前言
在上篇文章中,我们提到了java.util.stream包,今天我们就来详细的研究一下这个包。
整体框架
分析stream包,我们先从整体架构入手,然后再深入到细节。我们先来看看API文档:

从上图中可以看见stream包中的接口比较多,类和枚举比较少。我们先来看接口:
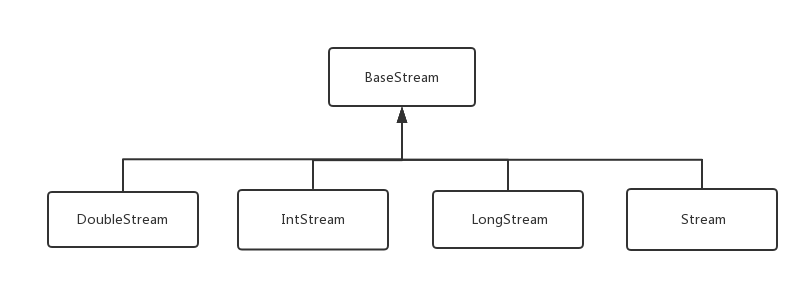
DoubleStream,IntStream,LongStream,Stream都继承于BaseStream接口。并且它们都有各自的Builder接口:DoubleStream.Builder,IntStream.Builder,LongStream.Builder,Stream.Builder。剩下就只有Collector接口,Collectors,StreamSupport类,Collector,Characteristics枚举。
Stream接口
Stream接口是一个泛型接口,而DoubleStream,IntStream,LongStream只不过是对double,int,long的包装而已,所以我们弄懂Stream,其他的接口也都大同小异。
1.forEach
void forEach(Consumer action)
forEach接收一个Consumer接口,该接口我们之前讲Function包时已经提过了。它只接收不参数,没有返回值。然后在 Stream 的每一个元素上执行该表达式。
范例:
Stream stream = Stream.of("I", "love", "you");
stream.forEach(System.out::println);
System.out.println方法我们都很熟悉了,它接收一个参数,并且在控制台打印出来。这正好符合Consumer接口,所以这里输出的结果是 :
I
love
you
2.peek
Stream peek(Consumer action)
peek方法也是接收一个Consumer功能型接口,它与forEach的区别就是它会返回Stream接口,也就是说forEach是一个Terminal操作,而peek是一个Intermediate操作,forEach完了以后Stream就消费完了,不能继续再使用,而peek还可以继续使用。
范例:
Stream stream = Stream.of("I", "love", "you");
stream.peek(System.out::println).forEach(System.out::println);
代码很简单,但是大家可以先思考一下,输出的结果是什么?
输出结果:
I
I
love
love
you
you
怎么样?跟你想的是一样的吗?有人可能会问,为什么输出结果不是以下这种呢?
I
love
you
I
love
you
明明peek方法在前面。这是因为我们前面提到过的懒加载,peek是一个Intermediate操作,它并不会马上执行,当forEach的时候才会把peek和forEach一起执行,来提高效率,所以等于是每个stream元素执行两次打印操作,再执行下一个元素。
3.filter
Stream filter(Predicate predicate)
filter方法接收一个断言型的接口,断言型接口接收一个参数,返回一个Boolean类型。filter方法根据某个条件对stream元素进行过滤,通过过滤的元素将生成一个新的stream。
范例:
Stream stream = Stream.of(1, 2, 3,4,5,6);
stream.filter((n)->n>2).forEach(System.out::println);
以上代码通过filter方法把大于2的元素过滤出来,然后输出。
4.map
Stream map(Function mapper)
map方法接收一个功能型接口,功能型接口接收一个参数,返回一个值。map方法的用途是将旧数据转换后变为新数据,是一种1:1的映射,每个输入元素按照规则转换成另一个元素。该方法是Intermediate操作。
Stream stream = Stream.of("a","b","c","d");
stream.map(String::toUpperCase).forEach(System.out::println);
以上代码通过map方法,把a,b,c,d全部转变成大写,然后输出。
5.flatMap
Stream flatMap(Function> mapper)
flatMap从结构上来看跟map差不多,主要是可以用来将stream层级扁平化。
Stream> inputStream = Stream.of(
Arrays.asList(1),
Arrays.asList(2, 3),
Arrays.asList(4, 5, 6)
);
inputStream.flatMap((n)->n.stream()).forEach(System.out::println);
我们可以看见,inputStream由3个list组成,在经过flatMap以后,list就没有了,以前list中的元素全部放在了一起。相关的方法还有:flatMapToInt,flatMapToLong,flatMapToDouble,只不过他们返回的分别是IntStream,LongStrea和DoubleStream。
6.findFirst:返回stream的第一个元素的Optional或为空。这是一个Terminal操作,也是一个短路操作。
7.count:返回此流元素的数量。
8.sorted:将此流中的元素根据自然顺序排序,sorted方法还有一个重载方法,可以传入一个Comparator,这样就可以根据Comparator来排序。
9.min/max:Stream接口中的这两个方法接收一个Comparator参数,通过Comparator返回此流最小或者最大的元素。IntStream,DoubleStream.LongStream则不需要传入Comparator。
