单实例安装
下载
zookeeper使用Java编写,依赖的JDK版本为1.6+,因此zookeeper的运行需要Java环境的支持。
可以在以下网站下载到zookeeper的安装包
apache镜像
下载到的安装包为:zookeeper-3.4.8.tar.gz,在linux下用tar命令解压
tar zxvf zookeeper-3.4.8.tar.gz
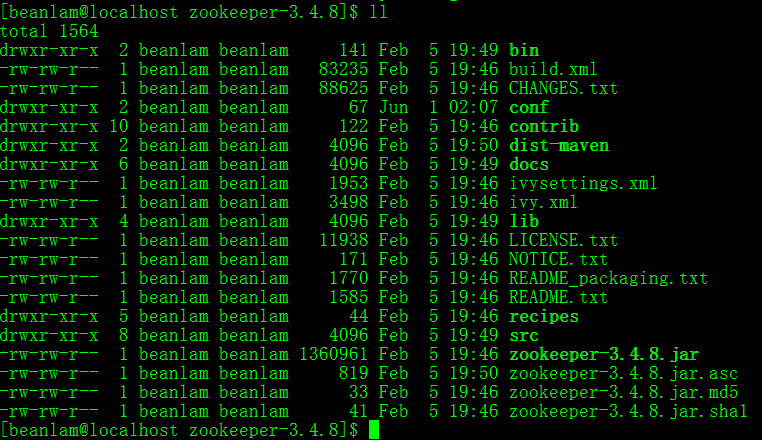
其中bin目录包含了一些脚本,用来运行zookeeper的主程序、客户端,以及环境变量配置的脚本。
conf目录,见名思义,放置了配置文件。
lib目录,包含了zookeeper运行时所需要依赖的jar包。
运行一下
conf目录下包含了一个文件zoo_sample.cfg,然而它并不是真正的配置文件,只是一个配置文件的范例。
启动zk server的时候,如果不显式指定启动时的配置文件,默认为使用conf目录下的zoo.cfg文件作为配置文件。
可是conf目录下并没有啊,因此首先要把文件改下名:
mv conf/zoo_sample.cfg conf/zoo.cfg
接下来切换到bin目录下,启动zookeeper
./zkServer.sh start

有时候我觉得每次都要切换到bin目录,然后敲命令,挺麻烦的。所以会做一些alias,爱护手指,减少打字。编辑自己home目录下的.bash_profile文件,加上

然后source一下,让它立即生效
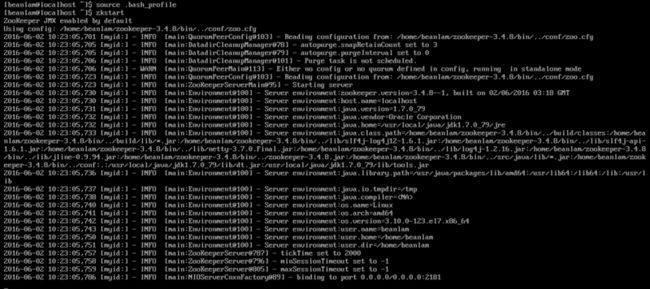
注意到这次启动和上一次动的输出不一样,明显输出的信息多了很多,原因是在启动zk的时候用的是zkServer.sh start-foreground。
这种启动方式让zk以前台进程的方式运行,这种运行方式也会占用屏幕。不过在调试的时候,我们还是挺需要这些输出信息的,有时候能帮我们做出一些基本的判断。
zkServer.sh这个脚本支持多种参数

可以看到Usage这一行,包括了所有支持的参数。
客户端连接
bin目录下包含有一个名为zkCli.sh的脚本,zookeeper也支持其它客户端。例如Java的有curator等。
但这个脚本作为我们尝试zookeeper的客户端,也是挺便利的。
再启动zk后,另开一个会话窗口,启动客户端去连接zk。

