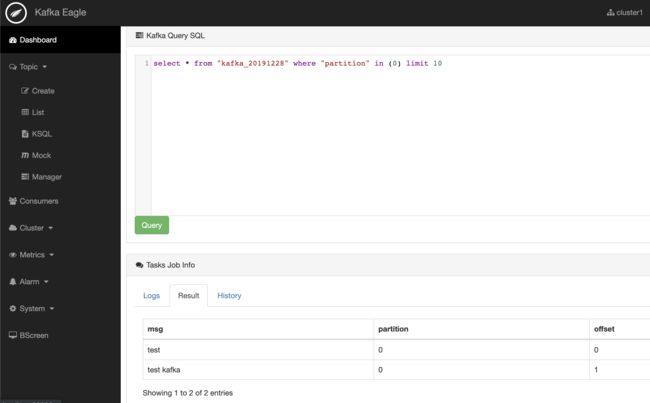
2.2.2 主题
该模块包含主题创建、主题管理、主题预览、KSQL查询主题、主题数据写入、主题属性配置等。
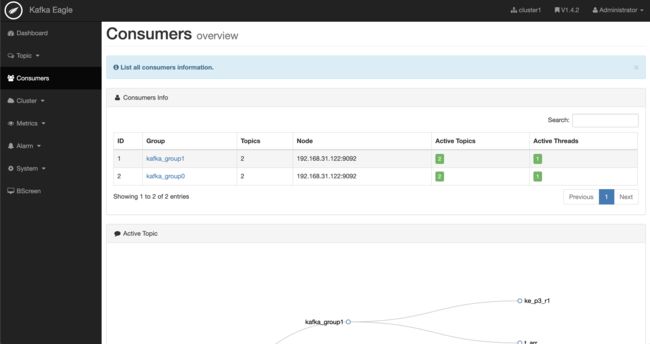
2.2.3 消费者组
该模块包含监控不同消费者组中的Topic被消费的详情,例如LogSize、Offsets、以及Lag等。同时,支持查看Lag的历史趋势图。
2.2.4 集群管理
该模块包含Kafka集群和Zookeeper集群的详情展示,例如Kafka的IP和端口、版本号、启动时间、Zookeeper的Leader和Follower。同时,还支持多Kafka集群切换,以及Zookeeper Client数据查看等功能。
2.2.5 指标监控
该模块包含监控Kafka集群和Zookeeper集群的核心指标,包含Kafka的消息发送趋势、消息大小接收与发送趋势、Zookeeper的连接数趋势等。同时,还支持查看Broker的瞬时指标数据。
2.2.6 告警
该模块包含告警集群异常和消费者应用Lag异常。同时,支持多种IM告警方式,例如邮件、钉钉、微信、Webhook等。
2.2.7 系统管理
该模块包含用户管理,例如创建用户、用户授权、资源管理等。
2.2.8 数据大屏
该模块包含展示消费者和生产者当日及最近7天趋势、Kafka集群读写速度、Kafka集群历史总记录等。
3.Kafka Eagle如何安装?
Kafka Eagle安装部署非常方便,可以从官网下载最新版本进行安装,或者从Github下载最新的Release源代码进行编译安装。
例如,从官网下载Kafka Eagle安装包,按如下命令操作即可:
# 解压安装包
tar -zxvf kafka-eagle-v1.4.2-bin.tar.gz
然后,是配置环境变量,这里需要注意的是,KE_HOME和JAVA_HOME均需在环境变量文件中进行配置(建议在~/.bash_profile文件中进行设置好,否则,可能在启动的时候抛出环境变量找不到的错误),配置内容如下:
# 配置JAVA_HOME和KE_HOME: vi ~/.bash_profile export JAVA_HOME=/hadoop/jdk8 export KE_HOME=/hadoop/kafka-eagle export PATH=$PATH:$JAVA_HOME/bin:$KE_HOME/bin
接下来是配置Kafka Eagle的系统文件,这里需要注意一些事项,配置内容如下:
###################################### # 设置Kafka多集群,这里只需要设置Zookeeper, # 系统会自动识别Kafka Broker ###################################### kafka.eagle.zk.cluster.alias=cluster1 cluster1.zk.list=127.0.0.1:2181 cluster2.zk.list=127.0.0.1:2181/plain cluster3.zk.list=127.0.0.1:2181/scram cluster4.zk.list=vmn4:2181 ###################################### # Zookeeper线程池最大连接数 ###################################### kafka.zk.limit.size=25 ###################################### # Kafka Eagle的页面访问端口 ###################################### kafka.eagle.webui.port=8048 ###################################### # 存储消费信息的类型,一般在0.9版本之前,消费 # 信息会默认存储在Zookeeper中,所以存储类型 # 设置zookeeper即可,如果是在0.10版本之后, # 消费者信息默认存储在Kafka中,所以存储类型 # 设置为kafka。而且,在使用消费者API时,尽量 # 客户端Kafka API版本和Kafka服务端的版本保持 # 一致性。 ###################################### cluster1.kafka.eagle.offset.storage=kafka cluster2.kafka.eagle.offset.storage=kafka #cluster3.kafka.eagle.offset.storage=kafka cluster4.kafka.eagle.offset.storage=kafka ###################################### # 开启性能监控,数据默认保留30天 ###################################### kafka.eagle.metrics.charts=true kafka.eagle.metrics.retain=30 ###################################### # KSQL查询Topic数据默认是最新的5000条,如果 # 在使用KSQL查询的过程中出现异常,可以将下面 # 的false属性修改为true,Kafka Eagle会在 # 系统中自动修复错误。 ###################################### kafka.eagle.sql.topic.records.max=5000 kafka.eagle.sql.fix.error=false ###################################### # 删除Kafka Topic时需要输入删除密钥,由 # 管理员执行 ###################################### kafka.eagle.topic.token=keadmin ###################################### # 开启Kafka ACL特性,例如SCRAM或者PLAIN, # 一般生产环境会使用SCRAM来做ACL,应为SCRAM # 可以动态创建和管理用户。 ###################################### cluster1.kafka.eagle.sasl.enable=false cluster1.kafka.eagle.sasl.protocol=SASL_PLAINTEXT cluster1.kafka.eagle.sasl.mechanism=SCRAM-SHA-256 cluster1.kafka.eagle.sasl.jaas.config=org.apache.kafka.common.security.scram.ScramLoginModule required username="admin" password="admin-secret"; cluster1.kafka.eagle.sasl.client.id= cluster2.kafka.eagle.sasl.enable=true cluster2.kafka.eagle.sasl.protocol=SASL_PLAINTEXT cluster2.kafka.eagle.sasl.mechanism=PLAIN cluster2.kafka.eagle.sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required username="admin" password="admin-secret"; cluster2.kafka.eagle.sasl.client.id= ###################################### # 存储Kafka Eagle元数据信息的数据库,目前支持 # MySQL和Sqlite,默认使用Sqlite进行存储 ###################################### kafka.eagle.driver=com.mysql.jdbc.Driver kafka.eagle.url=jdbc:mysql://127.0.0.1:3306/ke?useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull kafka.eagle.username=root kafka.eagle.password=123456 #kafka.eagle.driver=org.sqlite.JDBC #kafka.eagle.url=jdbc:sqlite:/Users/dengjie/webserver/hadoop/sqlite/ke.db #kafka.eagle.username=root #kafka.eagle.password=root
最后是启动,执行命令如下:
# 启动Kafka Eagle系统,执行如下命令: ke.sh start
同时,我们还可以执行其他的命令,参数如下:
# 查看Kafka Eagle运行状态 ke.sh status # 停止Kafka Eagle ke.sh stop # 查看Kafka Eagle GC情况 ke.sh gc # 查看Kafka Eagle服务器资源占用情况,例如TCP、句柄等 ke.sh stats # 查看Kafka Eagle版本号 ke.sh version # 查看Kafka Eagle服务器上JDK的编码情况(如果JDK编码不是UTF-8,可能会有异常出现,执行如下命令,根据提示来修复JDK编码问题) ke.sh jdk # 查看Kafka Eagle中是否存在某个类(如果需要精确,类名前面可以加上包名) ke.sh find [ClassName]
4.总结
总的来说,Kafka Eagle提供了简单、易用的页面,部署方便。同时,提供非常详细的操作手册,根据官网提供的操作手册来安装Kafka Eagle,一般都可以正常使用。另外,有时候可能会在日志中发现一些连接超时或是空指针异常,对于这类问题,首先需要检测Kafka集群的各个Broker节点JMX_PORT是否开启(这个Kafka默认是不开启),然后就是空指针异常问题,这类问题通常发生在Kafka集群配置了ACL,这就需要认真检测Kafka Eagle配置文件中ACL信息是否正确(比如设置的用户名和密码是否正确,以及用户是否拥有访问Topic的权限等)
vi kafka-server-start.sh ... if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then export KAFKA_HEAP_OPTS="-server -Xms8G -Xmx8G -XX:PermSize=128m -XX:+UseG1GC -XX:MaxGCPauseMillis=200 -XX:ParallelGCThreads=8 -XX:ConcGCThreads=5 -XX:InitiatingHeapOccupancyPercent=70" # 开启JMX_PORT端口,端口开启后,Kafka Eagle系统会自动感知获取 export JMX_PORT="9999" # 注释脚本中默认的信息 # export KAFKA_HEAP_OPTS="-Xmx1G -Xms1G" fi
如果大家对Kafka Eagle感兴趣,可以关注一波。后续,在Github上笔者也会公布每个版本的开发计划,修复大家在issues上面提的需求和问题,将Kafka Eagle建设的更加完善、易用。
Kafka Eagle源代码地址:https://github.com/smartloli/kafka-eagle
5.结束语
这篇博客就和大家分享到这里,如果大家在研究学习的过程当中有什么问题,可以加群进行讨论或发送邮件给我,我会尽我所能为您解答,与君共勉!
另外,博主出书了《Kafka并不难学》和《Hadoop大数据挖掘从入门到进阶实战》,喜欢的朋友或同学, 可以在公告栏那里点击购买链接购买博主的书进行学习,在此感谢大家的支持。关注下面公众号,根据提示,可免费获取书籍的教学视频。