10.limit:该方法接收一个long型参数,表示一共返回几个元素。
11.skip:接收一个long类型的参数,表示跳过几个元素。
12.distinct:消除重复元素后返回一个新Stream。
13.allMatch:Stream中的所有元素满足传入的断言型接口,就返回true。
14.anyMatch:Stream中的只要有一个元素满足传入的断言型接口,就返回true。
15.noneMatch:Stream中没有元素满足传入的断言型接口,就返回true。
16.generate:接收一个Supplier接口,返回一个Stream,通过实现supplier接口,可以自己来控制流的生成。
17.iterate:
static Stream iterate(T seed, UnaryOperator f)
iterate接收两个参数,第一个是泛型,seed可以理解为种子值或者起始值。UnaryOperator是一个接口:
@FunctionalInterface
public interface UnaryOperator extends Function
该接口继承了Function接口,那么也必须实现Function接口中的apply方法。除此之外该接口还有一个静态方法---identity,该方法始终返回其输入参数。
iterate方法的作用是将种子值成为stream的第一个元素,f(seed)为第二个元素,f(f(seed))为第三个元素,说递归你应该比较容易明白。
范例:
Stream.iterate(3, n->n+3).limit(10).forEach(System.out::println);
输出:
3
6
9
12
15
以上范例中,3即为种子值,然后f(3)等于6,f(f(3))得9。需要注意的是,iterate方法和generate方法返回的都是无限stream,需要用limite来限制stream的长度。
18.reduce:
reduce提供了三种重载方法。
1. Optional reduce(BinaryOperator accumulator)
2. T reduce(T identity, BinaryOperator accumulator)
3. U reduce(U identity, BiFunction accumulator, BinaryOperator combiner)
第一个方法返回一个Optional对象,接收一个BinaryOperator。我们先来看BinaryOperator是什么?
@FunctionalInterface
public interface BinaryOperator extends BiFunction
可以看到BinaryOperator是一个函数型接口,继承了BiFunction,并且传入参数和返回值都是相同类型。我们接着看BiFunction的定义:
@FunctionalInterface
public interface BiFunction{
R apply(T t, U u);
}
BiFunction接口中有一个apply方法,有两个参数,一个返回值。到这里我们大概知道reduce方法传入的参数大概怎么用了,在来看返回值Optional的定义:
public final class Optional extends Object
Optional是一个普通的对象,里面的方法大家可以自己去看API,这里就不详细说了。到这里你可能会说,写了这么多,你也没说reduce到底有什么作用啊?我们通过名字去猜测一下,reduce有减少,归纳之意。那我们是否可以理解为,把Stream提供的多个元素归纳成一个对象?
范例:
Integer sum=Stream.of(1,2,3,4).reduce(Integer::sum).get();
System.out.println(sum);
输出:
10
我们通过reduce方法,把1-4累加起来得到结果10.你肯定会问为什么传的参数是Integer::sum?我们在以前的文章里面提到了方法引用::,在这里就是引用了Integer类的sum方法:
static int sum(int a, int b)
这个方法是不是就跟BiFunction中定义的apply一样呢?接收两个参数和一个返回值。
我们接着看reduce的第二个重载方法,在这个重载方法中多了一个参数T,这就是起始值,然后返回值由Optional变成了T。
范例:
Integer sum=Stream.of(1,2,3,4).reduce(1,Integer::sum);
System.out.println(sum);
输出:
11
在此范例中,我们添加了起始值1,使得最后输出结果多加了1。如果你觉得还不明白,那么再来看一个例子。
范例:
String sum=Stream.of("a","b","c","d").reduce("1",String::concat);
System.out.println(sum);
输出:
1abcd
这会应该明白了。
关于reduce的第三个重载方法,主要是用于parallelStream的,reduce操作是并发进行的,为了避免竞争,每个reduce线程都会有独立的result,combiner参数的作用就是在于合并每个线程的result得到最终的结果。由于第三个方法不是特别常用,我就只说一下方法不给出范例了。
U reduce(U identity, BiFunction accumulator, BinaryOperator combiner)
这个方法起初一看,头都大了,这都是什么鬼?又是U,又是T,又是BiFunction,又是BinaryOperator。BinaryOperator不是继承与BiFunction的么?为什么不两个都使用BiFunction呢?
