需求
客户希望通过spark来分析二进制文件中0和1的数量以及占比。如果要分析的是目录,则针对目录下的每个文件单独进行分析。分析后的结果保存与被分析文件同名的日志文件中,内容包括0和1字符的数量与占比。
要求:如果值换算为二进制不足八位,则需要在左侧填充0。
可以在linux下查看二进制文件的内容。命令:
xxd –b –c 1 filename
-c 1是显示1列1个字符,-b是显示二进制
Python版本
代码
# This Python file uses the following encoding: utf-8
from __future__ import division
import os
import time
import sys
from pyspark import SparkConf, SparkContext
APP_NAME = "Load Bin Files"
def main(spark_context, path):
file_paths = fetch_files(path)
for file_path in file_paths:
outputs = analysis_file_content(spark_context, path + "/" + file_path)
print_outputs(outputs)
save_outputs(file_path, outputs)
def fetch_files(path):
if os.path.isfile(path):
return [path]
return os.listdir(path)
def analysis_file_content(spark_context, file_path):
data = spark_context.binaryRecords(file_path, 1)
records = data.flatMap(lambda d: list(bin(ord(d)).replace('0b', '').zfill(8)))
mapped_with_key = records.map(lambda d: ('0', 1) if d == '0' else ('1', 1))
result = mapped_with_key.reduceByKey(lambda x, y: x + y)
total = result.map(lambda r: r[1]).sum()
return result.map(lambda r: format_outputs(r, total)).collect()
def format_outputs(value_with_key, total):
tu = (value_with_key[0], value_with_key[1], value_with_key[1] / total * 100)
return "字符{0}的数量为{1}, 占比为{2:.2f}%".format(*tu)
def print_outputs(outputs):
for output in outputs:
print output
def save_outputs(file_path, outputs):
result_dir = "result"
if not os.path.exists(result_dir):
os.mkdir(result_dir)
output_file_name = "result/" + file_name_with_extension(file_path) + ".output"
with open(output_file_name, "a") as result_file:
for output in outputs:
result_file.write(output + "\n")
result_file.write("统计于{0}\n\n".format(format_logging_time()))
def format_logging_time():
return time.strftime('%Y-%m-%d %H:%m:%s', time.localtime(time.time()))
def file_name_with_extension(path):
last_index = path.rfind("/") + 1
length = len(path)
return path[last_index:length]
if __name__ == "__main__":
conf = SparkConf().setMaster("local[*]")
conf = conf.setAppName(APP_NAME)
sc = SparkContext(conf=conf)
if len(sys.argv) != 2:
print("请输入正确的文件或目录路径")
else:
main(sc, sys.argv[1])
核心逻辑都在analysis_file_content方法中。
运行
python是脚本文件,无需编译。不过运行的前提是要安装好pyspark。运行命令为:
./bin/spark-submit /Users/zhangyi/PycharmProjects/spark_binary_files_demo/parse_files_demo.py "files"
遇到的坑
开发环境的问题
要在spark下使用python,需要事先使用pip安装pyspark。结果安装总是失败。python的第三方库地址是https://pypi.python.org/simple/,在国内访问很慢。通过搜索问题,许多文章提到了国内的镜像库,例如豆瓣的库,结果安装时都提示找不到pyspark。
查看安装错误原因,并非不能访问该库,仅仅是访问较慢,下载了不到8%的时候就提示下载失败。这实际上是连接超时的原因。因而可以修改连接超时值。可以在~/.pip/pip.conf下增加:
[global]
timeout = 6000
虽然安装依然缓慢,但至少能保证pyspark安装完毕。但是在安装py4j时,又提示如下错误信息(安装环境为mac):
OSError: [Errno 1] Operation not permitted: '/System/Library/Frameworks/Python.framework/Versions/2.7/share'
即使这个安装方式是采用sudo,且在管理员身份下安装,仍然提示该错误。解决办法是执行如下安装:
pip install --upgrade pip
sudo pip install numpy --upgrade --ignore-installed
sudo pip install scipy --upgrade --ignore-installed
sudo pip install scikit-learn --upgrade --ignore-installed
然后再重新执行sudo pip install pyspark,安装正确。
字符编码的坑
在提示信息以及最后分析的结果中都包含了中文。运行代码时,会提示如下错误信息:
SyntaxError: Non-ASCII character '\xe5' in file /Users/zhangyi/PycharmProjects/spark_binary_files_demo/parse_files_demo.py on line 36, but no encoding declared; see http://python.org/dev/peps/pep-0263/ for details
需要在代码文件的首行添加如下编码声明:
# This Python file uses the following encoding: utf-8
SparkConf的坑
初始化SparkContext的代码如下所示:
conf = SparkConf().setMaster("local[*]")
conf = conf.setAppName(APP_NAME)
sc = SparkContext(conf)
结果报告运行错误:
Error initializing SparkContext.
