
硬件推荐
Ceph 为普通硬件设计,这可使构建、维护 PB 级数据集群的费用相对低廉。规划集群硬件时,需要均衡几方面的因素,包括区域失效和潜在的性能问题。硬件规划要包含把使用 Ceph 集群的 Ceph 守护进程和其他进程恰当分布。通常,我们推荐在一台机器上只运行一种类型的守护进程。大部分专家推荐把使用数据集群的进程(如 OpenStack 、 CloudStack 等)安装在别的机器上。但是现在这个超融合架构泛滥的时代,部署在一起的大厂商也是有很多的,比如最早在公有云中使用ceph当做存储的有云。
CPU

Ceph 元数据服务器对 CPU 敏感,它会动态地重分布它们的负载,所以你的元数据服务器应该有足够的处理能力(我们生产使用的是2C双12核心CPU)。 Ceph 的 OSD 运行着 RADOS 服务、用 CRUSH计算数据存放位置、复制数据、维护它自己的集群运行图副本,因此 OSD 需要一定的处理能力(如双核 CPU )。监视器只简单地维护着集群运行图的副本,因此对 CPU 不敏感;但必须考虑机器以后是否还会运行 Ceph 监视器以外的 CPU 密集型任务。例如,如果服务器以后要运行用于计算的虚拟机(如 OpenStack Nova ),你就要确保给 Ceph 进程保留了足够的处理能力,所以我推荐在其他机器上运行 CPU 密集型任务。
内存

元数据服务器和监视器必须可以尽快地提供它们的数据,所以他们应该有足够的内存,至少每进程 1GB 。 OSD 的日常运行不需要那么多内存(如每进程 500MB )差不多了;然而在恢复期间它们占用内存比较大(如每进程每 TB 数据需要约 1GB 内存)。通常内存越多越好。(我的生产环境是超融合架构512G内存)
数据存储
要谨慎地规划数据存储配置,因为其间涉及明显的成本和性能折衷。来自操作系统的并行操作和到单个硬盘的多个守护进程并发读、写请求操作会极大地降低性能。文件系统局限性也要考虑: btrfs 尚未稳定到可以用于生产环境的程度,但它可以同时记日志并写入数据,而 xfs 和 ext4 却不能。
Important:因为 Ceph 发送 ACK 前必须把所有数据写入日志(至少对 xfs 和 ext4 来说是),因此均衡日志和 OSD 性能相当重要。
硬盘驱动器

OSD 应该有足够的空间用于存储对象数据。考虑到大硬盘的每 GB 成本,我们建议用容量大于 1TB 的硬盘。建议用 GB 数除以硬盘价格来计算每 GB 成本,因为较大的硬盘通常会对每 GB 成本有较大影响,例如,单价为 $75 的 1TB 硬盘其每 GB 价格为 $0.07 ( $75/1024=0.0732 ),又如单价为 $150 的 3TB 硬盘其每 GB 价格为 $0.05 ( $150/3072=0.0488 ),这样使用 1TB 硬盘会增加 40% 的每 GB 价格,它将表现为较低的经济性。另外,单个驱动器容量越大,其对应的 OSD 所需内存就越大,特别是在重均衡、回填、恢复期间。根据经验, 1TB 的存储空间大约需要 1GB 内存。
(我现在生产环境使用的是1.2T高速盘,也就解释了为何要组成大的内存。)
不顾分区而在单个硬盘上运行多个OSD,这样强烈不推荐!
不顾分区而在运行了OSD的硬盘上同时运行监视器或元数据服务器也强烈不推荐!
存储驱动器受限于寻道时间、访问时间、读写时间、还有总吞吐量,这些物理局限性影响着整体系统性能,尤其在系统恢复期间。因此我们推荐独立的驱动器用于安装操作系统和软件,另外每个 OSD 守护进程占用一个驱动器。大多数 “slow OSD”问题的起因都是在相同的硬盘上运行了操作系统、多个 OSD 、和/或多个日志文件。鉴于解决性能问题的成本差不多会超过另外增加磁盘驱动器,你应该在设计时就避免增加 OSD 存储驱动器的负担来提升性能。
Ceph 允许你在每块硬盘驱动器上运行多个 OSD ,但这会导致资源竞争并降低总体吞吐量; Ceph 也允许把日志和对象数据存储在相同驱动器上,但这会增加记录写日志并回应客户端的延时,因为 Ceph 必须先写入日志才会回应确认了写动作。 btrfs 文件系统能同时写入日志数据和对象数据, xfs 和 ext4 却不能。
Ceph 最佳实践指示,你应该分别在单独的硬盘运行操作系统、 OSD 数据和 OSD 日志。
固态硬盘

