工作中遇到很多同事问到用户故事的相关概念,而且基本是每新来一个同事就要解释一遍,这里做个总结,希望以后不要再做这个重复性的工作了。
1. INVEST
INVEST是用户故事的书写标准,具体每个字母的含义如下:
1.1. Independent(独立的)
一个用户故事对于另一个用户故事应该是尽可能独立的。为什么呢?因为传统的需求描述方式(功能模块、用例等等)由于个体较大,彼此之间依赖较多,导致输入到开发阶段时开发工程师不太容易计划他们的工作,从而导致的开发延期的现象就变成大家习以为常了。而独立性较好的故事能够独立交付,从这一点,用户故事就充分的考虑到了需求与开发的敏捷化连接问题。
那要如何才能做到用户故事之间的独立性呢?通常,可以通过组合用户故事或者分割用户故事来减少依赖性。
1.2. Negotiable(可协商的)
大家对所有之前达成的一致在新的变化发生情况下,协商后达成新的一致,从而推动系统的研发进展。
上面是比较书面的解释,我的理解是这样的:
用户故事可协商的地方,在于验收标准(AC),同样一个手机号+验证码的注册功能,我们既可以写成如下的验收标准(以下只是举例,真实的验收标准建议参照Given-When-Then的格式编写):
手机号是11位数字
手机号只能是13、15、17、18开头
验证码一分钟只能发送一条
发送验证码之前需要做个图片验证
验证码的有效期是5分钟
验证码4位数字
密码6-12位
密码只能是字母、数字、下划线的2种或3种的组合
……
如果按照这个验收标准来做,一个注册功能可能就要开发一周左右,但是早期我们为了快速进行后续的开发,可以暂时降低我们验收标准:
手机号是11位数字
验证码一分钟只能发送一条
验证码4位数字
密码6-12位
这样就能迅速完成注册的功能,继续后续的开发了。
这就是我理解的用户故事的“可协商的”概念。
协商去掉的这些验收标准,不是说以后都不做了,而是暂时为了完成整个MVP,就先牺牲掉了,这些细节还可以在后续的迭代里再加上。
1.3. Valuable(有价值的)
每个故事必须对客户具有价值(无论是用户还是购买方)。一个让用户故事有价值的好方法是让客户来写下它们。
书写用户故事的三段论:
作为(XX角色),我想(XX功能),从而(实现XX价值)
最后一句话,就是在强调价值的重要性。
1.4. Estimable(可估计的)
开发者需要去估计一个用户故事以便对故事进行规划。但是让开发者难以估计故事的问题来自:对于领域知识的缺乏(这种情况下需要更多的沟通),或者故事太大了(这时需要把故事切分成小些的)。
1.5. Small(短小的)
一个好的故事应该在工作量上短小,描述具有代表性,而且不超过3人天(或者3故事点)的工作量。超过这个范围的用户故事,将会在划分范围和估计时出现很多错误。
1.6. Testable(可测试的)
一个用户故事是可测试的并用来确认完成,记住,我们不开发不能测试的故事。如果你不能测试那么你永远不知道你什么时候是完成了。
小结
一个编写良好的用户故事是敏捷开发的基础。它们应该相互独立,详情应该便于开发者和用户进行沟通,应该对用户有价值,应该对于开发者来说尽可能的清晰以便进行估计,应该短小,通过预定义测试用例的使用确保它是可以测试的。
2. 3C
3C是收集用户故事的有效手段,具体每个C的含义如下:
2.1. Card(卡片)
用卡片(Card)来简要描述故事。
2.2. Conversation(会话)
与Product Owner(或客户)交谈(Conversation)来明确细节。
2.3. Confirmation(确认)
验收评审,确认(Confirmation)被正确完成。
3. DEEP
DEEP原则是用来梳理Product Backlog的,改概念最早在Mike Cohn的《Succeeding with Agile》一书中提到。
3.1. Detailed Appropriately(详略得当)
接下来的1~2个Sprint中要完成的用户故事,需要足够的详细。而不着急开发的,则不必太详细。
