这几天,需要针对项目中的数据库处理部分进行详细设计,于是乎,恶补了一下数据设计的基础知识。网上内容多且杂,新手学习困难重重,不如顺着解决问题的过程,依次把数据库设计中涉及的基础知识、问题及解决办法整理成一个系列,真正的从入门到精通。
注明:为了方便,本文所指数据库均为关系型数据库。
数据库-基本概念
如果不开发,只是数据管理,那使用Excel就行,用不着数据库;如果只是开发无需数据保存的程序,那也用不上数据库,数据保存在内存里,进程关闭,内存中的数据也随之被释放了。
所以,当开发需要对数据进行存储及管理的程序时,才会使用到数据库(当然,也不一定,使用Excel/txt/xml/json有时候也可以满足需求,但是,这些文件未尝不是一种另类的“数据库”),所以,数据库,可以理解为一种数据的存储和管理工具。
百度百科给出的概念,云里雾里,简言之,数据库管理系统,一款针对数据库的应用程序,提供数据的增、删、改、查操作接口(命令行、可视化、Helper、ADO...),如果是程序员,而非DBA,数据库基本概念的理解,到此OK。后续,无非是对各类数据库基本配置、操作接口的熟悉和使用。
数据库-基本结构
关系型数据库中的数据均以二维表的形式存储,用户对数据进行操作也是基于二维表的操作,例如下图所示:

表里面有多个列,每个列表示这一类数据的属性,而黄色区域为一行,每一行对应该类数据的一个完整数据,也称为一个类的一个对象实例。和面向对象的概念对应起来,比较好理解。
对于这个表,通过DBMS即可进行可以进行增加、删除、修改、查询等操作,当然对应具体的数据库管理系统,又有可视化界面、命令行、编程接口等等方式。
SQL
SQL,又称为结构化查询语言,也可以说是操作和访问数据库的标准化计算机语言(引用W3School的解释)。
我们通过SQL语言操作数据库,有关SQL语言的学习,网上教程一堆堆,这里先做个引用,后续说明具体问题再详细说明。
基础款:http://www.phpstudy.net/e/sql/
进阶款:http://blog.jobbole.com/55086/
数据库-关系
如果数据库只是保存数据,数据和数据之间相互独立,那所有有关数据的处理就变的简单了,但是话又说回来,这样的数据本身也没有意义,因为没有关系,就意味着没有办法推断他的存在意义和实际含义,对于未知的数据,自然毫无意义。
既然如此,也可以反推而知,任何一个实体数据,既然存在,就不可避免的和其他数据实体之间存在关系。
拿PI君举例:
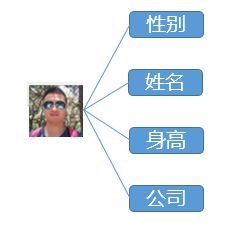
PI君是个纯爷们,所以咱有性别这个属性,那PI君和性别这个数据就有了关系,有点抽象,换个角度,PI君在一家公司上班,是这个公司的雇员,这个就是PI君这个数据实体和公司这个数据实体之间的关系描述。
但是,仅仅如此还不够,得证明PI君的忠诚度,PI只是一家公司的雇员,所以,如果你认识PI君,你就可以知道PI君所在公司的具体信息了,因为你知道PI君和公司的关系嘛。
OK,再换个角度,看下图:
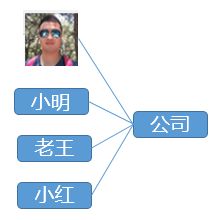
公司里有小明、老王、小红是和PI君一样的雇员,也就是说公司可以有多个和PI君类似的雇员,于是,我们顺其自然的扩大这个模型,如下图:
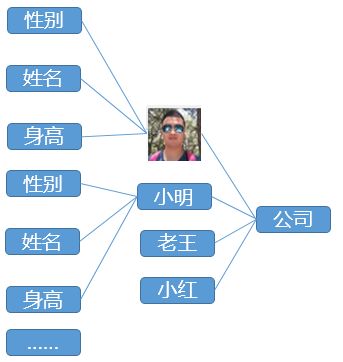
OK,数据通过关系建立成一个树状结构了,虽然有些重复的部分,不过总归还可以描述。
现在,做这样一个假设:小明和小红是一对夫妻、PI君因为努力工作被提拔为经理,而非和老王、小明及小红一样的雇员......诸如此类,如果我们继续用树来描述,或者升级为图,数据与数据之间复杂的关系,已经不能直观且简单获取了,怎么办!?身在这个复杂的社会,关系总是很复杂的嘛!