一种提升性能的方法是使用固态硬盘( SSD )来降低随机访问时间和读延时,同时增加吞吐量。 SSD 和硬盘相比每 GB 成本通常要高 10 倍以上,但访问时间至少比硬盘快 100 倍。
SSD 没有可移动机械部件,所以不存在和硬盘一样的局限性。但 SSD 也有局限性,评估SSD 时,顺序读写性能很重要,在为多个 OSD 存储日志时,有着 400MB/s 顺序读写吞吐量的 SSD 其性能远高于 120MB/s 的。
Important
我们建议发掘 SSD 的用法来提升性能。然而在大量投入 SSD 前,强烈建议核实 SSD 的性能指标,并在测试环境下衡量性能。
正因为 SSD 没有移动机械部件,所以它很适合 Ceph 里不需要太多存储空间的地方。相对廉价的 SSD 很诱人,慎用!可接受的 IOPS 指标对选择用于 Ceph 的 SSD 还不够,用于日志和 SSD 时还有几个重要考量:
- 写密集语义: 记日志涉及写密集语义,所以你要确保选用的 SSD 写入性能和硬盘相当或好于硬盘。廉价 SSD 可能在加速访问的同时引入写延时,有时候高性能硬盘的写入速度可以和便宜 SSD 相媲美。
- 顺序写入: 在一个 SSD 上为多个 OSD 存储多个日志时也必须考虑 SSD 的顺序写入极限,因为它们要同时处理多个 OSD 日志的写入请求。
- 分区对齐: 采用了 SSD 的一个常见问题是人们喜欢分区,却常常忽略了分区对齐,这会导致 SSD 的数据传输速率慢很多,所以请确保分区对齐了。
SSD 用于对象存储太昂贵了,但是把 OSD 的日志存到 SSD 、把对象数据存储到独立的硬盘可以明显提升性能。osd journal选项的默认值是 /var/lib/ceph/osd/$cluster-$id/journal,你可以把它挂载到一个 SSD 或 SSD 分区,这样它就不再是和对象数据一样存储在同一个硬盘上的文件了。提升 CephFS 文件系统性能的一种方法是从 CephFS 文件内容里分离出元数据。 Ceph 提供了默认的 metadata。存储池来存储 CephFS 元数据,所以你不需要给 CephFS 元数据创建存储池,但是可以给它创建一个仅指向某主机 SSD 的 CRUSH 运行图。详情见给存储池指定 OSD 。
控制器
硬盘控制器对写吞吐量也有显著影响,要谨慎地选择,以免产生性能瓶颈。
Ceph blog通常是优秀的Ceph性能问题来源,见 Ceph Write Throughput 1 和 Ceph Write Throughput 2 。
其他注意事项
你可以在同一主机上运行多个 OSD ,但要确保 OSD 硬盘总吞吐量不超过为客户端提供读写服务所需的网络带宽;还要考虑集群在每台主机上所存储的数据占总体的百分比,如果一台主机所占百分比太大而它挂了,就可能导致诸如超过 full ratio的问题,此问题会使 Ceph 中止运作以防数据丢失。如果每台主机运行多个 OSD ,也得保证内核是最新的。参阅操作系统推荐里关于 glibc和 syncfs(2) 的部分,确保硬件性能可达期望值。
OSD 数量较多(如 20 个以上)的主机会派生出大量线程,尤其是在恢复和重均衡期间。很多 Linux 内核默认的最大线程数较小(如 32k 个),如果您遇到了这类问题,可以把kernel.pid_max
值调高些。理论最大值是 4194303 。
例如把下列这行加入 /etc/sysctl.conf文件:
kernel.pid_max = 4194303
网络

