在资料的收集过程中找到了两个比较好的算法演示动画网站Sorting Algorithms Animations (包含了排序算法的各种演示、对比,以及伪代码)和 Algorithm Visualizer (大量算法的js代码和算法过程动画)
排序算法
基本上每个学算法、数据结构的人,都会学一下各种排序算法吧,我也是刚刚上路,也走一下这个过程。
总体而言,目前自己完成了如下6种排序算法的js和java实现,选择排序和冒泡排序这两种太过基础的就在此略过了。后续再写到新的排序算法的时候再加上。
- 插入排序及其变种
- 快速排序
- 归并排序
- 堆排序
- 希尔排序
- 基数排序
下面来仔细讲一讲每一种排序算法。
插入排序
插入排序的思想其实很简单,如果玩过扑克牌的同学肯定可以秒懂,就是每摸一张新的牌就把他插入到正确的位置上去,那具体从算法角度描述就是假如当前已有i个数有序排列着,再加入第i+1个数时,把他插入到正确的位置上保持i+1项有序,如此不断加入数字。
代码实现上就很简单了:
function insertSort1(arr){
if(arr.length < 2){
return;
}
for(var i = 1;i < arr.length;i++){
//前i-1个数字是从小到大有序排列着的
var temp = arr[i];
for(var z = i-1;z >= 0;z--){
//我们在前i-1个数中只需要找到比arr[i]小的位置停下来,
//把数字插进去,把后面的数字往后挪就可以了
//使用数组的splice方法来插入和删除可能代码量更小,但这里主要是为了表达思想
if(arr[z] <= temp){
break;
}
//我这里的实现是从后往前找位置插入,还没到插入的地方的时候需要把元素都往后挪
arr[z+1] = arr[z];
}
//找到插入的地方了,把该插入的元素插入进去
arr[z+1] = temp;
}
}
变种① : 两路插入排序
在上面插入排序的过程中,因为我们是找到合适的位置把第i个元素插入前i+1个元素的序列当中去,所以存在把比第i个元素大的元素都向后挪的情况:

比如把最后的5插入进去的时候,需要把6到14都依次向后挪动,所以一种解决办法既是构造一个循环数组,然后向其中插入元素,可以做到挪动的元素数量减半。
举个栗子:
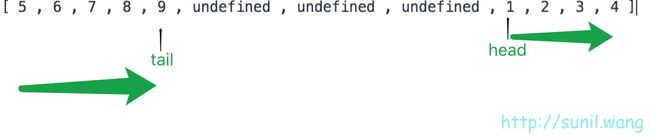
现在的循环数组是这样的,假如你要插入2.5,原先的方案你需要将3到9全部向后挪一个位置,然后将2.5插入进去,现在你只需要把1和2往前挪就好了。
代码实现:
function insertSort2(arr){
if(arr.length < 2){
return;
}
var head,tail = head = 0,tempArr = new Array(arr.length);
tempArr[0] = arr[0];
//构建一个新的数组,这个循环数组存放我们的排序结果,排序完成之后再把元素输出回去
for(var i =1;i= tempArr[0]){
//首先和tempArr[0]比较,如果较大,那么就在0到tail中找位置插进去
var j = 0;
while(j <= tail){
if(arr[i] > tempArr[j]){
j++
}else{
//找到应该插入的位置了
break;
}
}
tempArr.splice(j,0,arr[i])
tempArr.splice(++tail+1,1)
}else{
//如果比tempArr[0]小,那么就在head到arr.length - 1中找位置插进去
var j = arr.length - 1;
if(head === 0){
head = j;
tempArr[head] = arr[i];
}else{
while(j >= head){
if(arr[i] < tempArr[j]){
j--
}else{
break;
}
}
tempArr.splice(j+1,0,arr[i])
tempArr.splice(--head-1,1);
}
}
}
for(i = 0;i < arr.length;i++){
//把循环数组中的元素取出来放回原数组
arr[i] = tempArr[(i + head) % arr.length];
}
}
变种② : 静态链表插入
数组插入肯定是无法避免的需要挪动元素、腾出空间的,那用链表就不会出现这样的问题了,这里演示的是用静态链表来实现的(静态链表相当于是用一个数组来实现线性表的链式存储结构,不过数组的每个元素里不仅存了内容,还有一个next指针,指明链表的下一个元素在数组中的下标)。