其次,如果PI君在微软或者Google上班(千万别信),公司雇员上千上万,那这个图将大的超乎想象。
所以只是简单的用树或者图来描述数据以及数据与数据之间的关系存在很多局限,只能小众适用,不能解决大部分数据相关的问题,So,有了关系型数据库,有了二维表结构,有了E-R模型~
E-R模型
解决通用性的不二法门就是抽象,这是PI君自己琢磨出来的,基于面向对象的思维方式,针对关系数据库的设计也是如此。
PI君,小明,老王和小红都是人,又都是公司雇员,所以他们其实是"公司雇员"这个抽象的实例。OK!原理不难理解,那有没有通用的分析模式呢?当然有,就是ER实体关系模型。
其中,实体就是PI君、小明、老王、小红、公司之类,关系就是PI君、小明、老王、小红都是公司的雇员,行话来说就是公司:雇员 = 1:N。于此类似,还有1对1、多对多的关系。

对于这些模型以及模型之间关系的抽象和描述,E-R模型给出了很棒的分析方法,E-R概念很好理解,直接百度百科或者维基百科就好:
http://www.cnblogs.com/samwu/archive/2011/09/07/2169842.html
数据库表
数据库表是数据库数据管理的基本单元,换句话说,关系数据库中的数据都是以二维表的形式存储的。这个表可以理解为C#里的纯数据类(没有方法)。例如本篇一开始的那张图,就是一个数据库表。
表的主键(Prime Key)
如果PI君的媳妇儿来公司找PI君,到了前台,假如她这么问:“我要找一个男人,他身高**米,体重**kg,年纪**岁,是你们公司的雇员,他叫PI。”,前台妹妹很郁闷,她跑遍整个公司大楼,挨个部门敲门或者打电话的找,最后竟然找到15个和PI君媳妇描述符合的人,好吧,这下子麻烦大了……
如果不是PI君媳妇认出了PI君独一无二的鞋拔子脸,估计这次就空跑一趟了…
但是,假如还有一个符合描述且和PI一样的鞋拔子脸呢?
又或者,PI君媳妇这次时间紧张,一分钟以后见不到PI君就离婚~~~~咋办啊?!
前台妹妹说:“你把PI君的电话或工号告诉我嘛,这样就可以直接电话他或定位他的部门啦~”OK,故事讲到这里,有关数据库表的主键就很好理解啦,主键是数据库表中每一个实例的唯一标识,有了一个唯一标识,可以极快的找到对应的实例,而且是唯一的实例。
那换个角度问一句,每个表都必须有主键吗?当然不用,至于为什么,见仁见智啦,请看官们自己思考下~
另一个问题,主键最多只有一个?Yes,主键只能有一个,如果想给一个表提供更精准的查询索引,OK,可以设置一个表的多列为索引,索引不是主键,注意二者的区别。
表的外键(Foreign Key)
除了主键,还有另外一个概念:外键。
同样以公司和雇员为例,PI君 ,小明,老王和小红都是公司的雇员,但是,PI君和小明是Google公司的,老王和小红是微软公司的,现在有两个表来描述这些数据实体,如下图:
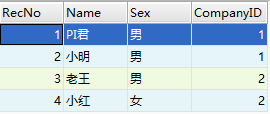
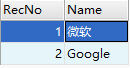
注:两个表中的RecNo分别是各自表的主键。
没有外键的情况下,如上图所示的描述看似OK,不过假如此时,Google公司把微软收购了,现在Company表中只有一个数据实例,也就是Google,微软被删除了,微软得通知原微软雇员老王和小红更改自己的CompanyID,可是,Company中已经没有了微软这个数据实例,现有的Google也不知道自己有哪些雇员,于是,老王和小红的CompanyID成了不存在的数据,二人百口莫辩,身份可疑~
分析下微软被Google收购的过程,单独描述,Google收购微软,很简单,在Company表中删除微软即可,但是”老王/小红是微软的雇员“这两个关系的描述却没有被处理,甚至没有被有效的描述,通过老王/小红知道二位是微软雇员,但是通过微软,并不知道有老王/小红这两个雇员,所以在微软被收购以后,就没法去处理原本应该与之关联的雇员们。
所以,为了保持数据的一致性和完整性,数据库中除了对数据进行描述,同时还要描述关系,关系的描述/区分/识别,使用的就是外键。
外键,全称为外关键字(Foreign Key)
如果公共关键字在一个关系中是主关键字,那么这个公共关键字被称为另一个关系的外关键字。由此可见,外关键字表示了两个关系之间的联系。以另一个关系的外关键字作主关键字(主键)的表被称为主表,具有此外关键字的表被称为主表的从表。外关键字又称作外键。
继续举例说明:Company-Employee存在一种雇佣关系,及一个雇员必然属于某一个公司,一个公司必然包含不少于一个雇员,所以Employ中的CompanyID就是这段关系的主键,是Emloyee表的外键,对应于Company表的ID属性,所以这段关系中Company是主表,而Employee是从表。