从输出的信息中可以看到客户端运行的环境,比如jdk的版本,classpath
这里值得注意的是最后有一个watcher相关的信息,每当客户端与zk服务器建立连接时,服务端都会发送一个状态为SyncConnected的watch event给客户端。客户端可以基于此,做出一些相应的动作。由于我们用的是这样的脚本形式的客户段,还没能对这个event进行处理。
zookeeper自带的客户端以及一些其他的Java客户端例如curator都能对这种事件进行处理。
ZNODE
zookeeper内部存储数据的数据结构是一棵树,类似于linux文件系统的组织方式。
最上层有一个根节点 /,根节点下有子节点,字节点下又能递归地拥有子节点。
没有任何子节点的节点称之为叶子节点。
在zookeeper的术语中,节点称之为znode。

zookeeper只是在内存中维护这样一份树状的数据结构,并没有直接提供分布式系统协调中的一些机制。
分布式锁、集群配置管理、以及master选举等,都需要应用在zookeeper这个基本的数据结构上去做实现。
例如,当多个客户端要竞争同一把锁的时候,每个客户端都尝试去创建某个znode。
zookeeper保证了一个znode只能由一个客户端创建,哪个客户端创建成功了,它便拥有了这个锁。
znode
存储数据类型
每个znode除了有代表自己的路径名外,还能存储一些数据,zookeeper只支持以字节数组的方式去存储数据。
如果我们要在znode里存储一个字符串,很简单,直接调字符串的getBytes方法就可以。
如果我们要在znode里存储一个Java对象呢,那么就得先把这个对象在本地序列化后再存储到zookeeper。
持久性和挥发性
zookeeper中,一个znode会有两种可能的mode:
- 持久性的(persistent)
- 挥发性的(ephemeral)
这个mode在创建znode的时候就确定下来,默认情况下,创建的znode是持久性的。
持久性和挥发性各有各的应用场景,持久性的znode会一直存在,因此持久性的znode适合用来存储一些全局性,共享性的数据。
比如说,配置信息,任务信息。
挥发性的znode在客户端的session结束后或者是zookeeper服务器停止运行的时候会被删除。
挥发性的znode适合用来存储与会话相关的数据,比如说一个客户端的状态,一个客户端持有的锁,与会话相关的数据,应随着会话的生死而生死。
一个比较经典的案例是,在分布式锁的场景下,如上文所提到的,各个想要获取这把锁的客户端都会去创建同一个znode。
哪个客户端创建成功,便获取到了这把锁。
在这里,这个znode必须是挥发性的,如果一个客户端获取锁以后,它自己宕机了,要是这个znode不是挥发性的,那么它将永远存在于zookeeper中。
这也意味着其它客户端永远也不可能获得这个锁。
值得注意的是,如果一个znode是挥发性的,目前zookeeper是不允许它有子znode的。

用-e选项指定创建一个挥发性的znode,然后在这个znode下创建子znode时,提示挥发性的节点不允许有子节点。
zookeeper未来可能会考虑支持创建子节点。
自增长的znode
当我们需要在一个znode下创建子节点,并希望这些子节点都拥有唯一的名字时,我们可以从两方面去做到:
- 客户端主动设置名字,名字的唯一性由客户端来保证,这也意味着客户端必须有生成全局唯一ID的能力或机制。
- 交给zookeeper去做,由zookeeper来生成唯一的ID
第二种情形很类似于数据库的auto_increment,当我们在数据库创建了一个表,并把某个字段,比如说ID字段,设置为自增长的。
那么每次我们往表中插入一条数据,不必为ID指定值,数据库自动会以自增长序列的方式作为ID的值。
zookeeper也有这个机制,比如我们创建了一个代表任务的节点/tasks,这个znode下会有task-1,task-2,......,task-n等,如下所示
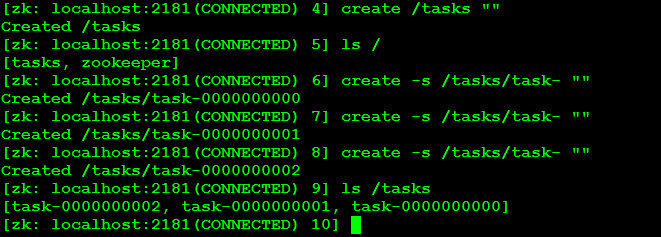
结合持久性、挥发性以及是否自增长,一个znode会有四种模式:持久的、挥发的、持久并自增长的、挥发并自增长的。
监听
zookeeper允许客户端对某个znode进行监听。
比如说这个znode的内容改变了;
或者这个znode原本不存在,但被创建了;
或者这个znode被删除了;
又或者是有人在这个znode下创建子节点了;
等等。
客户端只需要向zookeeper注册对某个znode的监听,之后zookeeper会将该znode上发生的变化告诉客户端。
值得注意的是这里,zookeeper通知客户端的时候,只会告诉客户端发生了什么事,但并不会把发生改变的数据推送给客户端。
客户端需要在接收到通知后,自己主动去查询zookeeper。
另外,客户端对某个节点的监听并不是永久有效的,监听只能用一次,如果下次还想再监听,客户端就必须不断地注册监听。
例如以下例子,启动一个客户端client1在/下创建了一个/test的节点