算法实现:
function insertSort3(arr){
if(arr.length < 2){
return;
}
var staticLinkedList = arr.map(function(value){
//构造静态链表
//每一个元素是一个对象,value是原先数组的具体的内容,
//后面的代码里会向对象添加next属性,表示链表的后继节点是数组的哪个元素
return {value:value}
})
staticLinkedList.next = 0;
staticLinkedList[0].next = null;
for(var i = 1;i < arr.length;i++){
for(var pointer = staticLinkedList;(pointer.next != null) && (staticLinkedList[pointer.next].value < arr[i]);pointer = staticLinkedList[pointer.next]){
}
pointer.next === null ? (pointer.next = i,staticLinkedList[i].next = null):(staticLinkedList[i].next =pointer.next,pointer.next = i);
}
pointer = staticLinkedList.next;
i= 0;
while(pointer !== null){
arr[i] = staticLinkedList[pointer].value;
i++;
pointer = staticLinkedList[pointer].next;
}
}
快速排序
快速排序的基本思想是,通过一趟排序将待排元素分割成两部分,使得其中一部分元素均小于另外一部分元素,那接下来就可以继续递归的对这两部分进行排序,最终使得整个序列是有序的。
我们想想该怎么实现,先想个小计划:先挣他个一个亿,先选择一个数作为基准,然后遍历整个序列,把大于基准的数移到序列的尾部去,小于等于的就不动。这样一轮遍历下来,就可以实现序列分成一部分大一部分小了。
话是这样说,可是实现起来肯定不是这样啦,上面说的“移到尾部去”这个小操作就意味着很多的数据挪动,所以我们在具体实现时要修改一下,我们可以设定两个游标,一个叫做low指向数组的头部,一个叫做high指向数组的尾部,然后选择一个数作为基准,假如我们选第一个数为基准
- high往前遍历,遇到比基准大的就略过(因为我们本来就希望数组的尾部放的是比基准大的那部分),直到遇到一个比基准小的,把他跟基准交换一下
- low往后遍历,遇到比基准小的就略过(因为我们本来就希望数组的前部放的是比基准小的那部分),直到遇到一个比基准大的,把他跟基准交换一下
- 回到1 继续执行直到low和high相交,这个时候遍历完了,也就结束了一趟排序
上述过程中我们发现在和基准交换的过程中,我们经常要把基准交换,仔细分析一下其实可以在这一趟排序终止之后再把基准写进去。
算法实现:
function quickSort(arr,start,end){
if(arr.length<2){
return;
}
start = start || 0;
end = end || arr.length - 1;
var left = start;
var right = end;
var pivot = arr[left];
while(left < right){
while(arr[right] >= pivot && left < right){
right--;
}
//把pivot和那个小于pivot的元素交换一下
arr[left] = arr[right];
while(arr[left] <= pivot && left < right){
left++;
}
//把pivot和那个大于pivot的元素交换一下
arr[right] = arr[left];
}
//最后再把pivot写进去
arr[left] = pivot;
if(left - 1 > start){
quickSort(arr,start,left-1);
}
if(left +1 < end){
quickSort(arr,left+1,end);
}
}
有的算法是以中间的元素作为基准,其实没有什么区别,你只需要把每趟排序前先把中间的数和第一个数交换一下就完了
归并排序