那我们就来解析一下这个方法,首先该方法的返回值是由第一个参数决定的。也就是说第一个参数是什么类型,该方法就返回什么类型。这点明确了很重要。
我们接着看第二个参数-BiFunction,为了理解深刻,我们再次拿出该接口的定义:
@FunctionalInterface
public interface BiFunction{
R apply(T t, U u);
}
该接口接收两个参数,这两个参数的类型可以不一致。并且返回一个值,值的类型也可以不一致。
接着我们看reduce方法里面定义的
BiFunction accumulator
我们来对应一下,该接口接收两个参数,其中第一个为U,第二个为T的子类,返回类型为U。这下就明白多了,也就是说接收两个不同类型的参数,但是返回值类型跟第一个参数一致,而第一个参数的类型也就是reduce方法的第一个参数类型U。
在看reduce第三个参数-BinaryOperator
@FunctionalInterface
public interface BinaryOperator extends BiFunction
该接口继承了BiFunction,但是最重要的是,继承的BiFunction的两个接收参数和返回值都是同一个类型T。所以简单来说BinaryOperator接收两个参数,返回一个值都是同一类型。
到这里我们应该明白了为什么reduce第二个参数是BiFunction,第三个参数是BinaryOperator了吧?
因为第二个参数的作用是accumulator,所以接收的两个参数类型可以不一样。而前面说了在parallelStream的情况下,combiner的作用是合并每个线程的结果,而每个线程返回的结果都应该是同一个类型,所以在这里用BinaryOperator而不是BiFunction。
不得不说这种设计真的是太精妙了。
19.collect:
collect方法跟reduce方法功能很类似,都是聚合方法。不同的是,reduce方法在操作每一个元素时总创建一个新值,而collect方法只是修改现存的值,而不是创建一个新值。
方法定义:
1. R collect(Collector collector)
2. R collect(Supplier supplier, BiConsumer accumulator, BiConsumer combiner)
这两个方法都是泛型方法,我们先看第一个。第一个方法接收一个Collector接口作为参数。如果我们要自己实现它会很麻烦,好在java.util.stream包中给我们提供了一个叫Collectors的类。这个方法我就不在这里介绍了,大家可以自己去看API,通过Collectors这个类我们可以很容易得到一个Collector对象,这个类中提供了很多统计的操作和创建集合的操作。
范例:
Stream stream = Stream.of("a", "b", "c", "d");
List list =stream.collect(Collectors.toList());
for (String string : list) {
System.out.println(string);
}
输出:
a
b
c
d
在这里我们将一个stream流转换为了一个List对象。
collect方法的第二种形式跟我们前面说的reduce的很像。接收3个参数,第一个参数是Supplier接口,这个接口我们以前说过。
@FunctionalInterface
public interface Supplier {
/**
* Gets a result.
*
* @return a result
*/
T get();
}
BiConsumer接口跟Consumer接口类似,不同的是Consumer接口只接收一个参数而BiConsumer接口接收两个参数。collect的第二个参数和第三个参数都是BiConsumer接口,但是参数类型却不一样。BiConsumer
范例:
System.out.println(Arrays.asList("1","2","3","4").parallelStream().collect(
StringBuilder::new,
new BiConsumer(){
@Override
public void accept(StringBuilder t, String u) {
System.out.println("accumulator operate current thread:"+Thread.currentThread().getId()+" t:"+t+" u:"+u);
t.append(u);
System.out.println("accumulator operate current thread:"+Thread.currentThread().getId()+" result t:"+t+" u:"+u);
}
}
, new BiConsumer(){
@Override
public void accept(StringBuilder t, StringBuilder u) {
System.out.println("combiner operate current thread:"+Thread.currentThread().getId()+" t:"+t+" u:"+u);
t.append(u);
System.out.println("combiner operate current thread:"+Thread.currentThread().getId()+" result t:"+t+" u:"+u);
}
}));
输出:
accumulator operate current thread:1 t: u:3
accumulator operate current thread:11 t: u:4
accumulator operate current thread:10 t: u:2
accumulator operate current thread:12 t: u:1
accumulator operate current thread:12 result t:1 u:1
accumulator operate current thread:10 result t:2 u:2
accumulator operate current thread:11 result t:4 u:4
accumulator operate current thread:1 result t:3 u:3
combiner operate current thread:1 t:3 u:4
combiner operate current thread:10 t:1 u:2
combiner operate current thread:1 result t:34 u:4
combiner operate current thread:10 result t:12 u:2
combiner operate current thread:10 t:12 u:34
combiner operate current thread:10 result t:1234 u:34
1234
为了方便大家理解,我并没有使用lambda表达式。我们首先创建了一个并行的stream,每个stream元素的类型为String,接着我们调用了collect方法,collect方法第一个参数是创建一个StringBuilder对象,在第二个参数中,我们打印了当前的线程id,和t,u的值方便调试。执行的操作也只是把String加入到StringBuilder中,第三个参数则把两个StringBuilder合并。从输出结果中我们可以看见,在执行accumulator操作的时候t的值是空的,并且是4个线程同时进行了accumulator操作,每个线程都把String加入到了StringBuilder中,而在执行combiner操作的时候,就由4个线程变成了2个,然后进行合并操作。最终结果为1234。由于是多线程的,所以每次输出的顺序是不一样的。以上输出只能作为参考。
到目前为止,Stream接口中的大部分方法我们都讲过了。至于那些IntStream,LongStream都大同小异,大家可以自己去看看,我就不做详细介绍了。
如果你觉得本篇文章帮助到了你,希望大爷能够给瓶买水钱。
本文为原创文章,转载请注明出处!