org.apache.spark.SparkException: Could not parse Master URL: ''
根据错误提示,以为是Master的设置有问题,实际上是实例化SparkContext有问题。阅读代码,发现它的构造函数声明如下所示:
def __init__(self, master=None, appName=None, sparkHome=None, pyFiles=None,
environment=None, batchSize=0, serializer=PickleSerializer(), conf=None,
gateway=None, jsc=None, profiler_cls=BasicProfiler):
而前面的代码仅仅是简单的将conf传递给SparkContext构造函数,这就会导致Spark会将conf看做是master参数的值,即默认为第一个参数。所以这里要带名参数:
sc = SparkContext(conf = conf)
sys.argv的坑
我需要在使用spark-submit命令执行python脚本文件时,传入我需要分析的文件路径。与scala和java不同。scala的main函数参数argv实际上可以接受命令行传来的参数。python不能这样,只能使用sys模块来接收命令行参数,即sys.argv。
argv是一个list类型,当我们通过sys.argv获取传递进来的参数值时,一定要明白它会默认将spark-submit后要执行的python脚本文件路径作为第一个参数,而之后的参数则放在第二个。例如命令如下:
./bin/spark-submit /Users/zhangyi/PycharmProjects/spark_binary_files_demo/parse_files_demo.py "files"
则:
-
argv[0]: /Users/zhangyi/PycharmProjects/spark_binary_files_demo/parse_files_demo.py -
argv[1]: files
因此,我需要获得files文件夹名,就应该通过argv[1]来获得。
此外,由于argv是一个list,没有size属性,而应该通过len()方法来获得它的长度,且期待的长度为2。
整数参与除法的坑
在python 2.7中,如果直接对整数执行除法,结果为去掉小数。因此4 / 5得到的结果却是0。在python 3中,这种运算会自动转型为浮点型。
要解决这个问题,最简单的办法是导入一个现成的模块:
from __future__ import division
注意:这个import的声明应该放在所有import声明前面。
Scala版本
代码
package bigdata.demo
import java.io.File
import java.text.SimpleDateFormat
import java.util.Calendar
import com.google.common.io.{Files => GoogleFiles}
import org.apache.commons.io.Charsets
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Main {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("Binary Files").setMaster("local[*]")
val sc = new SparkContext(conf)
if (args.size != 1) {
println("请输入正确的文件或目录路径")
return
}
def analyseFileContent(filePath: String): RDD[String] = {
val data = sc.binaryRecords(filePath, 1)
val records = data.flatMap(x => x.flatMap(x => toBinaryStr(byteToShort(x)).toCharArray))
val mappedWithKey = records.map(i => if (i == '0') ('0', 1L) else ('1', 1L))
val result = mappedWithKey.reduceByKey(_ + _)
val sum = result.map(_._2).sum()
result.map { case (key, count) => formatOutput(key, count, sum)}
}
val path = args.head
val filePaths = fetchFiles(path)
filePaths.par.foreach { filePath =>
val outputs = analyseFileContent(filePath)
printOutputs(outputs)
saveOutputs(filePath, outputs)
}
}
private def byteToShort(b: Byte): Short =
if (b < 0) (b + 256).toShort else b.toShort
private def toBinaryStr(i: Short, digits: Int = 8): String =
String.format("%" + digits + "s", i.toBinaryString).replace(' ', '0')
private def printOutputs(outputs: RDD[String]): Unit = {
outputs.foreach(println)
}
private def saveOutputs(filePath: String, outputs: RDD[String]): Unit = {
val resultDir = new File("result")
if (!resultDir.exists()) resultDir.mkdir()
val resultFile = new File("result/" + getFileNameWithExtension(filePath) + ".output")
outputs.foreach(line => GoogleFiles.append(line + "\n", resultFile, Charsets.UTF_8))
GoogleFiles.append(s"统计于:${formatLoggingTime()}\n\n", resultFile, Charsets.UTF_8)
}
private def formatLoggingTime(): String = {
val formatter = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss")
formatter.format(Calendar.getInstance().getTime)
}
private def getFileNameWithExtension(filePath: String): String = {
filePath.substring(filePath.lastIndexOf("/") + 1)
}
private def fetchFiles(path: String): List[String] = {
val fileOrDirectory = new File(path)
fileOrDirectory.isFile match {
case true => List(path)
case false => fileOrDirectory.listFiles().filter(_.isFile).map(_.getPath).toList
}
}
private def formatPercent(number: Double): String = {
val percent = "%1.2f" format number * 100
s"${percent}%"
}
private def formatOutput(key: Char, count: Long, sum: Double): String = {
s"字符${key}的数量为${count}, 占比为${formatPercent(count/sum)}"
}
}
运行
通过sbt对代码进行编译、打包后,生成jar文件。然后在spark主目录下运行:
$SPARK_HOME/bin/spark-submit --class bigdata.demo.Main --master spark:// $SPARK_HOME/jars/binaryfilesstastistics_2.11-1.0.jar file:///share/spark-2.2.0-bin-hadoop2.7/derby.log
最后的参数"file:///share/spark-2.2.0-bin-hadoop2.7/derby.log"就是main函数接收的参数,即要分析的文件目录。如果为本地目录,需要指定文件协议file://,如果为HDFS目录,则指定协议hdfs://。
遇到的坑
byte类型的值
在Scala中,Byte类型为8位有符号补码整数。数值区间为 -128 到 127。倘若二进制值为11111111,通过SparkContext的binaryRecords()方法读进Byte数据后,其值为-1,而非255。原因就是补码的缘故。如果十进制为128,转换为Byte类型后,值为-128。
而对于-1,如果执行toBinaryString(),则得到的字符串为"11111111111111111111111111111111",而非我们期待的"11111111"。如下图所示:
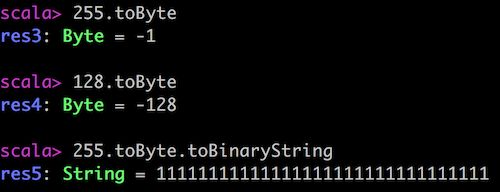
针对八位的二进制数值,可以编写一个方法,将Byte类型转为Short类型,然后再调用toBinaryString()方法转换为对应的二进制字符串。
private def byteToShort(b: Byte): Short =
if (b < 0) (b + 256).toShort else b.toShort
而对于不足八位的二进制数值,如果直接调用toBinaryString()方法,则二进制字符串将不到八位。可以利用String的format进行格式化:
private def toBinaryStr(i: Short, digits: Int = 8): String =
String.format("%" + digits + "s", i.toBinaryString).replace(' ', '0')
当然,可以将这两个方法定义为Byte与Short的隐式方法。