归并排序是分治法的一个很好应用:归并排序的具体思想是把原来的序列分成两个子序列,分别使两个子序列有序之后再把两个子序列合并到一起。使子序列有序的过程又是一次排序的过程,那么就需要递归的把子序列排好序,再去合并。
不用再过多解释,上张图就明白了:

很明显,算法的具体过程就是在序列的元素个数大于2的时候把序列分成两个子序列,然后对子序列递归的继续执行拆分成两个子序列的过程,当序列的长度小于2时,就不需要再拆分了,直接对两个子序列合并成一个有序序列即可,这样逐次向上合并,最终完成排序过程。
算法实现:
function mergeSort(array,start,end){
if(array.length<2){
return;
}
start = start || 0;
end = end || array.length - 1;
//选择中间的位置作为分割点
var mid = Math.floor((start + end) / 2);
if(start < mid){
//对左边的序列递归执行排序过程
mergeSort(array,start,mid);
}
if(mid + 1< end){
//对右边的序列递归执行排序过程
mergeSort(array,mid+1,end);
}
//排好序了,接下来合并就好了
var i = start,j = mid + 1,z = 0;
var tempArr = [];
//设置两个指针,合并两个数组,谁小就把谁加入数组当中
while((i < mid + 1 ) && ( j < end + 1)){
if(array[i] > array[j]){
tempArr[z] = array[j];
j++;
z++;
}else{
tempArr[z] = array[i];
i++;
z++;
}
}
if(i < mid + 1){
while(i < mid + 1){
tempArr[z] = array[i];
i++;
z++;
}
}
if(j < end + 1){
while(j < end + 1){
tempArr[z] = array[j];
j++;
z++;
}
}
for(i = 0;i < end + 1 - start;i++){
array[i+start] = tempArr[i];
}
}
堆排序
堆排序是利用二叉堆来排序,堆分为大根堆和小根堆,是完全二叉树。
以大根堆为例,大根堆的要求是每个节点的值都不大于其父节点的值,即A[PARENT[i]] >= A[i]。对于每一个节点满足上述要求,所以这就使得这个二叉堆的根节点是这个堆里最大的一个数,所以我们只要把待排序的序列建成一个大/小根堆然后输出根节点,此时堆已经没有了根节点,需要调整堆节构使其继续成为二叉堆,就可以又把最大/小的节点调整到根节点上面去,接下来就可以不断重复上述过程直至把堆里的节点都输出出来这就完成了排序过程。
堆排序已经足够简单,直接上代码吧:
function heapSort(arr){
var temp;
if(arr.length <2){
return;
}
for(var i = Math.floor((arr.length - 2) / 2);i > -1;i--){
//从最后一个非叶子节点开始调整,使得以其为根节点的子树成为一个小根堆
//这样,当遍历到根节点时,这棵树也就被调整成为了小根堆
_heapAdjust(arr,i,arr.length-1)
}
for(var j = arr.length - 1;j > 0;j--){
//将最大的节点输出(把根节点和arr[j]节点交换)
temp = arr[j];
arr[j] = arr[0];
arr[0] = temp;
//对0~j-1节点构成的子树,进行调整,使其再次成为小根堆
_heapAdjust(arr,0,j-1);
}
}
//堆调整函数,在假设某一节点的左右子树均为小根堆的情况下,调整该节点为根节点的子树,使其成为小根堆
function _heapAdjust(arr, start, end){
var top = arr[start];
//将top调整到合适的位置
for(var i = start * 2 + 1; i < end + 1;i = start * 2 + 1){
if(i != end && arr[i] > arr[i+1]){
i++
}
if(top < arr[i]){
//如果此时满足两个子节点都小于top,那么也就调整好了
break;
}
//否则将那个较小的节点上移
arr[start] = arr[i];
