前言
scrapy是一个python的爬虫框架,开始接触的时间大概是6-21,项目完成是7-06 即是说从接触到能稍微使用一共花费了15天.期间还稍微接触了一下python3 urllib library, pySpider, 以及phantomJS.
这个项目主要是为了下载小电影:读取番号列表文件,通过scrapy从bt下载站上下载对应的bt链接,最后通过transmission-remote导入pi上的transmission进行下载.
一开始选择的爬取对象是 btso.pw,可是经验不足推测不出它的反爬虫策略,request中加入user-agent和referer也都一直返回403错误,只好换了一个网站 runbt 爬取,美中不足的是runbt的资源没有btso的多 :(
ps:
第二天我在偶然间看到知乎上一个差不多的问题最终解决了的爬取btso的问题,关键依然在于头部,头部的信息要完整才能获取数据 : D, 成功之后就因为爬取数据太快被封ip了...爬虫的水果然是很深啊
收获清单
- python2.x的一些语法:
scrapy框架使用的是python2.x
python2的编码问题: encode 与 decode
os 与 subprocess 库的使用
- 对scrapy框架的基本认知
- item, spider, pipeline, setting
- 网页结构分析:
chrome开发者工具的使用
基本的xpath写法
- 一些关于爬虫的知识
- 反反爬虫之request头部的伪装(user-agent, referer)
- 意外的收获
接触了python3的urllib library
一个文本浏览器phantomJS
参考资料
scrapy官方文档
阮一峰的xpath教程
爬虫与反爬虫
python2的中文编码问题
scrapy 爬取豆瓣实例:关注spider写法即可
transmission的操作文档
PhantomJS官网
配置开发环境
安装scrapy
具体步骤见scrapy官方文档
我遇到的问题
- 使用pip install softwareName会失败.
解决办法:
sudo -H pip install
参考capaj同志的回答 :
https://github.com/donnemartin/gitsome/issues/4
使用scrapy
- 注意返回类型
python2.7中,字符的处理是基于ascii字符的
所以如果使用f.write(s)写入一个unicode字符,程序会报错
#在python shell中运行
s = u'尼玛'
s
u'\u5c3c\u739b'
print(s)
尼玛
f.write(s)
#假设f是一个ifstream
#程序会报错
#此时应该使用encode('utf-8')
f.write(s.encode(utf-8))
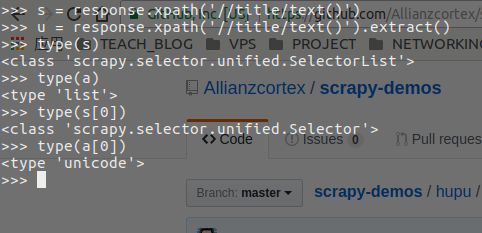
response.xpath('//title/text()').extract()
#返回的是包含字符串的 list
运行scrapy
在terminal终端中运行
scrapy -h 查看选项
info scrapy 查看详细使用手册
源代码
Link spider 代码
import scrapy
import os
path = './downloading/'
targetPath = './uncatch/'
urlPath = 'https://btso.pw/search/'
def getPhotoList():
temp = os.listdir(path)
photoList = []
for t in temp:
two = t.split('.')
photoList.append(two[0])
return photoList
class linksSpider(scrapy.Spider):
name = 'btso'
urls = getPhotoList()
headers = {
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding':'gzip, deflate, br',
'Accept-Language':'zh-CN,zh;q=0.8,ja;q=0.6,en;q=0.4',
'Cache-Control':'max-age=0',
'Connection':'keep-alive',
'Referer':'https://btso.pw/search/',
'Upgrade-Insecure-Requests':'1',
'User-Agent':'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36'
}
def start_requests(self):
for url in self.urls:
yield scrapy.Request(url=urlPath + url, headers = self.headers, callback=self.linksParse)
def linksParse(self, response):
s = response.xpath('//div[@class="container"]/div[@class="data-list"]/div[@class="row"]/a[1]/@href').extract()
with open('links.txt', 'a') as f:
temp = s.split('/')
f.write(temp[6] + '\n')
importLinks
# importLinks.py, 读取links.txt, 调用transmission-remote导入transmission
#!/usr/bin/python
# -*- coding: utf-8 -*-
import os
import subprocess
f = open('links.txt', 'r')
if (not f):
print("Magnet link dosen't exists")
exit()
list = f.readlines()
for l in list:
if (not l == '\n'):
temp = 'transmission-remote -a ' + l
subprocess.call(temp, shell=True)
f.close()
总结
这似乎是我第一个真正完成了的项目,改进的空间当然是大大的有,但至少成功的爬到了数据,也成功地导入了transmission下载.当然缺点也是有的:功能不够集成,操作有些繁复.
scrapy真的是很强,很多方面还没又涉及到,比如pipeline,middlewares.这些改进,就留到version2再说吧!