3.2. Estimated(做过估算的)
Product Backlog中的需求都要是经过估算的,只不过靠后(优先级低)的PBI没有充分理解(也不必),因此其估算也不如靠前(优先级高)的PBI估算精确。
3.3. Emergent(涌现的)
Product Backlog不是静止的。随着了解的深入,Product Backlog中的用户故事会增加、减少、删除、拆分或重新排优先级。
3.4. Prioritized(排列优先级的)
Product Backlog应该根据由上至下按照条目的价值从高到低排序。团队应根据优先级进行开发,从而使正在开发的产品或系统价值实现最大化。
4. WSJF
规模化敏捷框架SAFe(Scaled Agile Framework)提出了一种定量计算法来评估需求的优先级,称为WSJF(Weighted Shortest Job First: 加权最短作业优先)。
计算公式如下:
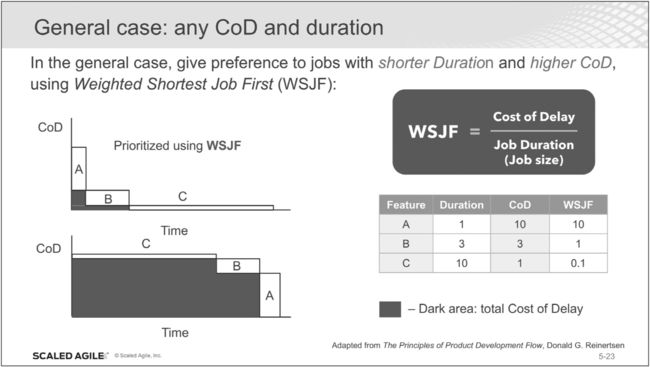
其中分母的工作规模部分大家比较熟悉,即估算的需求规模(故事点方法、理想时间方法等)。
分母部分的延期成本包括三个因子:
4.1. User and Business Value(用户和商业价值)
指的是对客户或商业的相对价值,比如:
用户更喜欢哪个?
对盈收有什么影响?
不做会产生什么潜在的负面影响?
4.2. Time Criticality(时间关键性)
指的是给用户的商业价值随着时间的推进如何变化。比如:
是否是固定交付日期类型的需求?
用户是否会愿意等待,还是会选择其他产品?
在某个时间窗口不上线的话,是否会影响用户的满意度?
4.3. Risk Reduction& Opportunity Enablement(减少风险或帮助获取新机会)
指的是除了上面的第1个和第2因子需要考虑因素之外,这个需求还能为业务带来哪些价值, 比如:
是否降低产品以后交付某些必要特性的风险?
是否会学到我们不知道的知识或信息?
是否会带来新的商业机会?
这样拆解后,WSJF的公式细化为:

如何操作呢?将所有特性列成表,如下:

对这个表中WSJF公式中的每个因子,采用与用户故事的故事点相对估算类似的方法做估算。比如,对于工作规模这一项,选择一个工作规模最小的特性作为基准,它的工作规模设为1(注意:WSJF公式中的每一项,都要选中一个特性作为相对估点的1),其他特性的工作规模与之相对比, 采用近似斐波那契数列1, 2,3, 5, 8,13, 20…为单位。如果特性A是基准特性的3倍,那么特性A的工作规模就是3。
为WSJF公式分子的其他因子做同样的相对估算法,即找到一个因子最小的基准特性,然后其他特性与之相比较,从而得到相应因子的估算数值。
就每一个特性,将WSJF的每个因子做相对估算后,就可以计算出每个特性的WSJF,这样你就得到了量化的需求排序。
常见疑惑:WSJF适用于所有需求的排序吗?
不是的。在SAFe里,WSJF可以适用于大粒度的Epic和Feature级需求,不适用于小颗粒的用户故事级需求,原因是用户故事通常很小,分母的几个因子不容易对比出差异。此外这种定量计算法在团队里应用过于沉重,因为需要对每个需求估算四个因子,不止是需求规模这一个因子,所有估算的耗时翻了四倍。
5. MoSCoW
MoSCoW法则是用来排定用户故事优先级顺序的一种定性方法。
具体这个缩写的含义是什么,具体怎么用,可以参考这篇文章:如何利用MoSCoW法则排定Sprint Backlog的优先级
6. SMART
SMART是用来将用户故事拆分为任务时的指导原则。
6.1. Specific(具体的)
任务必须是具体的。
6.2. Measurable(可以衡量的)
任务必须是可以衡量的。
6.3. Attainable(可达成的)
任务必须是可以达成的。
6.4. Relevant(相关的)
任务与最终目标是要相关的。
6.5. Time-bound(有时限的)
任务必须具有明确的截止期限。