概念上理解以后,保持数据完整性的措施就很好理解了,如果微软被收购,首先必须根据雇佣关系找到他的雇员,要么解雇,然后被谷歌收购,要么不允许被收购,至于实现方式是多样的,顺势说下数据库完整性的概念。
数据库完整性
数据库完整性,也就是数据完整性,包含多个角度的概念(网上又不少对这个东西的说明,但是真正理解透彻的,说的一般人能明白的不多,以下内容结合了网上学习的内容和PI君自己的理解,旨在深刻理解概念,明白设计的理由,从而在实际的数据库设计工作中不人云亦云,有自己的见解。)
实体完整性(Entity Integrity)、域完整性(Domain Integrity)、参照完整性(Referential Integrity)、用户定义的完整性(User-definedIntegrity)
实体完整性:实体完整性要求每一个表中的主键字段都不能为空或者重复的值;
域完整:域完整性指列的值域的完整性,如数据类型、格式、值域范围、是否允许空值等,域完整性限制了某些属性中出现的值,把属性限制在一个有限的集合中。例如,如果属性类型是整数,那么它就不能是101.5或任何非整数。
参照完整性:当更新、删除、插入一个表中的数据时,通过参照引用相互关联的另一个表中的数据,来检查对表的数据操作是否正确。参照的完整性要求关系中不允许引用不存在的实体。
→→→如果在学生表和选修课之间用学号建立关联,学生表是主表,选修课是从表,那么,在向从表中输入一条新记录时,系统要检查新记录的学号是否在主表中已存在,如果存在,则允许执行输入操作,否则拒绝输入,这就是参照完整性。
→→→参照完整性还体现在对主表中的删除和更新操作,例如,如果删除主表中的一条记录,则从表中凡是外键的值与主表的主键值相同的记录也会被同时删除,将此称为级联删除;如果修改主表中主关键字的值,则从表中相应记录的外键值也随之被修改,将此称为级联更新。
用户定义的完整性:可以理解为域完整性。
注:完整性概念的理解参考:http://blog.csdn.net/zm_21/article/details/8101974
保持数据完整性,需要用到SQL语句中的规则/约束/级联更新/级联删除(并不是所有数据库软件提供商都支持,开发人员需特别注意),接下来依次给出例子来说明,例子使用的是MySQL,其他版本的数据库在描述时或有不同,注意甄别:
规则(Rule):
create rule _employee_sex_rule_ as @Sex in ('男','女') //创建规则,Sex属性只能取值“男”或“女”
exec sp_helptext _employee_sex_rule_ //使用存储过程sp_helptext查看“_employee_sex_rule_”规则
exec sp_bindrule _employee_sex_rule_, 'Employee.[Sex] '//使用存储过程sp_bindrule绑定规则至Employee表的Sex列
exec sp_unbindrule _employee_sex_rule_, 'Employee.[Sex] '//使用存储过程sp_unbindrule接触绑定规则至Employee表的Sex列
drop rule _employee_sex_rule_ //删除规则
约束(Check):
creat table Employee(ID int NOT NULL,Sex varchar(255) NOT NULL,Name varchar(255) NOT NULL,CompanyID foreignkey(ID) referencesUserInfo(ID), check(Sex in ('男','女'))) //创建表时定义约束
ALTER TABLE Employee add check(Sex in ('男','女') //对已有表添加约束
级联删除/级联更新:
creat table Employee(ID int NOT NULL,Sex varchar(255) NOT NULL,Name varchar(255) NOT NULL,CompanyID foreignkey(ID) referencesUserInfo(ID) on delete cascade /on update cascade)
数据库一致性
数据库一致性,也就是数据一致性,对于关系数据库而言,可以这么理解:以Employee数据表为例,有一天PI君老妈通过算命先生,觉得PI君这个名字起的不好,找到PI君以后,就带着PI君去派出所给PI君改名为PIPI君,同时,PI君媳妇正在保险公司给PI君买保险,因为IT行业风险高嘛,动不动加班猝死之类的,在填写担保人时,用的是“PI君”这个名字,毕竟PI君老妈给PI君改名的时候,PI君媳妇是不知情的。果然有一天,PI君真的悲剧了,保险公司核对保单发现,没有PI君这个人,只有PIPI君,好嘛,麻烦大了......