建议每台机器最少两个千兆网卡,现在大多数机械硬盘都能达到大概 100MB/s 的吞吐量,网卡应该能处理所有 OSD 硬盘总吞吐量,所以推荐最少两个千兆网卡,分别用于公网(前端)和集群网络(后端)。集群网络(最好别连接到国际互联网)用于处理由数据复制产生的额外负载,而且可防止拒绝服务攻击,拒绝服务攻击会干扰数据归置组,使之在 OSD 数据复制时不能回到active + clean状态。请考虑部署万兆网卡。通过 1Gbps 网络复制 1TB 数据耗时 3 小时,而 3TB (典型配置)需要 9 小时,相比之下,如果使用 10Gbps 复制时间可分别缩减到 20 分钟和 1 小时。在一个 PB 级集群中, OSD 磁盘失败是常态,而非异常;在性价比合理的的前提下,系统管理员想让 PG 尽快从 degraded(降级)状态恢复到 active + clean状态。另外,一些部署工具(如 Dell 的 Crowbar )部署了 5 个不同的网络,但使用了 VLAN 以提高网络和硬件可管理性。 VLAN 使用 802.1q 协议,还需要采用支持 VLAN 功能的网卡和交换机,增加的硬件成本可用节省的运营(网络安装、维护)成本抵消。使用 VLAN 来处理集群和计算栈(如 OpenStack 、 CloudStack 等等)之间的 VM 流量时,采用 10G 网卡仍然值得。每个网络的机架路由器到核心路由器应该有更大的带宽,如 40Gbps 到 100Gbps 。
服务器应配置底板管理控制器( Baseboard Management Controller, BMC ),管理和部署工具也应该大规模使用 BMC ,所以请考虑带外网络管理的成本/效益平衡,此程序管理着 SSH 访问、 VM 映像上传、操作系统安装、端口管理、等等,会徒增网络负载。运营 3 个网络有点过分,但是每条流量路径都指示了部署一个大型数据集群前要仔细考虑的潜能力、吞吐量、性能瓶颈。
故障域
故障域指任何导致不能访问一个或多个 OSD 的故障,可以是主机上停止的进程、硬盘故障、操作系统崩溃、有问题的网卡、损坏的电源、断网、断电等等。规划硬件需求时,要在多个需求间寻求平衡点,像付出很多努力减少故障域带来的成本削减、隔离每个潜在故障域增加的成本。
最低硬件推荐
Ceph 可以运行在廉价的普通硬件上,小型生产集群和开发集群可以在一般的硬件上。
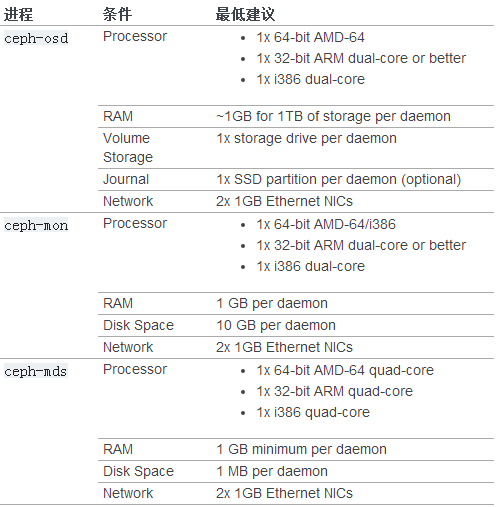
如果在只有一块硬盘的机器上运行 OSD ,要把数据和操作系统分别放到不同分区;一般来说,我们推荐操作系统和数据分别使用不同的硬盘。
生产集群实例
PB 级生产集群也可以使用普通硬件,但应该配备更多内存、 CPU 和数据存储空间来解决流量压力。
我们生产环境硬件配置
CPU:2*12C
内存:512G
硬盘:20*1.2T
网卡:2*10Gb
END.
OK今天就为大家介绍这么多了。
我是EC君,如果你喜欢我的文章,请帮忙点个关注!点个喜欢吧!
也可以点击作者信息,扫描微信二维码关注我的个人微信公众号。
你的鼓励将是我们共同进步的源泉。