另外启动一个客户端client2,对/test的数据变化进行监听

然后用client1对/test存储的数据进行修改

可以发现client2收到了一些推送消息,类型是NodeDataChanged,意味着znode的数据被更改了

此时如果在client1上再次对/test的内容进行更改,client2是收不到通知的。
如前文所说,每一次监听只能用一次,如果client2想要继续收到通知,那么只能继续注册监听。
znode的版本
每个znode都有一个版本号,每次对znode的修改都会使版本号递增。
为znode进行set data或者delete操作时,可以指定版本号,只有指定的版本号是znode当前的版本号时,操作才能成功。
这个版本号的作用类似于我们常常见到的CAS(compare and swap)操作,目的是避免加锁。
适合用于多个客户端并发去修改同一个znode的情况。
集群实例数量的选择
应用程序通过zookeeper客户端连接zookeeper。客户端可以是zookeeper自身携带的客户端(zookeeper把client代码跟server放在一起,这点很多人有非议),也可以是一些其它的开源客户端例如apache curator和zkClient。

zookeeper可以有两种部署模式,一种是单机版,一种是集群版。
所谓单机版,亦即只有一个zookeeper实例。
集群版会有多个zookeeper实例,多个实例之间会有一个master,他们之间的状态信息也会进行复制。
集群的数目:奇数
从各种书或网上的资料上经常能看到一个建议:
zookeeper的集群里,实例的个数最好是奇数
对于客户端来说,它并不需要关心zookeeper集群中有多少个实例,实例之间是怎么协商的。
如果客户端新建了一个znode,并得到了集群的响应,那么客户端就可以认为集群已经替它保存好了这个znode。
而实际上,在zookeeper集群内部,它们并不会把znode的创建都通知到每个zookeeper实例后才返回响应消息给客户端。
可以看出来,在zookeeper集群中,有一件非常重要的事经常会发生,那就是如何让集群中的每个实例对某个公共状态的变化达成共识。
公共状态的变化包括什么呢?
- leader选举
- 来自客户端的各种updates
zookeeper采用的方式是,如果集群中有过半数的实例同意某个公共状态的变化,那么便认为集群最终会对这个公共状态达成一致意见。
为什么是过半数?
我们先看看如果不是“过半数”,会发生什么情况:
假设现在集群中有5个实例,当客户端新建一个znode “/test”后,只有2个实例同步了这个新建的znode,并通知客户端znode创建成功了。
在这2个实例通知其它3个实例之前,与其他3个实例发生了网络隔离(俗称“脑裂”,split-brain),变成了两个小集群了。
有2个实例拥有/test这个znode,而另外3个没有/test这个znode,并且在网络隔离还没恢复之前,这3个没有znode的实例永远不会得到关于/test这个znode被创建的通知。
当有一个客户端碰巧连接到的是那3个实例中的其中一个时,客户端永远也看不到/test这个znode。
这就出现了数据不一致的情况了。
如果是“过半数”,那情况就不一样了:
还是假设集群中有5个实例,这个时候,必须得有至少3个实例同步了/test这个znode后,客户端才会得到响应。
再次考虑网络隔离发生的场景,在这个3个实例还没通知到另外2个实例之前,又被隔离成两个小集群。
假设客户端连接到的是2个实例的那个集群,由于zookeeper认为要至少3个实例(过半数)存活才能提供服务,所以客户端获取不成功,数据是一致的。
只要是采取“过半数”的策略,无论网络怎么隔离,无论脑怎么裂,能够提供服务(意味着有过半数的实例)的那个小集群里,至少有一个实例是同步到最新的状态信息的。
包括zookeeper本身的leader选举,以及对znode的更新操作,都需要“过半数“这个作为基本方针。
为什么是奇数
偶数也可以有过半数,例如,4个实例的集群,3就是一个过半数。
但为什么还是奇数最好?