所以,怎么保证PI君的个人信息在被任何用户获取或使用时,始终都只有一个版本呢?这个问题就是数据库一致性需要研究的问题。
保证数据一致性的措施主要是事务机制,以及对数据访问的并发控制,看下文↓↓↓↓↓。
并发控制
并发控制,其实就是在多个用户同时或者重叠时段内访问同一数据资源时(比如PI君),对访问的过程进行控制,防止出现违反数据一致性要求的行为。
扩展下,有哪些违反数据一致性的情况呢?
① 丢失修改,简单说PI君老妈给PI君改名为PIPI君,PI君媳妇不知道,在给PI君买保险的时候,特指PI君的名字对应PI君的身份证,并给派出所去电,确认PI君就是身份证上的PI君,派出所说一个身份证只能有一个名字,结果PI君的新名字PIPI君直接失效;
② 数据不能重现,继续拿PI君的例子说事儿,PI君老妈给PI君改名为PIPI君,PI君媳妇儿给PI君买保险,投保的时候姓名是“PI君”,PI悲剧那天兑保的时候却查不到“PI君”这个姓名;
③ 脏数据,PI君老妈给PI君改名为PIPI君,并通过联网发布该信息,PI君媳妇儿给PI君买保险,投保的时候姓名是“PIPI君”,但是那天派出所数据库被黑客黑掉,当天更新数据丢失,只能恢复至前一天,所以PIPI君又恢复姓名为“PI君”,于是投保的那个“PIPI君”就成了不存在的人,也就是脏数据。
并发控制的实现方式有多种,主流的就是封锁和时间戳,封锁机制类似于多线程问题的处理(都是共享资源的访问控制),也是最常用的并发控制技术,这里进行简单的介绍:
在多线程开发的时候,如果想访问一个共享资源,担心出现并发访问异常,一般先Lock该资源,处理完成后再UnLock,对于数据库,道理是一样的,不过针对数据的特性,又分为两类锁:读锁和写锁,又因为读的时候大家都可以读,只要不修改数据,并不影响数据一致性,所以读锁也叫共享锁(其实,专业的讲,先有共享锁ShareLocks,简称S锁);但是写的时候,其他人就不能再读了或者写了,不然就会有数据不一致的情况发生,所以这个锁也叫排他锁,也就是Exclusive Locks,简称X锁。
并发控制的时候,任何用户想访问数据资源,先加锁,加锁成功以后才能访问,加锁怎么着才能成功就是访问控制的逻辑,也就是常说的DBMS封锁协议,PI君做了简单的归纳:
① 如果一个用户想访问一个数据资源,首先必须给该资源加锁,加锁成功后才能对该资源进行访问,加S锁,只能读取该资源,加X锁则可以读和修改;
② 如果一个数据资源被加了X锁,那么除了加锁的用户具备对该数据资源的访问及操作权限,其他用户再给该资源加锁(X或S锁),都只能等待,直至该资源被解锁;
③ 如果一个数据资源被加了S锁,那么加锁用户可以访问该资源,但是不能修改,其他用户可以给该资源加S锁,但是添加X锁则只能等待,直至该资源上的所有S锁均被解除。
当然,在实际的数据库版本中,并不完全遵照这个协议,比如MySQL,采用多版本的并发控制,读取数据的时候是不加锁的,因为读的是历史版本,不存在修改和删除,所以保障了效率的同时还保障了数据的一致性,这里不展开,有兴趣的可以读读云创大数据的这篇技术博文:
http://www.cstor.cn/textdetail_7953.html
并发控制,继续展开的内容包括死锁、活锁、死锁解除、并行调度、串行调度,但是,对于普通程序员,而非DBA,了解自此,也算OK,所以在本篇博文,不再展开,后续PI君会单独针对并发控制整理一篇博文,敬请期待吧~
事务
对于事务的理解可以参考程序语言中的函数概念,是一个工作单元。举个例子,还是公司和雇员的例子,假如因为项目需要,Google和微软商量进行技术人员的互换,很不幸,Google的PI君和微软的老王成了互换的对象,首先,Employee表中PI君的CompanyID更改为微软的ID,下一步,老王的CompanyID更改的Google的ID,完成后这个互换工作结束。
但是,假设在PI君换至微软以后,微软忽然改主意了,不打算把老王换回来了,咋办呢?通常而言,如果互换工作不能进行,应该将数据恢复至互换之前的状态,提供这种机制或功能的东东就是事务。
所谓事务,就是用户自定义的一个数据库操作序列,这些操作要么全做,要么全不做,是一个不可分割的工作单元,在关系数据库中,事务可以是一条Sql语句、一组Sql语句或整个程序。
在实际应用中,可以通过ADO提供的Connection和Transaction对象来进行事务的控制,具体参看:
http://www.cnblogs.com/chinafine/archive/2010/02/27/1674759.html
存储过程
触发器
关联查询
ADO
ORM
未完待续~