//指针指到那个较小的节点上去,接下来不断的遍历子树,不断将较小的节点向上移动
start = i;
}
//此时,start就是top节点该存放的位置
arr[start] = top;
}
希尔排序
希尔排序的实质就是分组插入排序,该方法又称缩小增量排序,因DL.Shell于1959年提出而得名。
该方法的基本思想是:先将整个待排元素序列分割成若干个子序列(由相隔某个“增量”的元素组成的)分别进行直接插入排序,然后依次缩减增量再进行排序,待整个序列中的元素基本有序(增量足够小)时,再对全体元素进行一次直接插入排序。
依然是上一个图,就可以讲得很明白了:


对于希尔排序的增量应该怎么选取,其实是有大学问的,一般可以预先设置好增量序列,也可以动态设置增量,增量的设置会影响到算法的效率。对于预先设置好的增量序列,素数的增量会起到较好的效果。动态的设置增量则要保证增量序列的计算过程不会太复杂,不至于在增量上浪费大量计算性能。
下面给出一种动态增量的希尔排序实现:
function shellSort(arr){
if(arr.length < 2){
return;
}
var growth = 1;
while(growth < arr.length / 3){
//先计算出growth可取的最大值,
//在后面的代码中,growth不断减小,从而实现希尔排序的缩小增量排序
growth = growth * 3 + 1;
}
while(growth > 0){
_sortWithGrowth(arr,growth)
growth = (growth - 1)/3;
}
}
function _sortWithGrowth(arr,growth){
for(var i = 0;i < growth;i++){
for(var j = i + growth;j < arr.length; j += growth){
var temp = arr[j];
var z = j - growth;
while(z >= i){
if(arr[z] <= temp){
break;
}
arr[z+growth] = arr[z];
z -= growth;
}
arr[z + growth] = temp;
}
}
}
基数排序
基数排序与本系列前面讲解的5种排序方法都不同,它不需要比较关键字的大小。
它是根据关键字中各位的值,通过对排序的N个元素进行若干趟“分配”与“收集”来实现排序的。
基数排序又叫"桶子法"(bucket sort),我们可以把“分配”的过程看成是扔到桶里的过程,比如有一个序列,我们先对这个序列中的每一个数按照其个位“分配”到0-9这10个不同的桶里去,然后又依次从0号桶开始,把他们依次“收集”起来继续排成一个序列,这个时候这个序列已经是按照个位的大小排好了顺序,接下来再按照十位,把他们依次的放入到0-9号桶里去,然后再继续上述收集过程,这个时候序列已经先按十位、再按个位排好了顺序,接下来重复上述过程,就可以把序列从小到大的排好顺序了。
代码实现:
function radixSort(arr){
if(arr.length < 2){
return;
}
var radix = 1;
//找出最大值
var maxValue = Math.max.apply(null,arr);
var loopTimes = 0;
//看看最大值是基数的几次方就知道要循环几次了
while(maxValue){
loopTimes++;
maxValue = Math.floor(maxValue / 10);
}
for(var i = 0;i < loopTimes; i++){
//这个数组的元素就是\"桶\",而每个桶又是一个数组
var arrayOfArr = [];
for(var j = 0;j回过头看看
写了6个排序算法,写各种排序的这个过程给我一种很模糊、粗浅的感觉,就是在排序的过程中将元素移动得更远似乎就越省时省力、排序越快。
这样一种粗浅的直观感受在知乎上找到了这样的佐证:
可以用逆序数来理解,假设我们要从小到大排序,一个数组中取两个元素如果前面比后面大,则为一个逆序,容易看出排序的本质就是消除逆序数,可以证明对于随机数组,逆序数是O(N2)的,而如果采用“交换相邻元素”的办法来消除逆序,每次正好只消除一个,因此必须执行O(N2)的交换次数,这就是为啥冒泡、插入等算法只能到平方级别的原因,反过来,基于交换元素的排序要想突破这个下界,必须执行一些比较,交换相隔比较远的元素,使得一次交换能消除一个以上的逆序,希尔、快排、堆排等等算法都是交换比较远的元素,只不过规则各不同罢了。链接在此