如果集群有5个实例,那么只能容忍2个实例的崩溃。
如果集群中有6个实例,同样也只能容忍2个实例的崩溃。
在相同的容忍度下,6个和5个有什么区别:
- 由于集群间需要互相通信,实例越多,网络开销越大
- 实例越多,5个实例的时候,发生3个实例崩溃的概率要小于6个实例的时候。
那我们为什么不比较6个和7个?
没有可比性,容忍度不同。
如果有3,5,7供选择,该怎么选?
集群中的实例数目越多,就越稳定。
但实例数目越多,网络开销以及实例之间协调的耗费也会比较大。
这只是一个权衡利弊取其轻的原则
伪集群安装
只有一台linux主机,但却想要搭建一套zookeeper集群的环境。
可以使用伪集群模式来搭建。
伪集群模式本质上就是在一个linux操作系统里面启动多个zookeeper实例。
这些不同的实例使用不同的端口,配置文件以及数据目录。
创建独立的目录
创建三个目录,隔离开3个zookeeper实例的数据文件,配置文件:
[beanlam@localhost ~]$ mkdir zk1
[beanlam@localhost ~]$ mkdir zk2
[beanlam@localhost ~]$ mkdir zk3
然后,再分别为每个目录创建一个数据目录,用来存放数据以及id文件
[beanlam@localhost ~]$ mkdir zk1/data
[beanlam@localhost ~]$ mkdir zk2/data
[beanlam@localhost ~]$ mkdir zk3/data
指定id
zookeeper启动的时候,会在它的数据目录下寻找id文件,以便知道它自己在集群中的编号。
[beanlam@localhost ~]$ echo 1 > zk1/data/myid
[beanlam@localhost ~]$ echo 2 > zk2/data/myid
[beanlam@localhost ~]$ echo 3 > zk3/data/myid
修改配置文件
这3个实例,每个实例都会使用不同的配置文件启动。
配置示例如下:
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/home/beanlam/zk1/data
# the port at which the clients will connect
clientPort=2181
server.1=127.0.0.1:2222:2223
server.2=127.0.0.1:3333:3334
server.3=127.0.0.1:4444:4445
这是第一个实例的配置,z1.cfg。把这份配置文件放置在zk1/目录下。
同理,第二个和第三个实例的配置分别为z2.cfg和z3.cfg。和第一个实例一样,放在相同的位置。
唯一不同的是,clientPort必须修改一下,z1.cfg为2181,z2.cfg和z3.cfg不能也是2181,必须彼此不同,比如2182或者2183。
配置文件最底下有一个server.n的配置项,这里配置了两个端口,却一种第一个用于集群间实例的通信,第二个用于leader选举。
至于2181,用于监听客户端的连接。
启动和连接
按照以下方式,依次启动3个实例:
[beanlam@localhost ~]$ cd zk1
[beanlam@localhost zk1]$ ~/zookeeper-3.4.8/bin/zkServer.sh start-foreground ./z1.cfg
启动第一个和第二个实例的时候会有报错信息,因为其它实例还没启动完全,连接无法建立的原因,可以直接忽略。
启动完3个实例后,会发现其中有一个是leader,另外两个是follower。可观察输出信息。
接下来启动一个客户端去进行连接:
[beanlam@localhost ~]$ ~/zookeeper-3.4.8/bin/zkCli.sh -server 127.0.0.1:2181,127.0.0.1:2182,127.0.0.1:2183
可以看到,客户端连接上了刚才启动的三个实例中的其中一个。
